Автор: Денис Аветисян
Исследование посвящено изучению методов обучения плотных поисковых систем, использующих несколько положительных примеров для повышения точности ранжирования.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал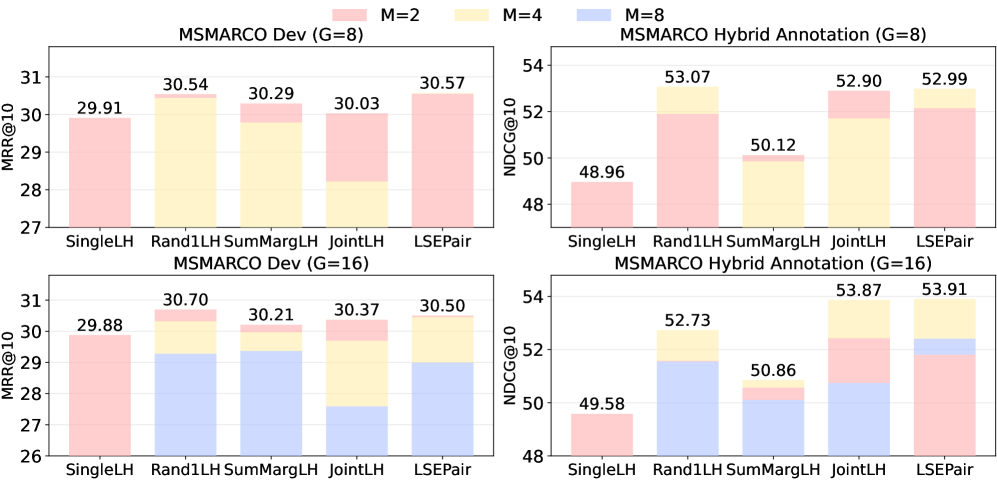
Систематический анализ различных функций потерь для обучения плотных поисковых систем, с эмпирическим подтверждением превосходства LSEPair и эффективности Rand1LH.
Эффективность современных систем, опирающихся на поиск релевантной информации, часто ограничивается использованием разреженных данных и единичных положительных примеров. В работе ‘Training Dense Retrievers with Multiple Positive Passages’ предпринято систематическое исследование методов обучения плотных поисковых систем с использованием множественных положительных отрывков, что позволяет преодолеть эти ограничения. Показано, что функция потерь LSEPair демонстрирует стабильно превосходящие результаты, в то время как более простые подходы, такие как Rand1LH, обеспечивают надежную базовую линию. Какие теоретические и практические аспекты необходимо учитывать при разработке эффективных стратегий обучения плотных поисковых систем с использованием данных, аннотированных большими языковыми моделями?
Преодолевая Ограничения: От Ключевых Слов к Семантическому Поиску
Традиционные методы информационного поиска зачастую основываются на сопоставлении ключевых слов, что приводит к упущению смысловых оттенков и контекста. Такой подход, хотя и прост в реализации, не позволяет системе понять истинное значение запроса или документа. В результате, даже если в документе присутствует необходимое ключевое слово, он может быть пропущен, если его общий смысл не соответствует запросу пользователя. Эта проблема особенно актуальна для запросов, выраженных синонимами, или для случаев, когда требуется понимание сложных взаимосвязей между понятиями. Неспособность уловить семантические нюансы существенно ограничивает эффективность поиска и приводит к снижению релевантности извлеченных результатов.
Существующие методы информационного поиска часто сталкиваются с трудностями, когда для получения ответа требуется объединение информации из нескольких релевантных источников. Традиционные подходы, ориентированные на сопоставление ключевых слов, оказываются неэффективными в ситуациях, требующих анализа и синтеза данных, разбросанных по различным документам. Это особенно заметно в задачах, требующих комплексного ответа на вопрос или создания краткого изложения большого объема текста, где простого поиска по ключевым словам недостаточно для выявления взаимосвязей и формирования целостной картины. Поиск и объединение информации из множества источников требует более сложных алгоритмов, способных к семантическому анализу и логическому выводу, что представляет собой значительную проблему для современных систем.
Ограничения традиционных методов поиска информации особенно заметны при решении сложных задач, требующих глубокого понимания контекста. Когда ответ на вопрос или краткое изложение документа требует объединения информации из нескольких источников, простые алгоритмы сопоставления ключевых слов оказываются неэффективными. Например, для ответа на вопрос, требующий сравнения различных точек зрения, представленных в нескольких документах, или для создания связного резюме, охватывающего несколько тем, необходим анализ семантических связей, а не просто поиск совпадений слов. Это приводит к снижению точности и полноты ответов, а также к неспособности эффективно обрабатывать сложные запросы, требующие синтеза знаний из различных источников.
В отличие от традиционных методов информационного поиска, основанных на сопоставлении ключевых слов, плотное извлечение информации (Dense Retrieval) предлагает принципиально иной подход. Суть заключается в представлении как запросов, так и документов в виде векторных представлений, называемых эмбеддингами. Эти эмбеддинги, полученные с помощью моделей глубокого обучения, кодируют семантическое значение текста, позволяя системе находить документы, смыслово соответствующие запросу, даже если в них отсутствуют точные ключевые слова. Такой подход позволяет эффективно преодолеть ограничения, связанные с лексическим несоответствием и синонимией, значительно повышая точность и релевантность результатов поиска, особенно в задачах, требующих синтеза информации из нескольких источников. Фактически, представление информации в виде эмбеддингов открывает путь к более «интеллектуальному» поиску, способному понимать смысл запроса и находить наиболее полезные документы, а не просто сопоставлять слова.
Обучение на Множественности: Расширение Горизонтов Релевантности
Традиционное обучение систем плотного поиска (Dense Retrieval) часто ограничивается использованием только одного релевантного документа на запрос. Такой подход игнорирует тот факт, что для одного запроса может существовать несколько документов, которые в той или иной степени соответствуют ему. Обучение с использованием только одного позитивного примера может приводить к недостаточно полному представлению запроса и релевантных документов, снижая способность модели эффективно находить все релевантные результаты. Использование нескольких позитивных примеров позволяет модели изучать более устойчивые и обобщающие представления, что потенциально повышает точность и полноту поиска.
Использование нескольких релевантных документов во время обучения, так называемый подход «Multiple Positives», позволяет модели формировать более устойчивые и обобщающие представления. В стандартной практике Dense Retrieval часто рассматривается лишь один положительный пример (релевантный документ) для каждого запроса. Однако, обучение с использованием нескольких релевантных документов предоставляет модели больше информации о семантических связях между запросом и различными аспектами релевантной информации. Это способствует более точному кодированию запросов и документов в векторном пространстве, что, в свою очередь, повышает эффективность поиска и извлечения релевантных результатов. Улучшенная устойчивость достигается за счет снижения чувствительности к незначительным вариациям в формулировках запросов или документах.
Традиционные методы обучения систем поиска информации часто используют только один релевантный документ для каждого запроса. Для преодоления этого ограничения были разработаны альтернативные функции потерь, такие как ‘Rand1LH’, ‘JointLH’, ‘SumMargLH’ и ‘LSEPair’, которые учитывают несколько релевантных документов при обучении. Эти функции потерь расширяют стандартный подход, позволяя модели изучать более надежные представления данных. В частности, ‘LSEPair’ демонстрирует стабильно высокую производительность в различных экспериментах, что подтверждает его эффективность в обучении систем поиска с использованием множества релевантных документов.
Эффективное обучение представлений при использовании методов, учитывающих множественные релевантные документы, критически зависит от надежной функции потерь, в частности, функции потерь InfoNCE. InfoNCE (Noise Contrastive Estimation) позволяет модели различать релевантные документы от негативных примеров, максимизируя взаимную информацию между запросом и положительными документами. Формально, функция потерь стремится минимизировать расстояние между векторами запроса и релевантных документов в векторном пространстве, одновременно увеличивая расстояние до негативных примеров. L = -log(\frac{exp(sim(q,p))}{exp(sim(q,p)) + \sum_{n} exp(sim(q,n))}), где q — вектор запроса, p — вектор положительного документа, а n — векторы негативных документов. Применение InfoNCE Loss в сочетании с целями обучения, такими как Rand1LH, JointLH, SumMargLH и LSEPair, обеспечивает более точное и надежное обучение представлений, необходимое для эффективного поиска информации.
Автоматизация Аннотаций: Сила Больших Языковых Моделей
Создание высококачественных обучающих данных для плотного поиска (Dense Retrieval) традиционно требует значительных временных и финансовых затрат, связанных с ручной аннотацией. Этот процесс включает в себя привлечение экспертов для оценки релевантности документов по отношению к запросам, что является трудоемкой задачей, особенно при работе с большими объемами данных. Стоимость ручной аннотации напрямую влияет на общую стоимость разработки и обучения моделей, ограничивая возможность создания масштабных и разнообразных обучающих наборов данных. Необходимость в ручной работе также замедляет процесс итеративной разработки и улучшения моделей, поскольку внесение изменений в данные требует повторной аннотации.
Метод “LLM Аннотация” автоматизирует процесс создания релевантных меток для обучающих данных, используя возможности больших языковых моделей (LLM). В отличие от ручной аннотации, LLM способны генерировать метки релевантности для каждого запроса и соответствующего документа, что позволяет создавать наборы данных с множественными положительными примерами (“Multiple Positives”). Это особенно важно для обучения моделей извлечения информации (Dense Retrieval), где наличие нескольких релевантных документов для одного запроса значительно повышает эффективность обучения и, как следствие, улучшает качество поисковой выдачи.
Автоматизированный подход к аннотированию данных, использующий большие языковые модели (LLM), существенно снижает затраты и трудоемкость процесса курирования данных. Традиционное ручное аннотирование требует значительных временных и финансовых ресурсов, особенно при создании масштабных наборов данных для обучения моделей поиска. Использование LLM позволяет автоматизировать большую часть процесса маркировки, что приводит к снижению стоимости на порядок и возможности создания значительно более крупных и разнообразных обучающих наборов. Это, в свою очередь, позволяет охватить более широкий спектр запросов и сценариев, что положительно сказывается на обобщающей способности и эффективности конечной модели.
Результаты экспериментов на стандартных бенчмарках демонстрируют, что модели, обученные на данных, размеченных с использованием LLM-аннотаций, показывают улучшенные показатели производительности по сравнению с моделями, обученными на данных, размеченных вручную. В частности, наблюдается повышение точности и полноты извлечения релевантных документов, а также улучшение метрик ранжирования, таких как NDCG и MAP. Данные результаты подтверждают эффективность автоматизированного подхода к аннотации данных с использованием больших языковых моделей для повышения качества обучения систем поиска и извлечения информации.
Оценка и Обобщение: Проверка на Реальных Данных
Оценка способности моделей плотного поиска эффективно работать в различных областях и с разными задачами представляет собой сложную проблему. В этой связи, набор данных BEIR (Benchmarking IR) играет ключевую роль, выступая в качестве важного эталона для проверки обобщающей способности таких моделей. BEIR включает в себя широкий спектр текстовых коллекций и типов запросов, что позволяет всесторонне оценить, насколько хорошо модель способна адаптироваться к новым, ранее не встречавшимся сценариям. Использование BEIR позволяет исследователям и разработчикам не просто достигать высоких показателей в узкоспециализированных задачах, но и создавать действительно надежные и универсальные системы информационного поиска, способные эффективно работать с разнообразными данными и потребностями пользователей.
Применение метода обучения с постепенным усложнением (Curriculum Learning) позволяет значительно повысить эффективность моделей извлечения информации. Суть подхода заключается в том, что в процессе обучения модели сначала предоставляются более простые примеры, что облегчает начальное освоение закономерностей. По мере обучения сложность примеров постепенно увеличивается, что способствует более глубокому пониманию и обобщению знаний. Такой подход позволяет модели более эффективно адаптироваться к новым, более сложным задачам и демонстрирует улучшенные результаты в различных областях, обеспечивая повышение точности и надежности системы извлечения информации.
Успешное прохождение эталонных тестов, таких как ‘BEIR’, с достижением показателя NDCG@10 в 0.38 при использовании LSEPair, наглядно демонстрирует превосходную способность модели к обобщению за пределами обучающей выборки. Этот результат указывает на то, что система способна эффективно извлекать релевантную информацию из разнообразных источников и в различных контекстах, не теряя при этом точности и качества. Способность к обобщению является критически важной для практического применения систем поиска, поскольку реальные запросы пользователей редко совпадают в точности с теми, которые использовались при обучении модели. Достижение высокого показателя на ‘BEIR’ подтверждает надежность и адаптивность разработанного подхода к плотному поиску, открывая перспективы для его применения в широком спектре информационных систем и приложений.
Модель LSEPair демонстрирует впечатляющие результаты на ключевых бенчмарках, что свидетельствует о ее высокой эффективности в задачах информационного поиска. Набор данных NQ (Natural Questions) показывает точность вхождения в топ-20 ответов на уровне 83.4%, в то время как на MS MARCO достигнут Recall@1000 в 71.2% и MRR@10 (Mean Reciprocal Rank) в 32.8%. Эти показатели указывают на способность модели находить релевантную информацию даже в больших объемах данных и обеспечивать высокую точность ответов, что открывает перспективы для создания надежных и универсальных систем информационного поиска с широким спектром практических применений.
Исследование, представленное в данной работе, подчеркивает важность выбора оптимальной функции потерь при обучении плотных моделей поиска. Авторы систематически анализируют различные подходы к многопозитивному обучению, выявляя теоретические связи между ними и демонстрируя эмпирическое превосходство LSEPair. Этот подход позволяет добиться более стабильной и предсказуемой оптимизации, что особенно важно при работе со сложными моделями и большими объемами данных. Как однажды заметил Линус Торвальдс: «Плохой код похож на плохую шутку: если его нужно объяснять, он не смешной». Точно так же, эффективная функция потерь не требует сложных объяснений — она просто обеспечивает ожидаемый результат, позволяя модели учиться эффективно и достигать высоких показателей в задаче поиска.
Куда же дальше?
Представленная работа, тщательно исследуя различные стратегии обучения плотных систем поиска, неизбежно обнажает глубинные противоречия. Утверждение о превосходстве LSEPair над альтернативами, хотя и подкреплено эмпирическими данными, не отменяет фундаментального вопроса: является ли оптимизация ранжирования посредством контрастивного обучения принципиально достаточным условием для достижения истинного семантического поиска? Наблюдаемое превосходство одного подхода над другим, вероятно, является следствием конкретных характеристик используемых данных и архитектуры, а не свидетельством абсолютной истинности.
Дальнейшие исследования должны быть направлены на преодоление ограничения, связанного с необходимостью большого количества негативных примеров, которое искусственно увеличивает вычислительные затраты. Попытки обойти эту проблему посредством эвристик, хотя и привлекательны с практической точки зрения, всегда подразумевают компромисс между точностью и эффективностью. Более того, представляется важным углубиться в анализ градиентного поведения, выявляя потенциальные «ловушки» локальных минимумов, которые могут ограничивать обобщающую способность моделей.
В конечном счете, задача состоит не в том, чтобы просто «улучшить метрики», а в том, чтобы построить систему, способную к истинному пониманию смысла, а не к формальному сопоставлению векторов. И в этом контексте, кажущиеся победы в оптимизации ранжирования представляются лишь скромными шагами на пути к недостижимому идеалу.
Оригинал статьи: https://arxiv.org/pdf/2602.12727.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Серебро прогноз
- Мечел акции прогноз. Цена MTLR
- АЛРОСА акции прогноз. Цена ALRS
- Геополитика, Швейцарский Цифровой Франк и Инсайдерская Торговля: Обзор Ключевых Событий Недели (08.04.2026 13:45)
- Российский рынок: между нефтью, рублем и геополитикой: обзор ключевых трендов и перспектив (04.04.2026 01:32)
- XLP против VDC: Более низкие комиссии или более широкое покрытие?
- ЭсЭфАй акции прогноз. Цена SFIN
- Группа Аренадата акции прогноз. Цена DATA
- Стоит ли покупать доллары за новозеландские доллары сейчас или подождать?
2026-02-16 23:32