Автор: Денис Аветисян
Исследователи разработали универсальный подход к созданию и анализу водяных знаков для больших языковых моделей, позволяющий обеспечить их надежную идентификацию.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал![Предложенная схема рассматривает водяные знаки как задачу оптимизации с ограничениями, максимизирующую ожидаемую оценку при контроле искажений водяного знака, где ограничение балансирует качество и разнообразие, что позволяет охватить существующие подходы и разработать новые оптимальные схемы на основе заданных критериев, исходя из псевдослучайной выборки из распределения вероятностей следующего токена [latex]p[/latex] и оценок токенов [latex]g[/latex].](https://arxiv.org/html/2602.06754v1/x1.png)
Предложенная рамка, основанная на оптимизации с ограничениями, раскрывает фундаментальный компромисс между качеством, разнообразием и силой водяного знака, используя такие инструменты, как расхождение Кулбака-Лейблера и распределение Гамбеля.
Несмотря на активное развитие методов защиты от распространения сгенерированного искусственным интеллектом контента, единого принципиального подхода к водяным знакам для больших языковых моделей (LLM) до сих пор не существовало. В данной работе, посвященной «A Unified Framework for LLM Watermarks», предложен унифицированный подход к водяным знакам на основе заданного ограничения, позволяющий вывести существующие схемы и выявить фундаментальный компромисс между качеством, разнообразием и мощностью водяного знака. Показано, что большинство существующих методов могут быть получены из единой задачи оптимизации с ограничениями, используя, например, KL-дивергенцию и распределение Гамбеля. Какие новые возможности для разработки надежных и адаптивных схем водяных знаков открывает предложенный фреймворк?
Растущая Тень Синтетического Контента: Вызов для Разума
В последнее время наблюдается экспоненциальный рост возможностей генерации текста благодаря развитию больших языковых моделей (БЯМ). Эти модели способны создавать связные и правдоподобные тексты, имитирующие человеческий стиль письма, что открывает новые горизонты в автоматизации контента и творчестве. Однако, эта же способность порождает серьезные опасения относительно подлинности цифрового контента и возможности манипуляций. Возникает потребность в надежных методах определения источника текста — является ли он результатом человеческого труда или создан искусственным интеллектом — поскольку грань между ними становится все более размытой. Растущая доступность и усовершенствование БЯМ ставят под вопрос доверие к информации, распространяемой в цифровом пространстве, и требуют разработки новых подходов к верификации и контролю контента.
Разграничение текстов, созданных человеком, и текстов, сгенерированных машиной, становится всё более сложной задачей, что обуславливает острую необходимость в надёжных методах верификации их происхождения. Современные языковые модели демонстрируют поразительную способность имитировать человеческий стиль письма, делая обнаружение автоматического создания контента крайне затруднительным. Это представляет значительные проблемы в различных сферах, включая журналистику, образование и борьбу с дезинформацией, где достоверность источника имеет первостепенное значение. Разработка инструментов, способных точно определять авторство и подтверждать подлинность текста, является ключевой задачей для сохранения доверия к цифровому контенту и защиты от манипуляций.
Сложность современных больших языковых моделей (LLM) представляет собой значительное препятствие для понимания происхождения создаваемого ими текста. Эти модели, функционирующие подобно “чёрным ящикам”, скрывают внутренние механизмы генерации, что затрудняет отслеживание процесса формирования конкретного текста. Внутренняя архитектура LLM, состоящая из миллионов или даже миллиардов параметров, делает практически невозможным определение точных факторов, повлиявших на выходной результат. Это усложняет задачу верификации подлинности текста, поскольку невозможно точно установить, был ли он создан человеком или сгенерирован машиной, и какие именно данные послужили основой для генерации. Отсутствие прозрачности в работе LLM создаёт серьезные вызовы для обеспечения доверия к цифровому контенту и борьбы с дезинформацией.
![Сравнение компромисса между обнаруживаемостью водяных знаков (TPR@1) и качеством текста (точность по LLM-бенчмарку) для различных вариантов ограничений и значений [latex]\varepsilon[/latex] показывает, что использование жестких ограничений обеспечивает более высокое качество, в то время как мягкие ограничения позволяют добиться компромисса, при этом средняя точность неводяных знаков служит ориентиром.](https://arxiv.org/html/2602.06754v1/x11.png)
Водяные Знаки для LLM: Раскрытие Истины в Потоке Текста
Водяные знаки для больших языковых моделей (LLM) представляют собой превентивный подход к решению проблем, связанных с синтетическим текстом. Суть метода заключается во внедрении незаметных сигналов непосредственно в генерируемый текст. Эти сигналы позволяют достоверно установить происхождение текста, то есть подтвердить, что он был создан конкретной языковой моделью. Данный подход направлен на борьбу с дезинформацией, плагиатом и другими злоупотреблениями, возникающими при массовом создании контента с помощью ИИ, обеспечивая возможность атрибуции и проверки подлинности текста.
Метод водяных знаков для больших языковых моделей (LLM) основан на задаче оптимизации с ограничениями, целью которой является достижение надежной идентификации сгенерированного текста при сохранении его качества и семантической связности. Процесс включает в себя тонкую настройку вероятностного распределения токенов при генерации текста, чтобы внедрить незаметный сигнал — водяной знак. Ключевым аспектом является баланс между силой обнаружения водяного знака (способностью однозначно идентифицировать текст как сгенерированный моделью) и минимизацией искажений, которые могут повлиять на читабельность и естественность текста. Оптимизация обычно предполагает минимизацию расхождения Кульбака-Лейблера D_{KL} между исходным распределением вероятностей токенов и распределением, модифицированным для внедрения водяного знака, при соблюдении ограничений на перплексию или другие метрики качества текста.
Эффективность методов водяных знаков для LLM основана на математических принципах, в частности, на минимизации расхождения Кульбака-Лейблера (KL Divergence) между исходным и водяным знаком распределениями вероятностей. Минимизация D_{KL}(P||Q) позволяет встроить водяной знак, сохраняя при этом качество и семантическую связность текста. Статистически значимое улучшение обнаруживается при анализе ответа AAR (Adversarial Auto-Regressive), с p-значениями, достигающими 7.4e-5, что подтверждает эффективность предложенного подхода к атрибуции синтезированного текста.
Разнообразие Методов Водяных Знаков: Поиск Идеального Баланса
Водяные знаки, такие как AAR Watermark, используют механизм добавления случайного шума на основе распределения Гумбеля (Gumbel Noise) для повышения устойчивости к незначительным изменениям в тексте. Этот подход позволяет водяному знаку сохранять свою обнаружимость даже после небольших правок или перефразировок. Распределение Гумбеля вводится для создания небольших, но заметных отклонений в вероятности токенов, что затрудняет удаление водяного знака без существенного изменения качества текста. В отличие от детерминированных методов, добавление случайного шума повышает робастность алгоритма к случайным искажениям, вызванным процессами редактирования или обработки текста.
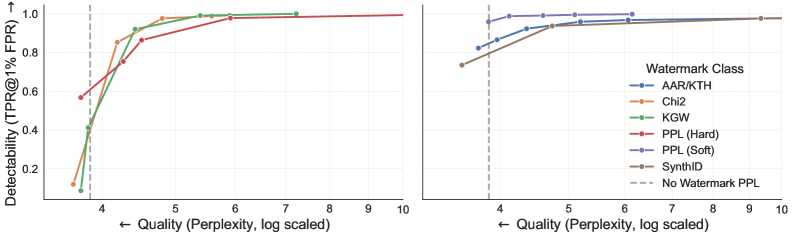
Водяные знаки Red-Green и Chi2 используют различные статистические тесты и стратегии кодирования сигнала для встраивания информации в текст. Red-Green Watermark основан на анализе частоты появления определенных последовательностей символов и их сравнении с ожидаемыми значениями, в то время как Chi2 Watermark применяет χ^2 тест для оценки соответствия наблюдаемого распределения символов теоретическому, внося небольшие изменения в вероятности токенов. Различия в этих подходах приводят к различным характеристикам устойчивости к модификациям и обнаружимости водяных знаков, отражаясь в значениях Perplexity (PPL) — для Chi2 PPL составляет 5.7.
Метод SynthID использует процесс турнирного отбора для внедрения водяных знаков, в ходе которого генерируются варианты текста и отбираются те, которые наилучшим образом соответствуют критериям водяного знака. В отличие от него, метод PPL Watermark (Perplexity Watermark) влияет на процесс генерации текста, используя оценки перплексии PPL. Более низкая перплексия указывает на более вероятный текст, и данный метод тонко смещает вероятности токенов, чтобы включить сигнал водяного знака, сохраняя при этом общее качество генерируемого текста. Разные реализации PPL Watermark, «жесткая» и «мягкая», демонстрируют различные уровни влияния на перплексию и, следовательно, разные уровни надежности водяного знака.
Различные алгоритмы водяных знаков оптимизируют баланс между качеством, разнообразием и устойчивостью к воздействиям, адаптируясь к специфическим требованиям приложений. Показатели перплексии (PPL) демонстрируют различия в этих подходах: AAR имеет PPL 4.8, Chi2 — 5.7, KGW — 6.4, PPL (жесткий) — 7.4, PPL (мягкий) — 5.4, а SynthID — 13.9. Более низкий показатель перплексии обычно указывает на более предсказуемый и качественный текст, однако может снижать устойчивость водяного знака к изменениям. Значения PPL позволяют оценить компромиссы, достигнутые каждым алгоритмом в оптимизации указанного баланса Quality-Diversity-Power.
![Сравнение компромисса между обнаружимостью водяных знаков (TPR@1) и качеством текста (log PPL) при различных ограничениях и значениях [latex]\varepsilon[/latex] показывает, что использование жестких ограничений обеспечивает более четкое разделение между водяными знаками и исходным текстом по сравнению с мягкими ограничениями, при этом ответы модели Ministral-3-14B, сгенерированные на основе 1000 запросов из ELI5, имеют длину 200 токенов при температуре 0.7.](https://arxiv.org/html/2602.06754v1/x10.png)
Обеспечение Будущего Цифрового Авторства: Гарантия Подлинности в Эпоху ИИ
Эффективная водяная маркировка больших языковых моделей (LLM) представляет собой значимый шаг к снижению рисков, связанных с распространением дезинформации и плагиатом, способствуя формированию более надежной информационной среды. Данная технология позволяет установить проверяемую связь между сгенерированным текстом и его источником, что дает возможность авторам контента и платформам эффективно противодействовать злонамеренному использованию. Внедрение таких методов не только защищает интеллектуальную собственность и поддерживает академическую честность, но и укрепляет доверие общественности к цифровым медиа, что подтверждается статистически значимыми результатами исследований, демонстрирующими высокую эффективность различных алгоритмов водяной маркировки.
Технологии водяных знаков для больших языковых моделей (LLM) предоставляют возможность установить проверяемую связь между сгенерированным текстом и его источником, что существенно расширяет возможности для борьбы со злоупотреблениями. Эти методы позволяют контент-мейкерам и платформам идентифицировать текст, созданный искусственным интеллектом, и, в случае необходимости, отслеживать его происхождение. Это особенно важно для предотвращения распространения дезинформации, плагиата и других форм неправомерного использования контента, созданного с помощью LLM. Подобный механизм верификации способствует повышению ответственности за генерируемый текст и укрепляет доверие к цифровым медиа, предоставляя инструменты для эффективного противодействия злонамеренным действиям и защиты интеллектуальной собственности.
Сохранение интеллектуальной собственности, поддержание академической честности и укрепление доверия к цифровым медиа становятся все более важными задачами в эпоху широкого распространения больших языковых моделей. Исследования демонстрируют высокую эффективность методов водяных знаков для отслеживания происхождения текстов, созданных искусственным интеллектом. Полученные статистические данные, подтвержденные нулевыми p-значениями для тестов Chi2 и KGW, а также чрезвычайно низким значением 1.1e-9 для PPL (Hard) отклика, свидетельствуют о значительной статистической достоверности этих методов. Это позволяет не только защитить авторские права и бороться с плагиатом, но и гарантировать достоверность информации, распространяемой в цифровом пространстве, что особенно важно для научных исследований, журналистики и общественной дискуссии.
Для обеспечения устойчивой эффективности и широкого внедрения водяных знаков для больших языковых моделей необходимы непрерывные исследования и усилия по стандартизации. Разработка надежных методов защиты от удаления или обхода водяных знаков, а также создание общепринятых протоколов для их внедрения и проверки, имеют решающее значение. Согласованные стандарты позволят различным платформам и инструментам беспрепятственно взаимодействовать, обеспечивая надежную атрибуцию контента, созданного ИИ. Более того, дальнейшее изучение устойчивости водяных знаков к различным манипуляциям с текстом, таким как перефразирование и перевод, необходимо для сохранения их эффективности в долгосрочной перспективе. Такой подход позволит не только защитить права интеллектуальной собственности, но и укрепить доверие к цифровому контенту, создаваемому с помощью искусственного интеллекта.
![Эксперименты с моделью Llama 3 1-8B на 1000 запросов из ELI5 показали, что увеличение обнаружимости водяных знаков (TPR@1) связано с компромиссом, проявляющимся в увеличении расхождения Кульбака-Лейблера [latex]\mathbb{E}_{G}[q(G)][/latex] и ограничении PPL.](https://arxiv.org/html/2602.06754v1/x8.png)
Исследование представляет собой попытку систематизировать методы водяных знаков для больших языковых моделей, рассматривая их как задачу оптимизации с ограничениями. Этот подход позволяет анализировать компромисс между качеством генерируемого текста, разнообразием водяных знаков и их надежностью. Клод Шеннон однажды заметил: «Информация — это организация данных». Данная работа как раз и демонстрирует, как структурированное применение математических принципов, таких как дивергенция Кульбака-Лейблера и распределение Гамбеля, позволяет эффективно внедрять и обнаруживать водяные знаки, фактически, организуя данные таким образом, чтобы в них была заложена скрытая информация. В контексте компромисса между качеством, разнообразием и силой водяного знака, предложенный фреймворк предоставляет инструменты для поиска оптимального баланса, что крайне важно для практического применения.
Что дальше?
Представленный подход, по сути, лишь формализовал интуитивное понимание: любое вмешательство в генеративный процесс неизбежно порождает трилемму — качество, разнообразие и силу сигнала. Каждый «патч» — попытка оптимизировать эти параметры, и каждый патч — философское признание фундаментальной неидеальности системы. Очевидно, что будущее исследований лежит не столько в поиске «невидимого» водяного знака, сколько в осознании его неизбежной видимости, пусть и замаскированной в статистическом шуме.
Необходимо переосмыслить само понятие «обнаружения». Вместо бинарной классификации «с меткой — без метки», стоит перейти к оценке степени влияния метки на генеративные свойства модели. Как изменится «творческий потенциал» модели при различных уровнях водяного знака? Какие артефакты возникнут? Ответы на эти вопросы требуют разработки новых метрик и методов анализа, способных улавливать тонкие изменения в распределении вероятностей генерируемого текста.
И, наконец, стоит признать, что гонка вооружений между создателями и взломщиками водяных знаков бесконечна. Лучший «хак» — это осознание того, как всё работает, понимание внутренних механизмов и, возможно, принятие того, что абсолютной защиты не существует. В конечном счете, интереснее не «запечатать» модель, а понять, как она «думает».
Оригинал статьи: https://arxiv.org/pdf/2602.06754.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Серебро прогноз
- Мечел акции прогноз. Цена MTLR
- АЛРОСА акции прогноз. Цена ALRS
- Группа Аренадата акции прогноз. Цена DATA
- XLP против VDC: Более низкие комиссии или более широкое покрытие?
- Российский рынок: между нефтью, рублем и геополитикой: обзор ключевых трендов и перспектив (04.04.2026 01:32)
- Крипто-зима продолжается: падение объемов торгов, регуляторные риски и скандалы (07.04.2026 07:45)
- Искусственный интеллект и его уверенность: когда модели не знают, чего не знают
- Будущее CRV: прогноз цен на криптовалюту CRV
2026-02-10 01:00