Автор: Денис Аветисян
В данной работе представлен инновационный подход к анализу динамических систем, основанный на адаптации методов ректифицированного потока к низкоразмерным пространствам.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал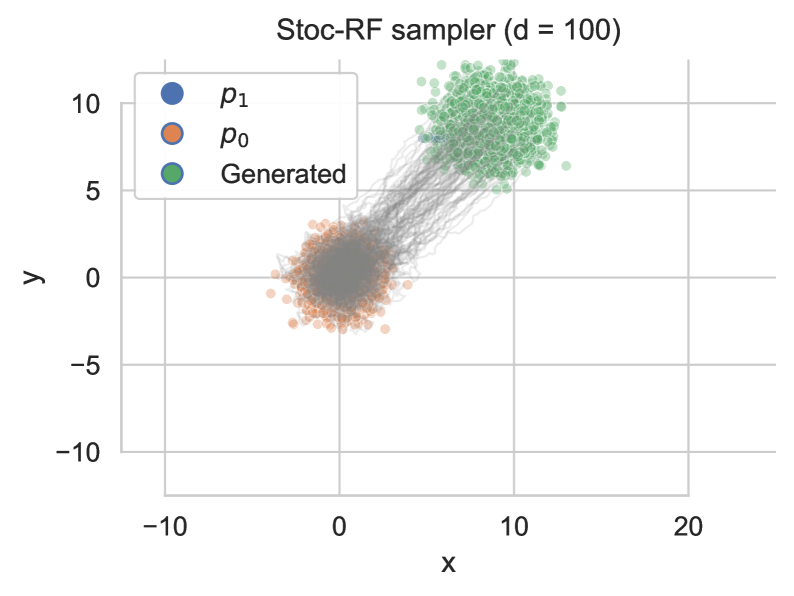
Исследование демонстрирует успешную экстракцию структурированной информации из текста с использованием формата JSON.
Несмотря на успехи современных генеративных моделей, вопрос об их адаптации к низкой размерности целевого распределения остается недостаточно изученным. В работе ‘Low-Dimensional Adaptation of Rectified Flow: A New Perspective through the Lens of Diffusion and Stochastic Localization’ исследуется, каким образом Rectified Flow (RF) автоматически приспосабливается к этой размерности для ускорения процесса выборки. Показано, что при корректном выборе схемы временной дискретизации и точных оценках дрифта, RF обеспечивает сложность итераций порядка O(k/\varepsilon), где \varepsilon — требуемая точность, а k — внутренняя размерность распределения. Установлена связь между RF и стохастическим диффузионным вероятностным моделированием (DDPM), что позволило разработать новый стохастический семплер RF, и возникает вопрос, какие еще возможности открывает использование этой связи для улучшения эффективности генеративных моделей?
Задача: Открытие Знаний в Связях
Задача завершения графов знаний заключается в предсказании отсутствующих связей между сущностями, что является критически важным для широкого спектра приложений искусственного интеллекта. Представьте себе огромную сеть информации, где некоторые связи между понятиями утеряны или неизвестны. Автоматическое восстановление этих связей позволяет системам рассуждать, делать выводы и предоставлять более точные и полные ответы на запросы. От рекомендательных систем, предлагающих релевантные товары или контент, до интеллектуальных поисковых систем, способных понимать контекст запроса, и даже в области открытия лекарств — способность предсказывать связи в графах знаний открывает новые возможности для автоматизации и улучшения принятия решений. Таким образом, эффективное завершение графов знаний является ключевой проблемой в развитии интеллектуальных систем нового поколения.
Традиционные методы завершения графов знаний сталкиваются со значительными трудностями при работе с современными, крупномасштабными базами данных. Эти методы, зачастую основанные на логических выводах или простых моделях сходства, оказываются неспособными эффективно обрабатывать огромное количество сущностей и связей, характерных для современных графов знаний. Сложность структуры, неоднозначность данных и постоянное добавление новой информации приводят к экспоненциальному росту вычислительных затрат и снижению точности предсказаний. В результате, предсказание отсутствующих связей становится все более сложной задачей, что ограничивает возможности применения графов знаний в различных областях, включая поиск информации, рекомендательные системы и интеллектуальный анализ данных. Необходимость разработки новых, масштабируемых и эффективных методов, способных справляться с этой сложностью, является ключевым вызовом в области искусственного интеллекта.
Языковые Модели: Новый Взгляд на Связи
Крупные языковые модели (КЯМ) демонстрируют значительный потенциал в задаче завершения графов знаний благодаря своей способности моделировать сложные взаимосвязи между сущностями. Традиционные методы часто сталкиваются с трудностями при обработке многоаспектных отношений и контекстной информации, в то время как КЯМ, обученные на обширных текстовых корпусах, способны улавливать нюансы семантики и экстраполировать знания для предсказания отсутствующих связей. Это достигается благодаря архитектуре трансформеров, позволяющей учитывать долгосрочные зависимости в тексте и эффективно представлять знания в векторном пространстве, что способствует более точным и надежным предсказаниям отношений между сущностями в графе знаний.
Эффективное использование больших языковых моделей (БЯМ) для предсказания отношений требует тщательной разработки формата входных запросов. Конструирование промптов должно учитывать специфику задачи Relation Prediction, где БЯМ выступает в роли инструмента для выявления связей между сущностями. Формат запроса должен четко определять входные сущности и ожидаемый тип отношения, например, через структурированные шаблоны или примеры, демонстрирующие желаемый формат ответа. Важным аспектом является оптимизация промптов для уменьшения неоднозначности и повышения точности предсказаний, что может достигаться за счет использования техник few-shot learning или fine-tuning модели на специфичном наборе данных, содержащем примеры отношений.
Эффективность использования параметров является критически важным фактором при применении больших языковых моделей для предсказания отношений. Обучение и развертывание моделей с миллиардами параметров требует значительных вычислительных ресурсов и энергозатрат. Методы снижения вычислительной сложности, такие как квантизация, прунинг и дистилляция знаний, позволяют уменьшить размер модели и ускорить процесс инференса без существенной потери точности. Баланс между количеством параметров, вычислительными затратами и производительностью модели является ключевой задачей для практического применения больших языковых моделей в задачах предсказания отношений и завершения графов знаний.
Искусство Запроса: Управление Знаниями
Инженерия запросов (Prompt Engineering) представляет собой методологию, позволяющую направлять большие языковые модели (LLM) для точного завершения графов знаний. В основе подхода лежит разработка и оптимизация текстовых запросов, которые служат входными данными для LLM. Вместо прямого запроса на получение информации, инженерия запросов предполагает формулировку задач таким образом, чтобы модель могла логически вывести недостающие связи или атрибуты в графе знаний. Эффективные запросы структурируются с учётом особенностей архитектуры и обучающих данных конкретной LLM, что позволяет минимизировать ошибки и максимизировать точность завершения графа знаний. Важно отметить, что качество запроса напрямую влияет на достоверность и полноту полученных результатов.
Формат запроса играет решающую роль в получении точных результатов от больших языковых моделей. Обогащение запросов контекстной информацией, включающей релевантные данные и детали, существенно повышает производительность модели при выполнении задач, связанных с извлечением знаний и логическими выводами. Добавление контекста позволяет модели более точно интерпретировать запрос, снижая вероятность неверных или неоднозначных ответов и увеличивая релевантность полученной информации. Эффективное использование контекста требует тщательного подбора и форматирования данных, чтобы они были легко интерпретируемы моделью и способствовали более точному выполнению поставленной задачи.
Метод “Chain of Thought” (Цепочка Мыслей) является продвинутой техникой промпт-инжиниринга, направленной на улучшение способности больших языковых моделей к логическому мышлению. Суть метода заключается в том, чтобы побудить модель не просто выдавать конечный ответ, а последовательно объяснять процесс рассуждений, приведший к этому ответу. В промпте, использующем “Chain of Thought”, модель получает инструкции явно демонстрировать шаги, необходимые для решения задачи, что позволяет ей более эффективно использовать имеющиеся знания и снижает вероятность ошибок, особенно в сложных задачах, требующих многоступенчатого анализа. Оценка промежуточных шагов рассуждений также облегчает отладку и выявление слабых мест в логике модели.
Оценка и Ранжирование: Измерение Успеха
Оценка эффективности моделей в задачах предсказания связей между сущностями производится с помощью метрик, таких как Hits@K и MRR (Mean Reciprocal Rank). Hits@K измеряет долю случаев, когда правильный ответ находится среди первых K предсказаний модели, что позволяет оценить способность модели ранжировать релевантные элементы выше в списке. MRR, в свою очередь, вычисляет среднюю величину обратной ранжировки первого релевантного результата, предоставляя единую оценку точности ранжирования. Эти метрики, будучи количественными, позволяют сравнивать различные модели и стратегии обучения, выявляя наиболее эффективные подходы к построению систем, способных точно предсказывать и ранжировать связи между данными. Высокие значения Hits@K и MRR свидетельствуют о высокой способности модели находить и правильно ранжировать релевантные связи, что критически важно для задач, требующих точного извлечения информации и принятия решений.
Для обеспечения объективной оценки и сопоставления различных подходов к работе с большими языковыми моделями, применяются стандартизированные метрики, такие как Hits@K и MRR. Эти показатели позволяют исследователям и разработчикам количественно сравнивать эффективность различных стратегий промптинга — способов формулировки запросов к модели — и конфигураций параметров. Благодаря использованию общих критериев оценки, становится возможным выявить наиболее оптимальные методы для достижения желаемых результатов, независимо от конкретной архитектуры модели или набора данных. Это, в свою очередь, способствует более быстрому прогрессу в области обработки естественного языка и созданию более точных и надежных систем искусственного интеллекта.
Исследования демонстрируют, что обучение с небольшим количеством примеров (Few-Shot Learning) позволяет большим языковым моделям достигать конкурентоспособных результатов даже при ограниченном объеме обучающих данных. Вместо традиционного обучения на огромных массивах информации, модели способны обобщать знания и делать точные прогнозы, основываясь на нескольких представленных примерах связей. Этот подход существенно снижает потребность в ресурсах, необходимых для сбора и аннотации больших датасетов, и открывает возможности для адаптации моделей к новым задачам и доменам с минимальными усилиями. Эффективность Few-Shot Learning подчеркивает способность этих моделей к быстрому обучению и обобщению, что делает их особенно ценными в ситуациях, когда доступ к большим объемам размеченных данных ограничен или невозможен.
Представленная работа демонстрирует извлечение структурированной информации из текста посредством формата JSON, что позволяет упростить анализ и представление сложных данных. Подобный подход к организации информации соответствует принципу ясности и лаконичности, стремясь к удалению всего несущественного. Как говорил Леонардо да Винчи: «Простота — высшая форма изысканности». Этот афоризм отражает суть исследования — стремление к представлению данных в наиболее чистой и понятной форме, где каждый элемент несет функциональную нагрузку, а избыточность исключена. Акцент на низкоразмерной адаптации и стохастической локализации подтверждает поиск оптимального баланса между детализацией и обобщением, что соответствует идее «совершенства, достигаемого не добавлением, а удалением».
Куда Далее?
Представленная работа демонстрирует извлечение структурированных данных. Это факт. Однако, абстракции стареют. Вопрос в том, насколько надёжно эта структура отражает реальность, а не просто порядок, навязанный алгоритмом. Полагаться на чёткость там, где её нет — опасная иллюзия.
Очевидное ограничение — зависимость от качества исходного текста. Шум, двусмысленность, метафоры — каждая сложность требует алиби. Будущие исследования должны сосредоточиться на устойчивости к неструктурированным данным, на способности алгоритма к самокоррекции и, что важнее, к признанию собственной некомпетентности.
Перспективы — не в увеличении объёма извлекаемых данных, а в углублении понимания их взаимосвязей. Принципы остаются, а детали — преходящи. Следует сместить фокус с автоматического извлечения на автоматическую верификацию, на создание систем, способных не просто находить информацию, но и оценивать её достоверность.
Оригинал статьи: https://arxiv.org/pdf/2601.15500.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Нефть, Геополитика и Рубль: Что ждет инвесторов в ближайшую неделю
- HYPE: Почему токен Hyperliquid может взлететь до $150 – анализ доходов, рисков и конкурентов (13.03.2026 21:15)
- Российская экономика: Бюджетное давление, геополитика и новые экспортные возможности (11.03.2026 21:32)
- Театр энергетики: акции, которые обещают вечность
- Газпром акции прогноз. Цена GAZP
- Охота за дивидендами: три недооценённых акции
- Палантир против Амазон: Безумие на Уолл-стрит
- Три цифры, раскрывающие суть стабильных монет
- Amazon: Фарс о величии и жажде власти
2026-01-24 06:32