Автор: Денис Аветисян
Исследователи предлагают алгоритм, позволяющий агентам осваивать новые задачи без предварительного обучения, используя гибкое представление о возможных стратегиях.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал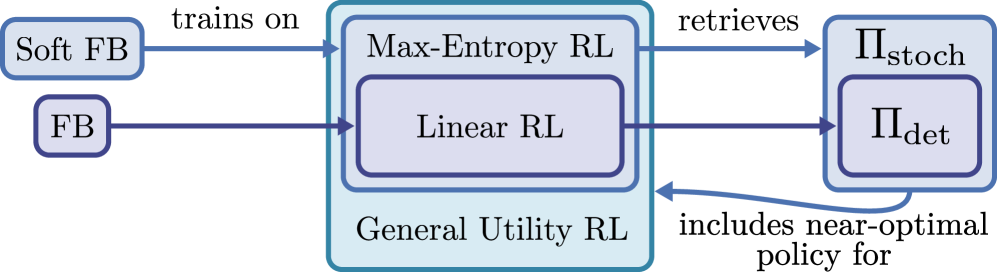
В статье представлен алгоритм Soft FB, использующий фреймворк прямого и обратного распространения для обучения разнообразным стратегиям оптимизации общих функций полезности в обучении с подкреплением без предварительной подготовки.
Несмотря на значительный прогресс в обучении с подкреплением, возможность быстрого освоения новых задач без дополнительного обучения остается сложной проблемой. В данной работе, посвященной ‘Soft Forward-Backward Representations for Zero-shot Reinforcement Learning with General Utilities’, предлагается новый алгоритм, использующий мягкую версию алгоритма прямого-обратного прохода для извлечения разнообразного набора политик из неразмеченных данных. Предложенный подход позволяет оптимизировать произвольные функции полезности, выходящие за рамки задач с аддитивными наградами, обеспечивая обобщение на более широкий класс задач обучения с подкреплением. Способны ли эти представления стать основой для создания действительно универсальных агентов, способных адаптироваться к любым новым условиям без необходимости переобучения?
За гранью традиционного обучения с подкреплением: необходимость обобщения
Традиционное обучение с подкреплением часто сталкивается с трудностями при адаптации к новым, ранее не встречавшимся средам. Суть проблемы заключается в том, что алгоритмы, успешно обученные в конкретной обстановке, демонстрируют значительное снижение эффективности при малейших изменениях условий. Это связано с тем, что они, как правило, «запоминают» оптимальные действия для конкретных состояний, а не приобретают общие принципы, позволяющие эффективно действовать в разнообразных ситуациях. Таким образом, каждая новая среда требует существенного переобучения, что делает применение таких методов в реальном мире, где условия постоянно меняются, крайне сложным и ресурсоемким. Неспособность к обобщению опыта является фундаментальным ограничением, препятствующим широкому распространению технологий обучения с подкреплением за пределами симулированных сред.
Существующие методы обучения с подкреплением зачастую сталкиваются с необходимостью масштабной переподготовки при столкновении с незнакомыми условиями, что существенно ограничивает их применимость в реальном мире. Проблема заключается в том, что модели, обученные для конкретной среды, демонстрируют значительное снижение эффективности при малейших изменениях в обстановке или задачах. Каждый раз, когда агент сталкивается с новой ситуацией, требуются значительные вычислительные ресурсы и время для адаптации, что делает их непрактичными для динамичных и непредсказуемых сред, таких как автономные системы или робототехника. Необходимость постоянной перенастройки подрывает потенциал этих алгоритмов и подчеркивает потребность в более гибких и обобщающих подходах к обучению.
Эффективная передача знаний между различными задачами представляет собой ключевую проблему в области обучения с подкреплением. Существующие алгоритмы часто демонстрируют ограниченную способность к обобщению, требуя значительных усилий по переобучению при незначительных изменениях в окружающей среде или целях. Разработка компактных и универсальных представлений, способных улавливать общие закономерности, является необходимым условием для создания интеллектуальных агентов, способных быстро адаптироваться к новым ситуациям. Именно поэтому исследователи активно изучают методы мета-обучения и обучения переносу, стремясь создать системы, которые могут не просто осваивать отдельные задачи, но и эффективно использовать накопленный опыт для решения принципиально новых проблем, минимизируя потребность в обширных данных и вычислениях.
Перспективное направление обучения с подкреплением без учителя, известное как Zero-Shot RL, предлагает принципиально новый подход к преодолению ограничений традиционных методов. Вместо трудоемкой переподготовки для каждой новой среды, Zero-Shot RL использует предварительно обученные представления, полученные на основе обширных наборов данных или в симулированных условиях. Эти представления служат своего рода “универсальными знаниями”, позволяющими агенту адаптироваться к незнакомым задачам и окружениям без необходимости повторного обучения с нуля. По сути, агент способен применять накопленный опыт к новым ситуациям, экстраполируя знания и быстро осваивая незнакомые условия, что значительно повышает эффективность и применимость обучения с подкреплением в реальном мире. Это открывает возможности для создания более гибких и автономных систем, способных к самообучению и адаптации к постоянно меняющимся условиям.
![Визуализация обратной связи (FB) в образовательной среде показывает, что обученная политика успешно генерирует оптимальные действия для вложений с нормой [latex]||z|| < 1[/latex], даже без явной тренировки на них, что подтверждается близостью полученных политик к детерминированным решениям и цветовой картой, отображающей значения Q-функции [latex]Q_R^z[/latex].](https://arxiv.org/html/2602.06769v1/x10.png)
Алгоритм «Вперед-Назад»: фундаментальный подход к обучению представлений
Алгоритм «Вперед-Назад» представляет собой эффективный метод обучения представлений задач (task embeddings) посредством анализа частоты посещения состояний в будущем. В его основе лежит идея о том, что ценность состояния определяется не только непосредственной наградой, но и вероятностью достижения других состояний, что позволяет моделировать долгосрочные зависимости. Алгоритм вычисляет вероятности посещения каждого состояния, исходя из текущего состояния и действий, и использует эти вероятности для построения представления задачи. Это позволяет агенту эффективно планировать действия, основываясь на ожидаемых будущих посещениях состояний, и адаптироваться к различным задачам, требующим разной последовательности действий и посещения состояний.
Алгоритм опирается на представление пар «состояние-действие» посредством так называемых «Successor Features» (признаков преемников). Эти признаки кодируют ожидаемое будущее посещение состояний, достижимых из текущего состояния после выполнения конкретного действия. Вместо непосредственного представления ценности действия, Successor Features отражают структуру задачи, описывая, какие состояния наиболее вероятно будут посещены в будущем. Математически, \phi_{s,a} представляет собой вектор, определяющий ожидаемое распределение посещений состояний после выполнения действия a в состоянии s . Использование Successor Features позволяет алгоритму обобщать знания о задаче, не требуя явного представления всех возможных состояний и действий, и эффективно использовать информацию о структуре среды.
Эффективность алгоритма Forward-Backward ограничена из-за его чувствительности к смещению распределения (distributional shift) и недостаточной исследовательской способности. Смещение распределения возникает при изменении динамики среды или поведения агента во время обучения, что приводит к снижению точности оценки частоты посещения состояний. Недостаток исследования проявляется в склонности алгоритма к застреванию в локальных оптимумах, поскольку он полагается на посещенные состояния и не активно ищет новые, потенциально более полезные состояния. Это ограничивает способность алгоритма обобщать полученные знания на новые ситуации и приводит к ухудшению производительности в динамически меняющихся средах.
Для обеспечения устойчивой работы алгоритма, необходимо интегрировать методы, стимулирующие исследование среды. Использование стандартного алгоритма «вперед-назад» может привести к застреванию в локальных оптимумах или неполному охвату пространства состояний, особенно в сложных задачах. Внедрение стратегий, таких как ε-жадное исследование, добавление бонусов за посещение новых состояний, или использование алгоритмов, основанных на неопределенности (например, Upper Confidence Bound), позволяет агенту более эффективно исследовать пространство состояний и, следовательно, повысить надежность и обобщающую способность полученных представлений задачи.
![Визуализация показывает, что при обучении Soft FB в образовательной среде, политики становятся более детерминированными при увеличении нормы векторного представления задачи [latex]z[/latex], что демонстрируется изменением распределения действий (белые точки) и соответствующих Q-значений [latex]Q_R^z[/latex].](https://arxiv.org/html/2602.06769v1/x3.png)
Soft FB: обучение с энтропией и универсальной полезностью
Алгоритм Soft FB является расширением алгоритма Forward-Backward за счет включения регуляризации энтропии. Данный подход стимулирует исследование пространства состояний и обучение стохастических политик, что позволяет агенту избегать застревания в локальных оптимумах. Регуляризация энтропии добавляется к целевой функции, поощряя политику выбирать действия с большей вероятностью, даже если эти действия не являются оптимальными в данный момент времени. Это способствует более широкому охвату пространства состояний и, как следствие, улучшению обобщающей способности агента. В результате, Soft FB способен обучаться более надежным и адаптивным политикам, особенно в сложных и неопределенных средах.
Использование регуляризации энтропии в Soft FB не только повышает способность алгоритма к обобщению, но и согласуется с принципами обучения с максимальной энтропией (Maximum Entropy RL). В рамках Maximum Entropy RL, целью является максимизация не только ожидаемой кумулятивной награды, но и энтропии политики. Это способствует исследованию пространства действий и предотвращает преждевременную сходимость к субоптимальным решениям. В Soft FB, добавление штрафа за низкую энтропию политики стимулирует алгоритм поддерживать разнообразие в стратегиях, что, в свою очередь, улучшает устойчивость и адаптивность к новым, ранее не встречавшимся ситуациям, а также способствует более эффективному исследованию пространства состояний.
Алгоритм Soft FB поддерживает обучение с обобщённой полезностью (General Utility RL), что позволяет оптимизировать произвольные дифференцируемые функции от функции занимаемости (occupancy function) политики. В отличие от традиционных методов обучения с подкреплением, ориентированных на линейные награды, Soft FB позволяет задавать более сложные и гибкие критерии оптимизации. Это достигается путём непосредственной оптимизации функции полезности, которая может учитывать различные аспекты поведения политики, такие как разнообразие траекторий, избежание опасных состояний или достижение специфических промежуточных целей. \mu(s) — функция занимаемости, определяющая вероятность посещения состояния s политикой, и Soft FB напрямую оптимизирует функции, зависящие от \mu(s) .
Эффективность алгоритма Soft FB обусловлена его способностью формировать устойчивые представления о задаче и политики даже при ограниченном количестве взаимодействий со средой. Данное свойство подтверждается конкурентоспособными результатами, достигнутыми в различных задачах, связанных с локомоцией и навигацией. В частности, алгоритм демонстрирует способность к эффективному обучению и обобщению, требуя относительно небольшое количество данных для достижения производительности, сравнимой или превосходящей альтернативные методы обучения с подкреплением в сложных задачах манипулирования и передвижения.

Повышение оценки мер с помощью генеративных моделей
Метод Soft FB использует два основных подхода к оценке мер: неявные (Implicit Measure Models) и явные (Explicit Measure Models). Неявные модели напрямую используют представления, полученные из прямого и обратного проходов данных, без дополнительного обучения. Явные модели, напротив, формируются посредством генеративного моделирования, что позволяет им изучать структуру данных и прогнозировать будущие состояния. Комбинирование этих двух типов моделей обеспечивает более надежную и точную оценку мер, учитывая как непосредственные представления данных, так и результаты генеративного обучения.
Точность явной модели оценки (Explicit Measure Model) значительно повышается за счет использования геометрических моделей горизонта (Geometric Horizon Models). Эти модели используют геометрические представления о пространстве состояний для более точного прогнозирования будущих состояний и, следовательно, улучшения оценки мер. В частности, они позволяют более эффективно моделировать долгосрочные зависимости и учитывать нелинейные эффекты, которые сложно учесть при использовании стандартных методов оценки. Использование геометрических представлений позволяет моделировать сложное поведение системы и повысить точность прогнозирования мер, особенно в задачах, где важна долгосрочная перспектива.
Метод Flow Matching играет ключевую роль в обучении модели явных мер, повышая её способность оценивать последующие меры. Этот подход, основанный на непрерывном сопоставлении траекторий в пространстве состояний, позволяет эффективно обучать модель предсказывать распределение будущих состояний, исходя из текущего состояния и действий. В процессе обучения Flow Matching минимизирует расхождение между смоделированным и фактическим потоком состояний, что приводит к более точной оценке мер преемственности — ключевого компонента для прогнозирования долгосрочного поведения и оценки эффективности различных стратегий. Точность оценки последовательных мер напрямую влияет на способность модели адекватно представлять и прогнозировать будущие состояния системы.
Комбинированный подход, включающий как неявные, так и явные модели оценки, обеспечивает высокую точность представления и прогнозирования будущих состояний системы. Использование генеративных моделей, в частности, Flow Matching для обучения явных моделей оценки преемников, позволяет добиться значительной корреляции между оценками производительности, полученными в режиме оффлайн-анализа, и фактической производительностью, наблюдаемой в реальных условиях. Данная корреляция подтверждает эффективность предложенного метода в задачах прогнозирования и оценки поведения сложных систем без необходимости проведения дорогостоящих и длительных экспериментов.

Влияние на надежный и адаптируемый интеллект
Алгоритм Soft FB продемонстрировал выдающиеся результаты в сложных сценариях обучения с подкреплением, особенно в задачах, требующих обобщения и адаптации к новым условиям. В отличие от традиционных методов, которые часто сталкиваются с трудностями при переносе знаний на незнакомые среды, Soft FB способен эффективно функционировать даже в ситуациях, не предусмотренных на этапе обучения. Это достигается за счет интеграции принципов максимальной энтропии, что позволяет агенту исследовать пространство решений более широко и находить оптимальные стратегии в условиях неопределенности. Исследования показали, что данный подход обеспечивает значительное повышение устойчивости и гибкости агентов, позволяя им успешно решать задачи, требующие не только максимизации вознаграждения, но и способности быстро адаптироваться к изменяющимся обстоятельствам.
Алгоритм Soft FB демонстрирует заметное превосходство над традиционными методами благодаря своей способности эффективно функционировать в принципиально новых, ранее не встречавшихся средах. В отличие от систем, жестко привязанных к конкретным условиям обучения, данный подход позволяет агенту адаптироваться и успешно решать задачи даже в незнакомых ситуациях. Это достигается за счет формирования более устойчивого и обобщенного представления об окружающей среде, что позволяет избегать ошибок и повышать надежность работы в динамически меняющихся условиях. Способность к адаптации открывает широкие перспективы для применения в различных областях, включая робототехнику, автономные системы и искусственный интеллект, где требуется высокая степень гибкости и устойчивости к неопределенности.
Совместимость алгоритма Soft FB с Convex RL значительно расширяет область его применения, позволяя решать более широкий спектр задач, особенно в областях, где требуется оптимизация с учётом выпуклых ограничений. Convex RL, фокусируясь на оптимизации выпуклых функций, обеспечивает гарантии сходимости и оптимальности, что в сочетании с преимуществами Soft FB — высокой адаптивностью и способностью к обобщению — формирует мощный инструмент для создания интеллектуальных агентов. Это особенно важно в таких областях, как робототехника, финансы и управление ресурсами, где сложные ограничения и необходимость в надёжных решениях являются ключевыми факторами. Интеграция этих двух подходов позволяет не только находить оптимальные решения в заданных условиях, но и эффективно адаптироваться к изменяющейся среде, обеспечивая устойчивую и надежную работу агента.
Алгоритм Soft FB выходит за рамки традиционного подхода, основанного на простом максимизировании вознаграждения, открывая путь к созданию более утонченных и интеллектуальных агентов. Вместо слепого стремления к немедленной выгоде, он стимулирует исследование и освоение разнообразных стратегий, что позволяет агенту формировать более глубокое понимание окружающей среды и адаптироваться к новым, непредсказуемым ситуациям. Такой подход способствует развитию способности к комплексному рассуждению и принятию взвешенных решений, поскольку агент учитывает не только текущее вознаграждение, но и долгосрочные последствия своих действий. В результате, Soft FB позволяет создавать системы, способные решать сложные задачи, требующие не только эффективности, но и гибкости и способности к обучению на протяжении всего жизненного цикла.
Исследование демонстрирует стремление к созданию систем, способных к адаптации и обучению без привязки к конкретным задачам. Авторы предлагают Soft FB — алгоритм, оперирующий с широким спектром политик, оптимизирующих общую полезность. Это напоминает слова Тим Бернерс-Ли: «Веб — это не просто набор документов, это среда, в которой люди могут взаимодействовать друг с другом и обмениваться идеями». Подобно тому, как веб предоставляет платформу для бесчисленных взаимодействий, Soft FB стремится создать основу для обучения с подкреплением, способную охватить широкий спектр задач и полезностей, не требуя специфической настройки для каждой из них. Алгоритм, по сути, взламывает привычную парадигму обучения, фокусируясь на обобщении, а не на узкой специализации.
Что дальше?
Предложенный алгоритм Soft FB, безусловно, демонстрирует интересную способность к адаптации к различным функциям полезности без прямой переподготовки. Однако, возникает вопрос: а что, если сама концепция “общей полезности” — это иллюзия, удобная абстракция? Что, если истинная оптимизация требует не универсальности, а глубокой специализации, пусть и достигаемой через постоянное, бесконечное обучение? Ведь даже самые изящные алгоритмы, как и любая система, имеют свои пределы применимости, и попытка обойти эту данность, навязать универсальное решение, может привести к неожиданным, нежелательным последствиям.
Следующим шагом видится не столько совершенствование алгоритма, сколько исследование границ его применимости. Необходимо подвергнуть Soft FB экстремальным испытаниям, столкнуть его с задачами, для которых универсальная функция полезности принципиально неприменима. Что произойдёт, если система столкнётся с противоречивыми целями, или с ситуациями, где оптимизация одного параметра неизбежно ведёт к деградации другого? И, самое главное, насколько хорошо алгоритм способен к самоанализу, к выявлению собственных ошибок и ограничений?
Возможно, истинный прорыв в области обучения с подкреплением лежит не в создании универсальных алгоритмов, а в разработке систем, способных к постоянному реверс-инжинирингу собственной логики, к пересмотру базовых принципов в процессе обучения. Ведь, в конечном счёте, знание — это не просто набор фактов, а способность подвергать сомнению любые, даже самые фундаментальные истины.
Оригинал статьи: https://arxiv.org/pdf/2602.06769.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Серебро прогноз
- Мечел акции прогноз. Цена MTLR
- Группа Аренадата акции прогноз. Цена DATA
- АЛРОСА акции прогноз. Цена ALRS
- Российский рынок: между нефтью, рублем и геополитикой: обзор ключевых трендов и перспектив (04.04.2026 01:32)
- Нефтяной Сигнал Опасно Приближается: Крипто Рынок На Грани Коррекции? (06.04.2026 09:15)
- Будущее CRV: прогноз цен на криптовалюту CRV
- XLP против VDC: Более низкие комиссии или более широкое покрытие?
- Алфавит и Искусственный Рассвет
2026-02-09 19:49