Автор: Денис Аветисян
Новый подход позволяет значительно ускорить работу больших моделей, снижая затраты на обучение и ресурсы для вычислений.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал![Метод FineGates обеспечивает структурированную разреженность при дообучении языковых моделей, используя легковесные векторы управления строками и столбцами [latex]\bm{\omega}_{c}, \bm{\omega}_{r}[/latex], которые выборочно сохраняют наиболее информативные весовые измерения, тем самым оптимизируя процесс разрежения и обновление смещений напрямую, что снижает накладные расходы памяти и время вывода без ущерба для производительности, в отличие от LoRA и других PEFT-методов, использующих дополнительные обучаемые матрицы.](https://arxiv.org/html/2602.09169v1/imgs/illustration.png)
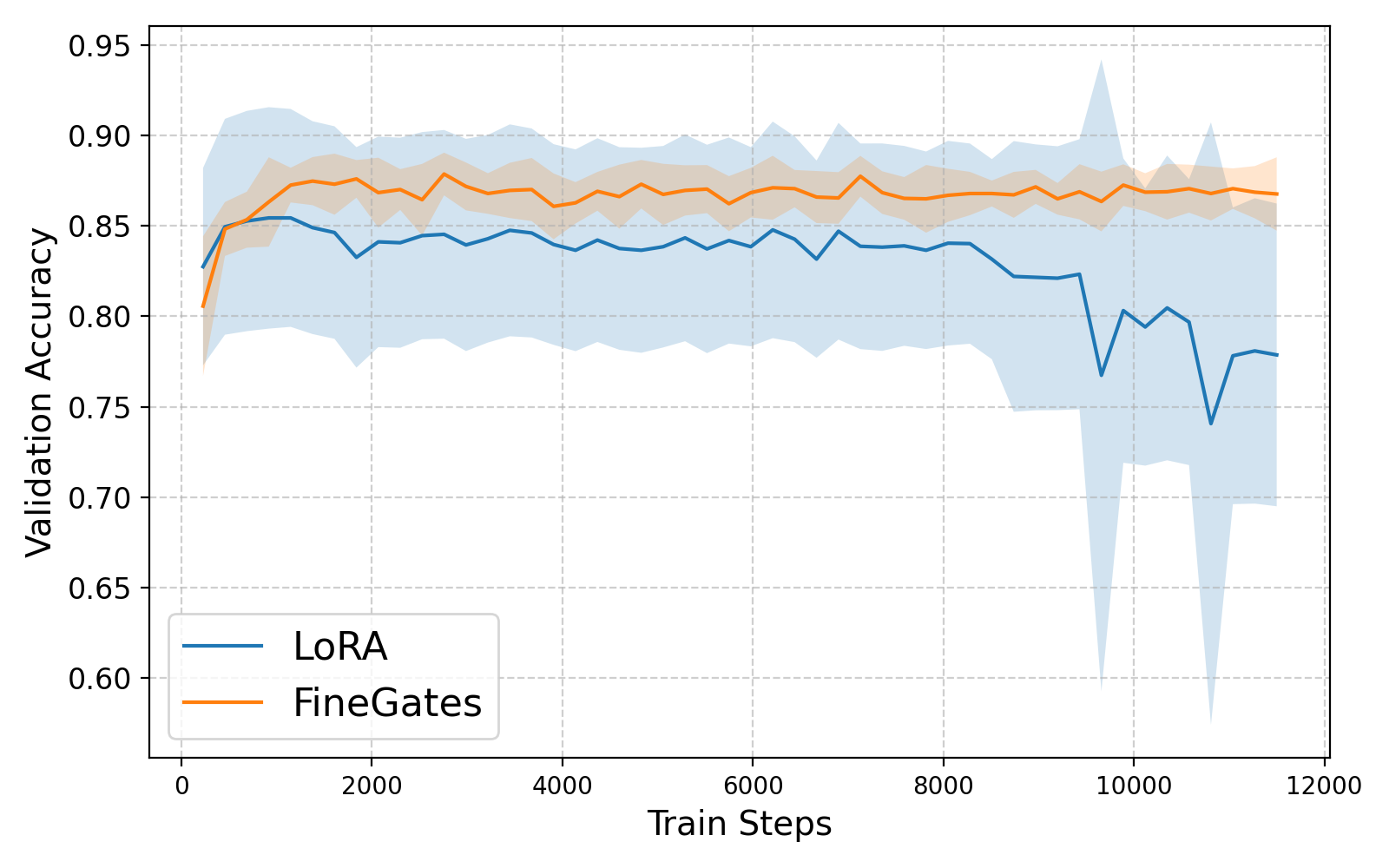
В статье представлен метод FineGates, использующий структурированную разреженность и бинарные вентили для эффективной адаптации и сжатия фундаментальных моделей.
Полное обучение больших языковых моделей с миллиардами параметров часто непрактично из-за высоких вычислительных затрат и риска переобучения. В работе ‘Train Less, Infer Faster: Efficient Model Finetuning and Compression via Structured Sparsity’ предложен метод FineGates, демонстрирующий, что разрежение определенных строк и столбцов модели позволяет эффективно адаптировать ее к новым задачам без необходимости настройки весов. Ключевым результатом является возможность снизить количество параметров модели на 20-40% и ускорить процесс инференса, используя обучаемые бинарные векторы для активации разреженного подмножества весов. Может ли структурированное разрежение стать основой для создания более компактных и эффективных языковых моделей, сохраняя при этом высокую точность?
Вызов масштаба: Ограничения фундаментальных моделей
Современные фундаментальные языковые модели, такие как GPT-3 и аналогичные, демонстрируют впечатляющие возможности в генерации текста, переводе и понимании языка. Однако, эта выдающаяся производительность достигается ценой огромных вычислительных ресурсов. Размер этих моделей, исчисляемый миллиардами параметров, требует значительных затрат энергии и дорогостоящего оборудования для обучения и развертывания. С увеличением масштаба моделей, потребность в вычислительной мощности растет экспоненциально, что создает серьезные препятствия для широкого доступа к этим технологиям и ограничивает возможности их использования в реальном времени или на устройствах с ограниченными ресурсами. Таким образом, проблема масштабируемости становится ключевым вызовом для дальнейшего развития и практического применения фундаментальных языковых моделей.
Традиционные методы дообучения больших языковых моделей зачастую требуют обновления миллиардов параметров, что делает процесс крайне ресурсоемким и медленным. Каждый параметр представляет собой число, которое необходимо скорректировать для адаптации модели к конкретной задаче, и масштабы этих моделей — десятки и сотни миллиардов параметров — означают, что даже небольшие изменения требуют колоссальных вычислительных мощностей и времени. Это связано с тем, что необходимо не только вычислить градиенты для каждого параметра, но и сохранить и обновить все эти значения в памяти, что существенно ограничивает возможности быстрого и эффективного развертывания моделей для решения узкоспециализированных задач и препятствует широкому доступу к передовым технологиям обработки естественного языка.
Ограничения, связанные с огромным размером и вычислительной сложностью фундаментальных языковых моделей, существенно затрудняют их широкое внедрение и быструю адаптацию к конкретным задачам. Необходимость обновления миллиардов параметров при традиционной тонкой настройке требует значительных ресурсов и времени, что делает процесс недоступным для многих исследователей и организаций. Это препятствует быстрому прогрессу в узкоспециализированных областях, где требуется быстрая адаптация модели к новым данным и задачам. В связи с этим, возрастает потребность в разработке более эффективных методов, позволяющих снизить вычислительные затраты и обеспечить более быстрый и доступный процесс адаптации моделей к специализированным задачам, открывая возможности для более широкого применения искусственного интеллекта.
Параметрически-эффективная тонкая настройка: Спектр подходов
В последние годы появилось множество методов параметрически-эффективной донастройки (PEFT), включая LoRA-XS, VeRA, BitFit и RoCoFT1-Row. Каждый из этих подходов обладает своими специфическими преимуществами и компромиссами в отношении эффективности, производительности и требований к вычислительным ресурсам. Например, LoRA-XS характеризуется экстремально низким числом обучаемых параметров, что обеспечивает высокую скорость и экономию памяти, в то время как VeRA фокусируется на оптимизации ранга адаптеров для достижения лучшего баланса между производительностью и эффективностью. BitFit, напротив, ограничивает обучение только параметрами смещения, что делает его особенно простым в реализации, но может ограничивать выразительность модели. RoCoFT1-Row оптимизирует обучение только одной строкой весов в каждом слое, обеспечивая существенное сокращение количества обучаемых параметров, при этом сохраняя достаточно высокую производительность.
Большинство методов параметро-эффективной тонкой настройки (PEFT) характеризуются тем, что обучается лишь небольшое количество параметров, в то время как основная часть весов предварительно обученной модели остается неизменной (замороженной). Это позволяет значительно сократить вычислительные затраты и объем необходимой памяти для адаптации модели к конкретной задаче, поскольку градиенты вычисляются и обновляются только для небольшого подмножества параметров. Сохранение большей части модели в неизменном состоянии также способствует сохранению общих знаний, полученных в процессе предварительного обучения, и снижает риск переобучения на ограниченном наборе данных для тонкой настройки.
Адаптерные методы, такие как VeLoRA и APT, представляют собой усовершенствование подхода эффективной тонкой настройки, заключающееся в добавлении к существующей архитектуре базовой модели небольших, обучаемых модулей. Эти модули, как правило, состоят из нескольких слоев полносвязных или сверточных операций и внедряются в различные точки модели, например, после слоев внимания или прямого распространения. В отличие от методов, напрямую модифицирующих веса базовой модели, адаптеры позволяют сохранить исходные веса неизменными, что упрощает переключение между различными задачами и снижает потребность в хранении нескольких полных копий модели. Обучаются только параметры адаптеров, что значительно сокращает вычислительные затраты и требования к памяти по сравнению с полной тонкой настройкой.
FineGates: Использование разреженности для адаптивной эффективности
Метод FineGates представляет собой новый подход к повышению эффективности адаптации моделей, сочетающий в себе структурированную разреженность и механизм управления (gating). В основе лежит идея выборочной активации подмножества существующих весов модели посредством бинарных масок, что позволяет снизить вычислительные затраты без значительной потери производительности. Структурированная разреженность обеспечивает регулярность и упрощает реализацию, а механизм управления динамически определяет, какие веса активировать для конкретного входного сигнала, обеспечивая адаптацию к различным задачам и данным. Такой комбинированный подход позволяет достичь более высокой эффективности по сравнению с традиционными методами разреженности или адаптации.
Механизм FineGates использует бинарные маскировочные векторы для выборочной активации разреженного подмножества существующих весов модели. Каждый элемент маскировочного вектора представляет собой бинарное значение (0 или 1), определяющее, будет ли соответствующий вес участвовать в вычислениях. Применение этих масок позволяет эффективно обнулить большую часть весов, снижая тем самым вычислительную сложность и потребление памяти во время инференса. Такая селективная активация весов позволяет сохранить только наиболее важные параметры, необходимые для выполнения задачи, что приводит к снижению вычислительных затрат без существенной потери точности модели.
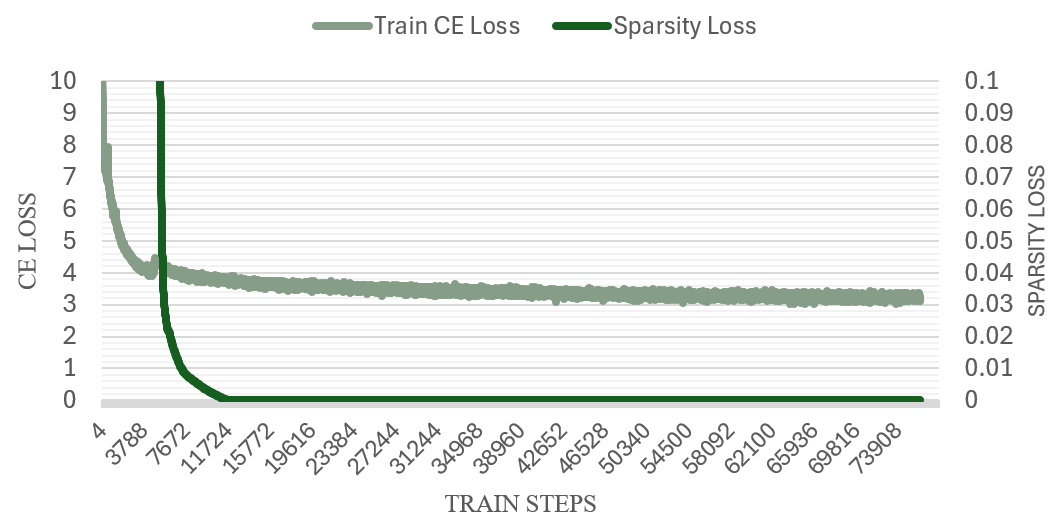
Метод FineGates использует условие Поляка-Лояшевича (PL) для гарантии сходимости процесса обучения. Условие PL, гласящее, что функция потерь является сильно выпуклой в окрестности оптимальной точки, обеспечивает, что алгоритм оптимизации будет сходиться к локальному минимуму. Для предварительного обучения модели используется датасет C4 — обширный корпус текстов, содержащий около 750 миллионов предложений, что позволяет модели приобрести широкие языковые знания и улучшить обобщающую способность перед применением разреженности и механизма выбора весов. Использование C4 в качестве предварительно обученного корпуса позволяет добиться лучшей производительности при последующей адаптации модели.
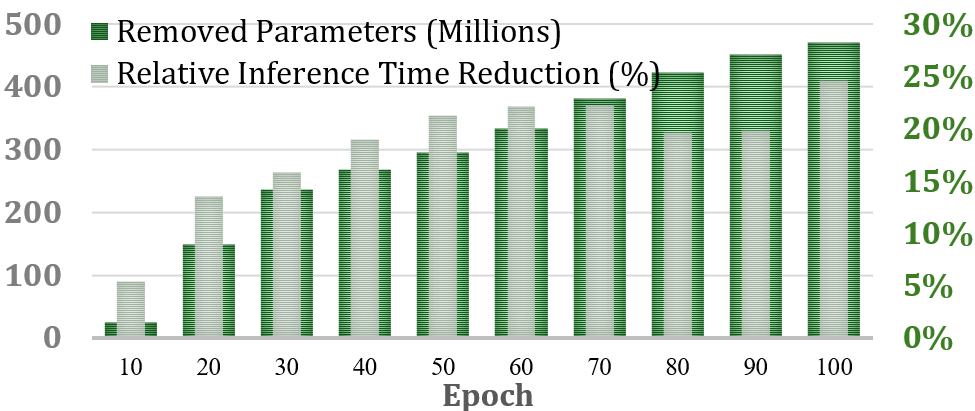
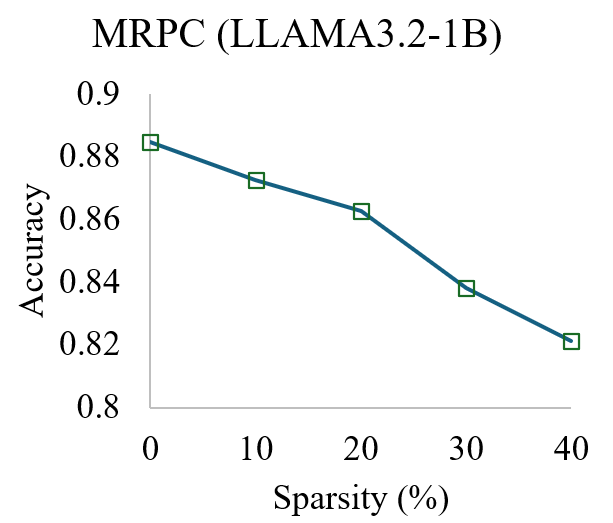
Внедрение целевой активации в сочетании со структурированной разреженностью демонстрирует повышение эффективности инференса. Эксперименты показали возможность снижения количества параметров модели до 40% с незначительной потерей производительности. В частности, на задаче MRPC (Multi-Sentence Reading Comprehension) зафиксировано сокращение времени инференса на 25%. Данный подход позволяет оптимизировать вычислительные затраты без существенного влияния на точность модели, что делает его перспективным для развертывания в условиях ограниченных ресурсов.
За пределами адаптации: Обрезка и будущее эффективности
Методы, такие как MaskLLM, выводят оптимизацию больших языковых моделей на новый уровень, применяя полуструктурированную обрезку. В отличие от традиционных подходов, которые удаляют параметры случайным образом, MaskLLM анализирует структуру модели и идентифицирует наименее значимые веса, что позволяет существенно сократить размер модели без критической потери производительности. Этот процесс, имитирующий естественный отбор в биологических системах, позволяет удалять избыточные параметры, сохраняя при этом ключевые знания, накопленные моделью в процессе обучения. В результате, модель становится более компактной, требует меньше вычислительных ресурсов и быстрее обрабатывает запросы, что делает её более пригодной для развертывания на устройствах с ограниченными ресурсами и для обслуживания большого количества пользователей.
Значительное уменьшение размера языковых моделей, несмотря на потенциальное влияние на точность, приводит к существенному повышению эффективности инференса. Сокращение количества параметров позволяет снизить вычислительные затраты и потребление памяти, что особенно важно при развертывании моделей на устройствах с ограниченными ресурсами или при обработке больших объемов данных. Это достигается за счет удаления избыточных или малозначимых связей в нейронной сети, что позволяет модели выполнять задачи быстрее и эффективнее, сохраняя при этом приемлемый уровень производительности. В результате, агрессивное сжатие моделей становится ключевым фактором для создания более доступных и масштабируемых решений в области обработки естественного языка.
Сочетание параметрически-эффективной тонкой настройки и обрезки моделей представляет собой перспективный подход к созданию высокоадаптируемых и легко развертываемых языковых моделей. Данная парадигма позволяет значительно уменьшить вычислительные затраты и размер моделей, сохраняя при этом их способность к обучению и обобщению. Вместо того, чтобы обучать все параметры огромной модели с нуля, параметрически-эффективные методы фокусируются на обучении лишь небольшого подмножества, что снижает требования к ресурсам. Последующая обрезка, удаляющая избыточные параметры, дополнительно оптимизирует модель, делая её более компактной и быстрой, не жертвуя при этом значительной частью её производительности. Такой симбиоз обеспечивает гибкость в адаптации к различным задачам и возможность развертывания моделей на устройствах с ограниченными ресурсами, открывая новые возможности для широкого спектра приложений.
Исследования показали, что метод FineGates способен значительно уменьшить размер языковых моделей, таких как Llama-3.2-1B, удаляя до 470 миллионов параметров при этом сохраняя лишь незначительное снижение точности — всего 6%. Этот подход основан на удалении промежуточных и выходных проекций, что позволяет сократить количество обучаемых параметров до четырех раз. Фактически, FineGates демонстрирует возможность создания более компактных и эффективных моделей без существенной потери в качестве, открывая новые перспективы для развертывания сложных языковых систем на устройствах с ограниченными ресурсами и снижения вычислительных затрат.
Исследование, представленное в данной работе, демонстрирует стремление к математической чистоте в области машинного обучения. Авторы предлагают метод FineGates, направленный на эффективную адаптацию и сжатие фундаментальных моделей посредством структурированной разреженности. Это напоминает о словах Андрея Николаевича Колмогорова: «Математика — это искусство доказательства». Ведь именно доказательство корректности и эффективности алгоритма, а не просто его работа на тестовых данных, является истинной целью. FineGates, избирая подмножество весов для активации, стремится к элегантности решения, доказуемой с точки зрения уменьшения параметров и сохранения производительности. Разреженность, как и элегантное математическое доказательство, позволяет увидеть суть, отбросив лишнее.
Что Дальше?
Представленная работа демонстрирует элегантность подхода к разрежению моделей, основанного на структурированных вентилях. Однако, пусть N стремится к бесконечности — что останется устойчивым? Утверждение о скорости вывода, безусловно, привлекательно, но истинная проверка — это масштабируемость. Насколько эффективно FineGates будет работать с моделями, содержащими сотни миллиардов параметров, и при этом сохранять предсказуемую производительность на разнообразных задачах? Простое уменьшение числа параметров — недостаточно; важна гарантия сохранения обобщающей способности.
Очевидным направлением для дальнейших исследований является исследование теоретических границ разреженности, достижимых с помощью подобных методов. Какова минимальная плотность весов, необходимая для достижения определенного уровня точности? Более того, необходимо рассмотреть взаимодействие между структурированной разреженностью и другими методами сжатия, такими как квантизация и прунинг. И, конечно, вопрос об адаптации к динамическим данным — сможет ли FineGates эффективно перестраиваться в условиях изменяющихся входных потоков, не теряя при этом преимуществ в скорости и эффективности?
В конечном счете, успех подобных подходов будет зависеть не только от демонстрации улучшенных результатов на стандартных бенчмарках, но и от создания надежной теоретической базы, позволяющей предсказывать и контролировать поведение разреженных моделей в различных условиях. Просто “работает на тестах” — недостаточно. Требуется доказательство.
Оригинал статьи: https://arxiv.org/pdf/2602.09169.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Серебро прогноз
- Российский рынок: Нефть, дивиденды и геополитика. Что ждет инвесторов? (23.03.2026 18:32)
- Ормузский тупик и DeFi-волатильность: анализ рисков и возможностей для инвесторов (11.04.2026 09:15)
- ЭсЭфАй акции прогноз. Цена SFIN
- Palantir: К удивлению в 2026-м?
- РУСАЛ акции прогноз. Цена RUAL
- Прогноз нефти
- Будущее лайткоина: прогноз цен на криптовалюту LTC
- Стоит ли покупать доллары за юани сейчас или подождать?
2026-02-12 03:20