Автор: Денис Аветисян
Представлена модель UBio-MolFM, объединяющая машинное обучение и молекулярную динамику для точного и эффективного моделирования сложных биологических систем.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал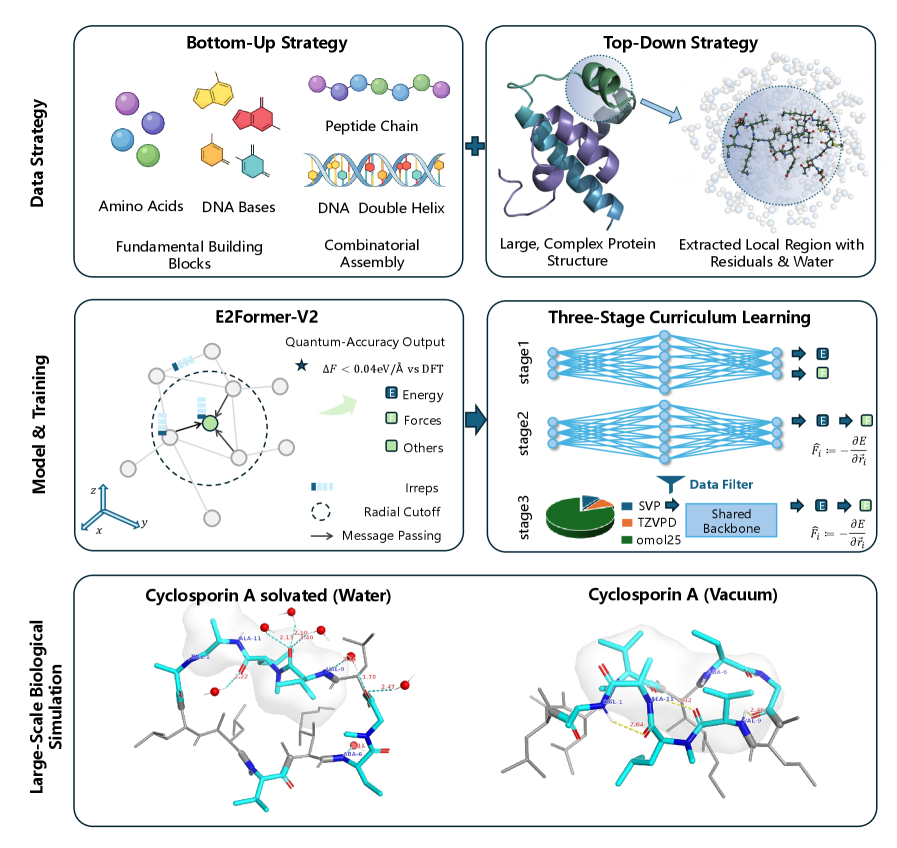
Разработан универсальный фундамент модели для биосистем, использующий эквивариантные нейронные сети и масштабный набор данных.
Молекулярное моделирование, являясь ключевым инструментом для понимания биологических процессов, сталкивается с фундаментальным компромиссом между точностью квантово-механических расчетов и масштабируемостью для систем биологического размера. В данной работе представлена платформа UBio-MolFM: A Universal Molecular Foundation Model for Bio-Systems, объединяющая крупномасштабный биомолекулярный набор данных, линейно-масштабируемую архитектуру эквивариантного трансформера и многоэтапную стратегию обучения для достижения высокой точности и эффективности моделирования. Разработанный подход демонстрирует ab initio-уровень точности для сложных биомолекулярных систем, открывая новые возможности для вычислительной биологии. Сможем ли мы с помощью подобных моделей создать цифрового двойника жизни и предсказывать поведение биологических систем с беспрецедентной точностью?
Молекулярное Моделирование: Преодолевая Сложность Биологических Систем
Традиционные методы молекулярного моделирования, несмотря на свою значимость, сталкиваются с существенными трудностями при изучении биологических систем из-за их невероятной сложности и масштаба. Попытки симулировать взаимодействие тысяч молекул, учитывая конформационные изменения, электростатические взаимодействия и динамику растворителей, часто приводят к вычислительным ограничениям и упрощениям, снижающим точность предсказаний. Неспособность адекватно отразить всю сложность биологических процессов, таких как сворачивание белков или взаимодействие лекарственных средств с мишенями, ограничивает возможности in silico исследований и разработки новых терапевтических средств. В результате, предсказания, основанные на этих моделях, нуждаются в тщательной экспериментальной проверке, что замедляет прогресс в понимании фундаментальных биологических механизмов и создании эффективных лекарств.
Несмотря на впечатляющую производительность, существующие фундаментальные модели, разработанные для обработки широкого спектра данных, часто демонстрируют недостаточную точность применительно к биологическим задачам. Обученные преимущественно на общих корпусах текстов и изображений, они лишены специфических знаний о сложных молекулярных взаимодействиях, динамике белков и тонкостях геномных данных. Это приводит к ошибкам при прогнозировании структуры белков, идентификации лекарственных целей и моделировании клеточных процессов. В результате, применение универсальных моделей в биологических исследованиях требует значительной адаптации и часто не позволяет достичь необходимой степени достоверности, подчеркивая потребность в создании специализированных моделей, обученных на релевантных биологических данных.
Необходимость создания специализированных базовых моделей для биологических систем обусловлена потребностью в преодолении ограничений традиционного молекулярного моделирования и универсальных моделей искусственного интеллекта. Эти новые модели должны опираться на обширные, релевантные биологические наборы данных, включающие геномные последовательности, протеомные данные и информацию о взаимодействиях молекул. Эффективные архитектуры, оптимизированные для работы с биологическими данными, позволят не только повысить точность предсказаний, но и раскрыть скрытые закономерности в сложных биологических процессах. Такой подход открывает возможности для углубленного понимания механизмов заболеваний, разработки новых лекарственных препаратов и создания персонализированных методов лечения, представляя собой качественно новый этап в биомедицинских исследованиях.
UBio-Mol26: Фундамент для Биологически Специфичных Моделей
Представляем UBio-Mol26 — крупномасштабный и разнообразный набор данных, разработанный для обучения био-специфических фундаментальных моделей. Набор данных содержит обширную коллекцию молекулярных конфигураций, предназначенных для улучшения производительности и обобщающей способности моделей в задачах, связанных с биомолекулами. Размер и разнообразие UBio-Mol26 позволяют проводить эффективное обучение и валидацию сложных моделей, обеспечивая более точные и надежные результаты в биоинформатике и смежных областях. Данный набор данных предоставляет исследователям необходимые ресурсы для разработки передовых инструментов и методов анализа биомолекулярных систем.
Для создания набора данных UBio-Mol26 была применена двухкомпонентная стратегия. Первый компонент — “снизу-вверх” — подразумевал перечисление фундаментальных биохимических строительных блоков, таких как аминокислоты, нуклеотиды и простые лиганды, с последующим комбинированием их в более сложные структуры. Второй компонент — “сверху-вниз” — включал выборку и анализ конфигураций, встречающихся в нативных протеиновых окружениях, полученных из баз данных белковых структур. Такой подход позволил объединить преимущества систематического охвата базовых элементов с реалистичностью и биологической релевантностью данных, полученных из природных источников, обеспечивая разнообразие и репрезентативность набора данных для обучения био-специфических моделей.
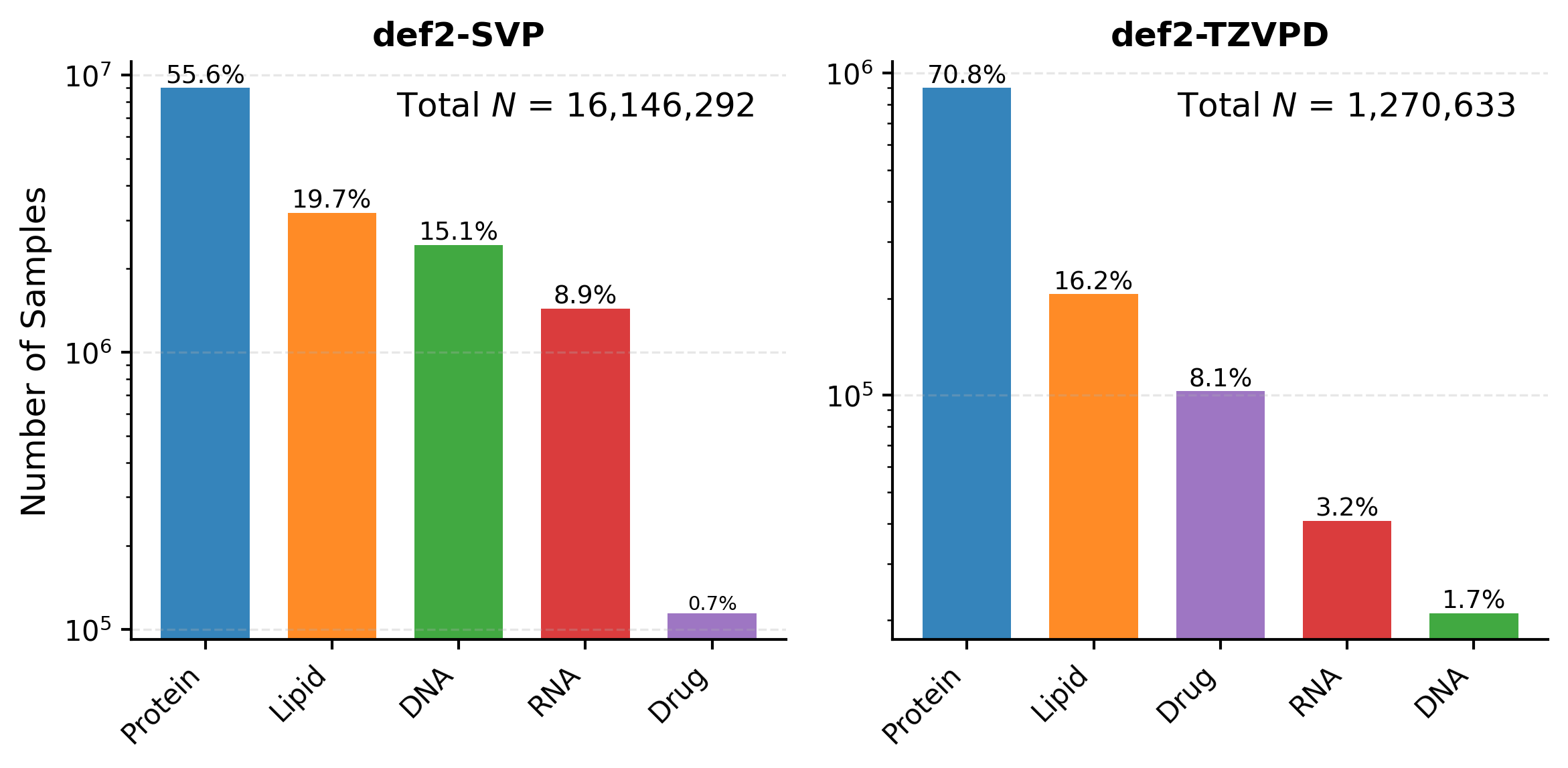
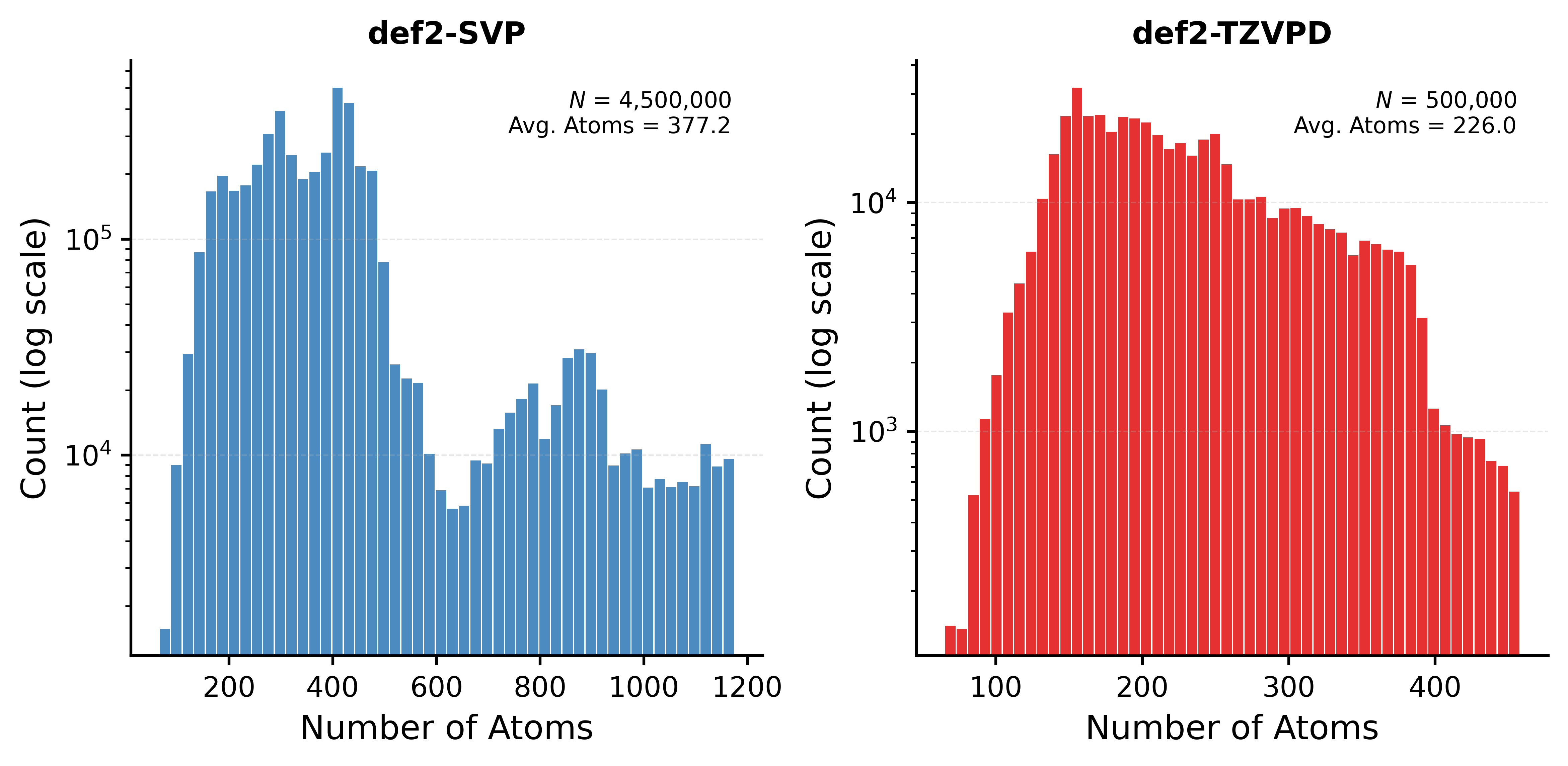
Выпущенный датасет UBio-Protein26 5M содержит более 5 миллионов конфигураций, обеспечивая широкое покрытие для обучения био-специфических моделей. Этот объем данных позволяет эффективно тренировать модели, способные обобщать знания и предсказывать свойства молекул в различных биологических контекстах. Включенные конфигурации представляют собой разнообразный набор структурных состояний, что критически важно для создания надежных и точных моделей, способных работать с реальными биологическими системами. Количество конфигураций в 5 миллионов является значительным шагом вперед по сравнению с ранее доступными датасетами, что позволяет добиться существенного улучшения производительности моделей машинного обучения в области биомолекулярных исследований.
Для обеспечения высокого качества и репрезентативности данных в UBio-Mol26, при построении набора данных использовались тщательно отобранные базисные наборы, в частности Def2-TZVP и Def2-TZVPD. Def2-TZVP представляет собой тройной-зета-валентный набор, обеспечивающий хорошее соотношение точности и вычислительной стоимости. В свою очередь, Def2-TZVPD добавляет диффузные функции, необходимые для адекватного описания анионов и систем с делокализованными электронами, часто встречающихся в биологических молекулах. Комбинация этих базисных наборов позволила получить данные, точно отражающие электронную структуру и свойства биомолекул, что критически важно для обучения био-специфических фундаментальных моделей.
UBio-MolFM: Новая Архитектура для Биологических Расчетов
UBio-MolFM представляет собой новую основу для создания фундаментальных моделей, специально разработанную для биологических систем. В ее основе лежит комбинация набора данных UBio-Mol26, содержащего информацию о молекулярных структурах, и современной архитектуры, обеспечивающей эффективное моделирование сложных биологических взаимодействий. Данный подход позволяет создавать модели, способные к обобщению и прогнозированию свойств биологических объектов на основе их структурных характеристик, что открывает возможности для решения широкого круга задач в области биоинформатики и молекулярной биологии.
В основе UBio-MolFM лежит E2Former-V2 — архитектура трансформера, демонстрирующая линейную сложность по отношению к количеству атомов в молекуле. Данная архитектура обеспечивает эффективное моделирование сложных взаимодействий в биологических системах, сохраняя при этом ковариантность к вращениям и трансляциям. Это достигается за счет использования принципов эквивариантных нейронных сетей и, в частности, применения рекурсии Вигнера-6j, что позволяет существенно снизить вычислительные затраты при сохранении точности моделирования и соблюдении симметрий.
Архитектура E2Former-V2 обеспечивает вычислительную эффективность и сохранение эквивариантности благодаря использованию рекурсии Вигнера-6j. Этот метод позволяет эффективно вычислять преобразования в пространстве представлений, сохраняя инвариантность к вращениям и трансляциям. Рекурсия Вигнера-6j является ключевым компонентом, позволяющим снизить вычислительную сложность операций, необходимых для моделирования взаимодействий в биологических системах. E2Former-V2 опирается на принципы эквивариантных нейронных сетей, что гарантирует, что модель корректно реагирует на изменения в ориентации и положении молекул, что критически важно для точного моделирования биологических процессов. \begin{Bmatrix} j_1 & j_2 & j_3 \\ j_4 & j_5 & j_6 \end{Bmatrix} представляет собой символ Вигнера-6j, используемый для вычисления коэффициентов преобразования.
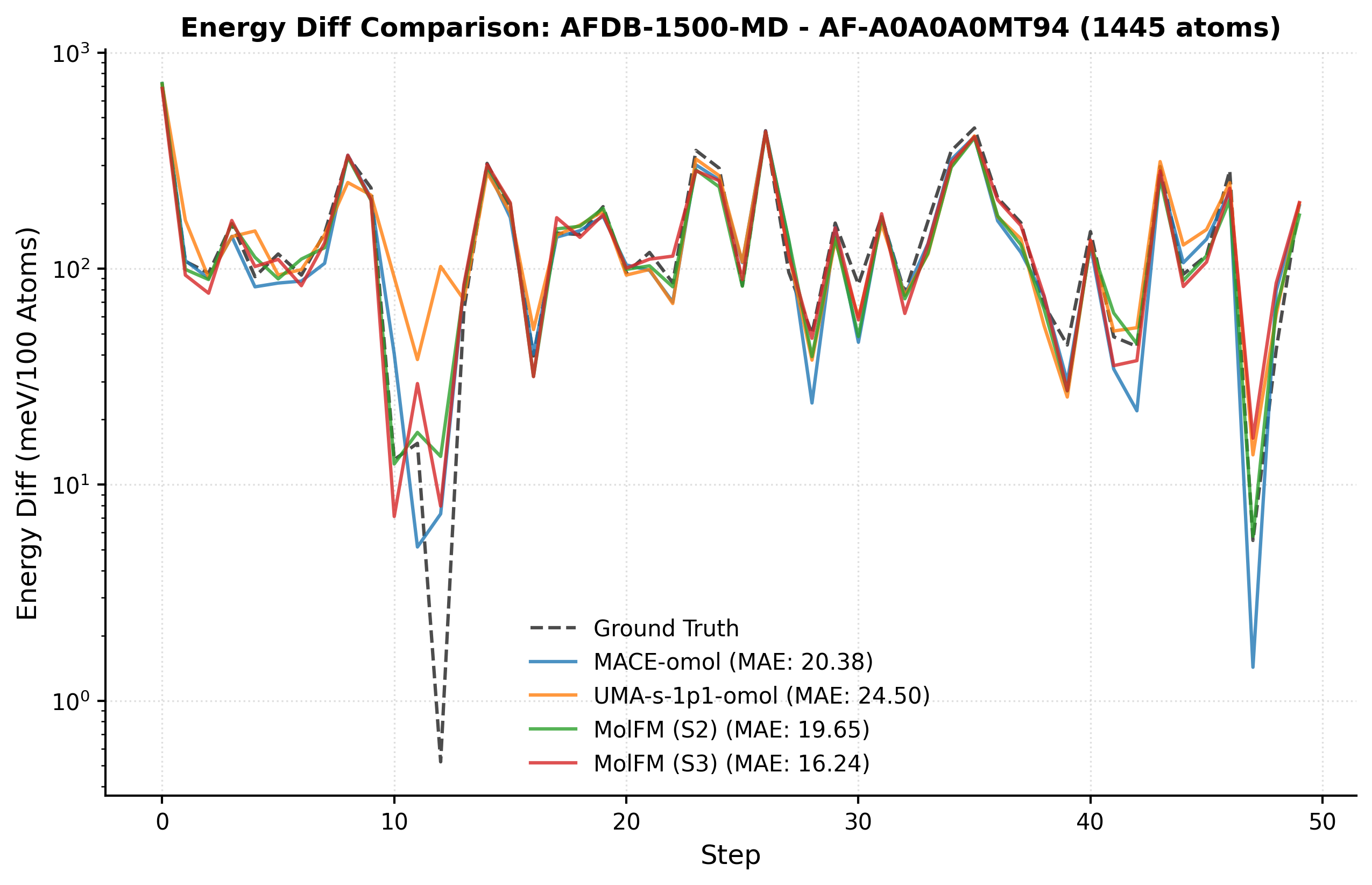
Архитектура UBio-MolFM демонстрирует значительное увеличение скорости обработки данных по сравнению с передовыми моделями, использующими принцип эквивариантности, такими как UMA-S. В ходе тестирования была достигнута скорость обработки до 4 раз выше, чем у UMA-S, что свидетельствует о повышенной эффективности предложенного подхода. Данное улучшение производительности обусловлено оптимизацией архитектуры E2Former-V2 и использованием рекурсивного преобразования Вигнера-6j, позволяющих снизить вычислительную сложность и повысить пропускную способность при выводе результатов.
Тренировка с Учетом Сложности: Трёхэтапный Подход
Для обучения модели UBio-MolFM был реализован трёхэтапный протокол обучения с учебным планом (Curriculum Learning). Начальный этап включал в себя инициализацию на основе энергии, что позволило модели быстро освоить базовые энергетические представления. Затем последовал этап согласования энергии и силы, где автоматическое дифференцирование использовалось для вычисления сил из предсказанных энергий, обеспечивая точные градиенты для оптимизации. Завершающий этап представлял собой многоуровневое уточнение, позволяющее модели достичь высокой точности и масштабируемости. Такой подход позволил значительно улучшить предсказание молекулярных свойств и моделирование динамического поведения, открывая новые возможности для разработки лекарств и материаловедения.
Автоматическое дифференцирование стало ключевым инструментом в процессе вычисления сил, исходя из предсказанных энергий молекулярных систем. Этот метод позволяет точно определить градиенты, необходимые для оптимизации модели UBio-MolFM. Вместо традиционных, трудоемких вычислений, автоматическое дифференцирование позволяет аналитически вычислить производные энергии по координатам атомов, предоставляя точные векторы сил. Такая точность критически важна для эффективной тренировки модели и обеспечения достоверности предсказаний, позволяя UBio-MolFM достигать ab\,initio-уровня точности при моделировании сложных молекулярных систем и предсказании их поведения.
Разработанная модель демонстрирует превосходную способность к прогнозированию молекулярных свойств и моделированию динамического поведения, открывая новые горизонты в областях разработки лекарственных препаратов и материаловедения. Точность предсказаний позволяет существенно ускорить процесс поиска новых соединений с заданными характеристиками, снижая потребность в дорогостоящих и трудоемких экспериментах. Возможность достоверного моделирования динамики молекул предоставляет уникальную платформу для изучения механизмов химических реакций и предсказания поведения материалов в различных условиях, что особенно важно для создания инновационных материалов с улучшенными свойствами. Такой подход значительно расширяет возможности компьютерного моделирования в химии и физике, приближая науку к разработке принципиально новых технологий.
Модель UBio-MolFM достигла точности, сопоставимой с методами расчета из первых принципов ab~initio, при моделировании систем, содержащих до 1500 атомов. Данный результат демонстрирует не только высокую степень достоверности предсказаний относительно молекулярных свойств и динамического поведения, но и масштабируемость подхода. Способность эффективно работать с системами такого размера открывает новые перспективы для проведения вычислительных экспериментов в областях, требующих высокой точности, таких как разработка лекарственных препаратов и материаловедение, где моделирование крупных и сложных молекулярных структур является ключевым этапом исследований.

Представленная работа демонстрирует стремление к созданию универсальной модели, способной охватить сложность биосистем. Это напоминает попытку заглянуть за горизонт событий, где привычные законы физики теряют силу. Как заметил Лев Ландау: «Теория, которая не может быть опровергнута, не стоит потраченного на неё времени.» UBio-MolFM, используя подход машинного обучения и огромные объемы данных, представляет собой смелую попытку построить модель, способную предсказывать поведение молекул в сложных условиях. Однако, как и любая теоретическая конструкция, она требует постоянной проверки и совершенствования, ведь даже самая элегантная модель может оказаться несостоятельной перед лицом новой информации. Основной концепт, заключающийся в создании универсальной модели для биосистем, подчёркивает хрупкость любого научного построения.
Что же дальше?
Представленная работа, как и любая попытка создать универсальную модель, неизбежно обнажает границы познания. Создание UBio-MolFM — это не триумф, а скорее осознание того, насколько хрупки наши представления о взаимодействиях в биосистемах. Возможно, самое важное, что демонстрирует эта работа, — это необходимость переосмысления самой концепции “закона” в контексте сложных молекулярных систем. Всё, что мы называем законом, может раствориться в горизонте событий, если данные, на которых он основан, окажутся неполными или смещенными.
Очевидно, что дальнейшее развитие потребует не только увеличения объемов данных и совершенствования архитектур нейронных сетей, но и принципиально нового подхода к интерпретации результатов моделирования. Важно помнить, что даже самая точная модель — это лишь приближение к реальности, и её предсказания всегда сопряжены с определенной степенью неопределенности. Следующим шагом, вероятно, станет интеграция UBio-MolFM с другими моделями, охватывающими различные уровни организации биосистем, от атомарного до клеточного.
В конечном итоге, задача заключается не в создании идеальной модели, а в развитии критического мышления и способности признавать собственные заблуждения. Чёрная дыра — это не просто объект, это зеркало нашей гордости и заблуждений. И чем дальше мы продвигаемся в познании сложных систем, тем яснее становится, что истинное открытие — это не момент славы, а осознание того, что мы почти ничего не знаем.
Оригинал статьи: https://arxiv.org/pdf/2602.17709.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Капитал Б&Т и его душа в AESI
- Стоит ли покупать фунты за йены сейчас или подождать?
- Почему акции Pool Corp могут стать привлекательным выбором этим летом
- Квантовые Химеры: Три Способа Не Потерять Рубль
- Два актива, которые взорвут финансовый Лас-Вегас к 2026
- МКБ акции прогноз. Цена CBOM
- Один потрясающий рост акций, упавший на 75%, чтобы купить во время падения в июле
- Будущее ONDO: прогноз цен на криптовалюту ONDO
- Российский рынок: Рост на фоне Ближнего Востока и сырьевая уверенность на 100 лет (28.02.2026 10:32)
- Геопространственные модели для оценки оползневой опасности: новый уровень точности
2026-02-24 06:33