Автор: Денис Аветисян
Новый подход позволяет роботам надежно выполнять сложные задачи манипулирования, несмотря на неточности в данных и ограниченные ресурсы.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал![Предложенная система решает проблему несоответствия распределений данных посредством трех последовательных этапов: расширения обучающей выборки с использованием эвристического алгоритма DAgger и пространственно-временной аугментации на этапе [latex]P_{\text{train}}[/latex], объединения взаимодополняющих политик в весовом пространстве с учетом специфики этапа при помощи Model Arithmetic на этапе [latex]Q_{\text{model}}[/latex], и обеспечения точности выполнения посредством временного сглаживания и закрытого циклического улучшения на основе DAgger на этапе [latex]P_{\text{test}}[/latex].](https://arxiv.org/html/2602.09021v1/x1.png)
Предлагается фреймворк χ0, использующий арифметику моделей и выравнивание данных для улучшения производительности в задачах долгосрочного манипулирования, в частности, при работе с одеждой.
Несмотря на значительные успехи в робототехнике, надежное выполнение сложных манипуляций в реальном мире остается сложной задачей, требующей больших объемов данных и вычислительных ресурсов. В данной работе, озаглавленной ‘$χ_{0}$: Resource-Aware Robust Manipulation via Taming Distributional Inconsistencies’, предлагается новый подход, направленный на преодоление несоответствия между данными, используемыми для обучения, и реальными условиями эксплуатации робота. Ключевым результатом является разработка фреймворка \chi_{0}, использующего методы слияния моделей, адаптации к этапам задачи и аугментации данных для достижения высокой надежности в задачах манипулирования одеждой. Сможет ли предложенный подход стать основой для создания действительно автономных роботов, способных к сложным манипуляциям в динамичной среде?
Системы Раскрываются: Неустойчивость в Обучении Роботов
Традиционные методы обучения с подкреплением часто сталкиваются с серьезными трудностями при применении к реальным робототехническим задачам. Сложность заключается в том, что роботы, обученные в контролируемой среде, демонстрируют неустойчивую работу при столкновении с незнакомыми условиями и непредвиденными ситуациями. Это связано с тем, что алгоритмы, как правило, оптимизируются для конкретного набора параметров и ограничений, и даже незначительные отклонения от этих условий могут привести к существенному снижению производительности или даже к полной неработоспособности. В отличие от симуляций, реальный мир характеризуется шумом, неопределенностью и непредсказуемостью, что делает задачу обучения роботов надежным выполнением задач особенно сложной и требующей новых подходов к обучению и адаптации.
Существенная проблема в обучении роботов заключается в ограниченной способности обобщать полученные навыки на новые, незнакомые условия и задачи. Эта сложность усугубляется так называемыми «сдвигами распределений» — изменениями в данных, которые робот встречает во время реальной эксплуатации, отличающимися от тех, на которых он обучался. Представьте, что робот научился собирать объекты при идеальном освещении, но затем его помещают в слабоосвещенную среду — это пример сдвига распределений. В результате, робот, успешно работавший в лабораторных условиях, может столкнуться с серьезными трудностями и ошибками в реальном мире, поскольку его алгоритмы, основанные на изначальном распределении данных, оказываются непригодными к обработке новой информации. Решение этой проблемы требует разработки методов, способных адаптироваться к изменениям и обеспечивать устойчивую работу робота в разнообразных и непредсказуемых ситуациях.
Несоответствие между условиями обучения и реальной эксплуатацией роботов представляет собой серьезную проблему, приводящую к хрупкости и потенциальным катастрофическим сбоям. Различия в освещении, текстуре объектов, незначительные изменения в окружающей среде или даже небольшие отклонения в механике робота могут существенно повлиять на эффективность обученной модели. Это несоответствие, известное как смещение распределений, заставляет робота действовать некорректно в ситуациях, которые лишь незначительно отличаются от тех, что были представлены во время тренировки. В результате, робот, успешно выполнявший задачу в лабораторных условиях, может потерпеть неудачу или даже повредить себя или окружающую среду в реальном мире, подчеркивая необходимость разработки более устойчивых и адаптивных алгоритмов обучения.
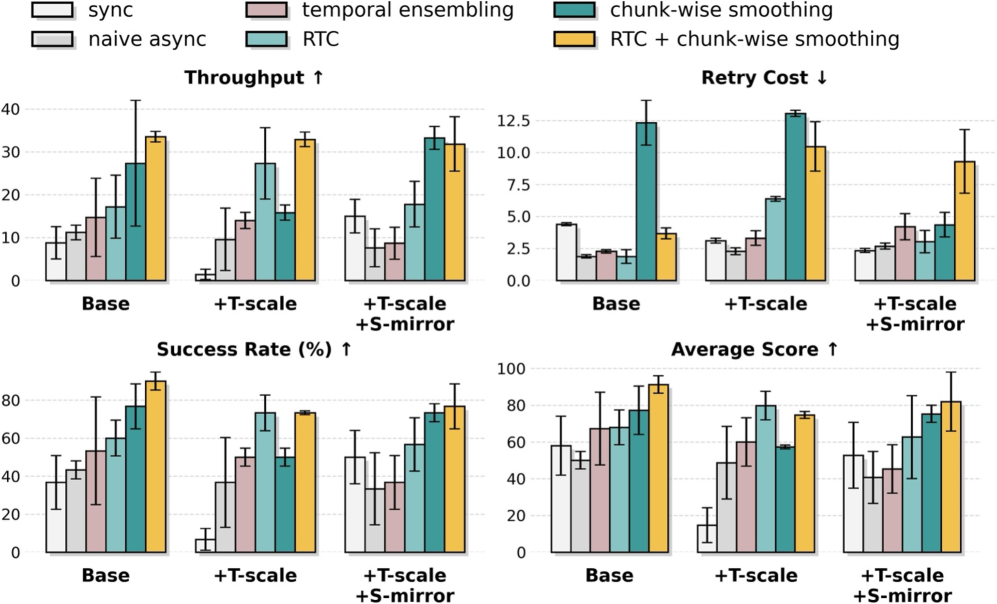
Стабилизация Обучения: Преимущество Этапа
Для преодоления нестабильности в задачах с горизонтом планирования, мы используем функцию преимущества (Advantage Function), которая оценивает выгоду от выполнения конкретного действия по сравнению с ожидаемой наградой. A(s,a) = Q(s,a) - V(s), где Q(s,a) — ожидаемая кумулятивная награда за выполнение действия ‘a’ в состоянии ‘s’, а V(s) — оценка ожидаемой кумулятивной награды в состоянии ‘s’. Оценка преимущества позволяет агенту сосредоточиться на действиях, которые превосходят среднее ожидание, что способствует более эффективному обучению и повышает стабильность процесса, особенно в задачах, где награда может быть отложена во времени.
Стабильность обучения в задачах с длинным горизонтом достигается за счет использования Stage Advantage (SA), которое предоставляет устойчивые сигналы обучения посредством включения метки, учитывающей стадию выполнения задачи. SA снижает проблемы, связанные с временным несоответствием и отложенным вознаграждением. Как показано на Рисунке 8, применение SA значительно повышает числовую стабильность, измеряемую коэффициентом Smooth Frame Ratio (SFR), что свидетельствует о более плавном и предсказуемом процессе обучения.
Применение данного подхода позволяет повысить числовую стабильность обучения робота и эффективно осваивать задачи с расширенным горизонтом планирования, даже в условиях высокой сложности. Это достигается за счет обеспечения более устойчивых градиентов и предотвращения проблем, связанных с затуханием или взрывом сигналов во время обучения. Улучшенная стабильность позволяет алгоритму эффективно распространять информацию о вознаграждении на большие расстояния во времени, что критически важно для успешного освоения сложных последовательностей действий и достижения долгосрочных целей. Особенно заметно это проявляется в задачах, требующих планирования на несколько шагов вперед и учета множества факторов.
![Анализ влияния различных компонентов SA показал, что он обеспечивает лучшую числовую стабильность и частоту успешных решений (SFR) по сравнению с базовым методом [latex]\pi_{0.6} <i> \pi^</i>_{0.6}[/latex], при этом даже упрощенный вариант Direct advantage демонстрирует стабильно лучшие результаты.](https://arxiv.org/html/2602.09021v1/x14.png)
Расширение Охвата: Аугментация и Слияние Политик
Недостаточное количество обучающих данных, приводящее к дефициту покрытия (Coverage Deficiency), существенно ограничивает способность робота эффективно функционировать в разнообразных ситуациях. Это связано с тем, что модели машинного обучения, используемые для управления роботом, обобщают знания на основе представленных данных. Если обучающая выборка не охватывает весь спектр возможных сценариев, робот может демонстрировать неустойчивое поведение или полную неспособность к действиям в ранее не встреченных условиях. Дефицит покрытия проявляется в снижении надежности и предсказуемости работы робота при столкновении с новыми, нетипичными обстоятельствами, что критически важно для приложений, требующих высокой степени автономности и безопасности.
Для расширения обучающего набора данных и повышения обобщающей способности робота используется метод пространственно-временной аугментации (Spatio-Temporal Augmentation). Данный подход предполагает создание новых обучающих примеров путем модификации существующих данных. Пространственная аугментация включает в себя изменение положения и ориентации объектов в сцене, а также внесение небольших изменений в визуальные характеристики. Временная аугментация заключается в варьировании скорости и продолжительности действий, а также в добавлении небольших случайных задержек. Комбинация этих методов позволяет создать более разнообразный набор данных, что способствует улучшению устойчивости и адаптивности робота к различным условиям и сценариям.
Метод арифметики моделей (Model Arithmetic, MA) предполагает объединение политик, обученных на взаимодополняющих наборах данных, с целью расширения области охвата и снижения предвзятости в полученном поведении робота. Принцип работы MA заключается в линейной комбинации параметров отдельных моделей, что позволяет создать новую политику, объединяющую сильные стороны каждой из исходных. В частности, если \theta_1 и \theta_2 — параметры двух обученных политик, то новая политика \theta_{MA} вычисляется как \theta_{MA} = \alpha \theta_1 + (1 - \alpha) \theta_2 , где α — коэффициент, определяющий вклад каждой политики. Использование MA позволяет эффективно использовать существующие данные и снизить потребность в сборе новых, что особенно актуально для задач с ограниченными ресурсами.
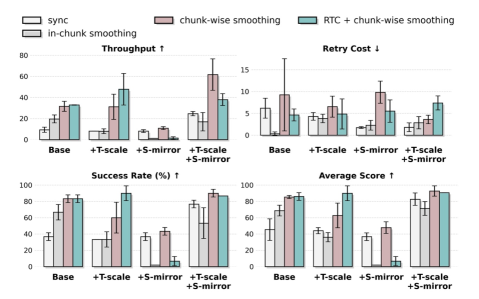
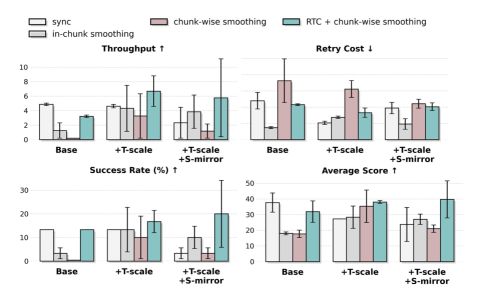
Соединение Реальности и Симуляции: Выравнивание Train-Deploy
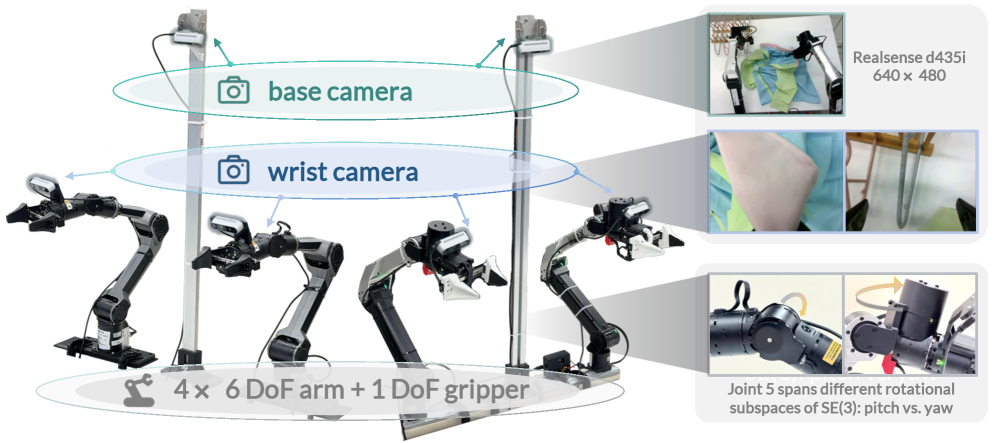
Манипулирование одеждой представляет собой сложную задачу для робототехники, требующую от систем не только точного контроля движений, но и способности адаптироваться к постоянно меняющимся свойствам ткани и ее деформации. Одежда, в отличие от жестких объектов, характеризуется высокой степенью податливости, непредсказуемым поведением и зависимостью от внешних факторов, таких как трение и гравитация. Это создает значительные трудности для роботов, которым необходимо учитывать эти факторы для успешного выполнения задач, будь то складывание одежды, надевание ее на человека или выполнение других операций. Успешное овладение подобными навыками требует от робота способности к тактильному восприятию, визуальному анализу и оперативной корректировке траектории движения, что делает манипулирование одеждой важным этапом в развитии интеллектуальных робототехнических систем.
Разработанная методика Train-Deploy-Alignment (TDA) представляет собой комплексный подход к преодолению разрыва между обучением робота в симуляции и его применением в реальном мире. В основе TDA лежит сочетание алгоритма Heuristic DAgger, направленного на улучшение устойчивости политики к отклонениям, техник пространственно-временной аугментации, расширяющих вариативность обучающих данных, и алгоритма временного поблочного сглаживания, позволяющего уменьшить накопление ошибок при выполнении сложных манипуляций. Такой интегрированный подход позволяет эффективно адаптировать поведение робота к неопределенностям реальной среды, обеспечивая надежную и точную работу при выполнении задач, связанных с манипулированием одеждой, и существенно снижая вероятность каскадных сбоев в процессе выполнения.
Полученные результаты демонстрируют значительный прогресс в области манипулирования одеждой роботами. Применение разработанной методики позволило добиться почти 250%-ного увеличения успешности выполнения совместных задач по работе с одеждой по сравнению с общедоступным алгоритмом π0.5. Это свидетельствует о повышенной надежности и стабильности системы, способной минимизировать каскадные ошибки и максимизировать вероятность успешного завершения задачи. Подобное улучшение открывает новые возможности для автоматизации процессов в текстильной промышленности и робототехнике, где требуется точное и адаптивное взаимодействие с мягкими и деформируемыми объектами.
Будущее Интеллекта Роботов: Выращивание, а не Конструирование
Робототехнические фундаментальные модели, предварительно обученные на огромных массивах данных, представляют собой перспективный путь к созданию действительно универсального искусственного интеллекта для роботов. В отличие от традиционных подходов, где каждый робот программируется для выполнения конкретной задачи, эти модели способны к обобщению знаний, полученных из разнообразных источников. Подобно тому, как большие языковые модели освоили понимание и генерацию текста, робототехнические модели могут научиться выполнять широкий спектр манипуляций и взаимодействий с окружающей средой, адаптируясь к новым ситуациям без необходимости перепрограммирования. Этот подход открывает возможности для создания роботов, способных самостоятельно решать сложные задачи в непредсказуемых условиях, что является ключевым шагом на пути к созданию по-настоящему автономных и полезных роботизированных систем.
Метод сопоставления потоков, или Flow Matching, представляет собой передовой подход к обучению роботов, позволяющий эффективно адаптировать предварительно обученные модели к новым задачам. В отличие от традиционных методов, требующих значительных вычислительных ресурсов и времени, Flow Matching обеспечивает быструю и стабильную тонкую настройку моделей, используя относительно небольшие наборы данных. Ключевым фактором успеха является использование мощного оборудования, такого как графический процессор A100, который существенно ускоряет процесс обучения и позволяет обрабатывать сложные задачи, связанные с восприятием и управлением роботами. Благодаря сочетанию эффективности алгоритма и высокой производительности аппаратного обеспечения, Flow Matching открывает новые возможности для создания универсальных и адаптивных робототехнических систем, способных решать широкий спектр задач в различных условиях.
Разработка действительно адаптивных роботов требует комплексного подхода, включающего принципы устойчивого обучения, расширения данных и выравнивания. Устойчивое обучение позволяет роботам сохранять работоспособность в условиях неопределенности и помех, а расширение данных — эффективно использовать ограниченные наборы данных, генерируя дополнительные примеры, которые повышают обобщающую способность. Ключевым является также выравнивание — процесс, гарантирующий, что цели робота соответствуют человеческим намерениям и ценностям. Интеграция этих трех компонентов позволяет создавать роботов, способных не просто выполнять заданные задачи, но и гибко реагировать на изменения окружающей среды, учиться на собственном опыте и эффективно решать сложные проблемы, возникающие в динамических условиях реального мира.
Представленная работа демонстрирует подход к решению проблемы несоответствия распределений в обучении роботов, что является ключевым аспектом достижения надежного управления. Вместо попыток построить идеальную систему, авторы предлагают методы, позволяющие «вырастить» устойчивость за счет адаптации к неточностям и вариативности данных. Как заметил Клод Шеннон: «Теория коммуникации изучает точность, с которой можно передавать информацию, а также пределы этой точности». Аналогично, χ0 фокусируется на преодолении расхождений в распределениях данных, чтобы обеспечить надежное выполнение сложных задач манипулирования, признавая, что абсолютная точность недостижима, а важно уметь справляться с неизбежными погрешностями и несоответствиями.
Что дальше?
Представленная работа, стремясь укротить расхождения в распределениях данных, напоминает попытку наладить диалог с непостоянной рекой. Каждый успех в согласовании моделей — это лишь временное перемирие, ведь поток новых данных неизбежно принесёт новые искажения. Не стоит обольщаться иллюзией контроля; любые гарантии производительности — это, по сути, соглашение об уровне обслуживания, заключенное с хаосом.
Полагаться на искусственное выравнивание распределений — значит, строить плотину, которая рано или поздно рухнет под напором реальности. Гораздо перспективнее искать способы, позволяющие системам самовосстанавливаться, адаптироваться к изменениям, словно живые организмы. Каждая зависимость от конкретного набора данных — это обещание, данное прошлому, которое, возможно, окажется невыполнимым в будущем.
Настоящий прогресс лежит не в совершенствовании алгоритмов, а в создании экосистем, где модели учатся друг у друга, делятся опытом и совместно эволюционируют. Ведь всё, что построено, когда-нибудь начнёт само себя чинить — если, конечно, мы позволим ему это сделать, отказавшись от навязчивого стремления к абсолютному контролю.
Оригинал статьи: https://arxiv.org/pdf/2602.09021.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Серебро прогноз
- Мечел акции прогноз. Цена MTLR
- Группа Аренадата акции прогноз. Цена DATA
- АЛРОСА акции прогноз. Цена ALRS
- Крипто-археология: Стратегии накопления в эпоху волатильности и хакерских угроз (06.04.2026 16:45)
- Российский рынок: между нефтью, рублем и геополитикой: обзор ключевых трендов и перспектив (04.04.2026 01:32)
- Будущее CRV: прогноз цен на криптовалюту CRV
- XLP против VDC: Более низкие комиссии или более широкое покрытие?
- Разделение акций: История одного триумфа и ожидания другого
2026-02-11 02:02