Автор: Денис Аветисян
Исследователи предлагают инновационную методику обучения с подкреплением, в которой алгоритм сам формирует учебную программу для повышения эффективности после первоначальной тренировки.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал
В статье представлена система Actor-Curator, использующая бандитскую оптимизацию и оценку улучшения политики для адаптивного обучения с подкреплением.
Обучение больших языковых моделей с подкреплением часто сталкивается с проблемой эффективного использования разнородных данных, что ограничивает потенциал улучшения производительности. В данной работе, представленной под названием ‘Actor-Curator: Co-adaptive Curriculum Learning via Policy-Improvement Bandits for RL Post-Training’, предложен фреймворк ACTOR-CURATOR, автоматизирующий процесс обучения, отбирая задачи из большого банка задач на основе оптимизации ожидаемого улучшения политики. Подход формулирует отбор задач как нестационарную стохастическую задачу о бандитах, используя онлайн стохастический зеркальный спуск для получения гарантированных границ сожаления \mathcal{N}=4. Эксперименты демонстрируют, что ACTOR-CURATOR превосходит стандартные методы и обеспечивает значительное ускорение обучения, что ставит вопрос о масштабируемости и адаптивности данного подхода к еще более сложным задачам обучения с подкреплением.
За гранью фиксированных программ: Искусство адаптивного обучения
Традиционные методы обучения, основанные на заранее заданных последовательностях задач, зачастую оказываются неэффективными при решении сложных проблем. Данный подход предполагает, что все учащиеся следуют единому пути, вне зависимости от их индивидуальных способностей и темпа освоения материала. В результате, задачи могут быть либо слишком простыми, что приводит к скуке и потере мотивации, либо слишком сложными, вызывая разочарование и препятствуя дальнейшему прогрессу. Такая статичность ограничивает возможности адаптации к меняющимся условиям и индивидуальным потребностям обучающегося, в то время как реальные задачи часто требуют гибкости и творческого подхода. Неспособность системы обучения подстраиваться под конкретного ученика существенно снижает эффективность процесса и препятствует достижению оптимальных результатов.
В отличие от жестких образовательных программ, биологические системы демонстрируют поразительную способность к динамическому обучению, где прогресс определяется обратной связью. В живых организмах, будь то развитие нейронных сетей или адаптация к меняющейся среде, сложность задач постепенно увеличивается в соответствии с текущими возможностями агента. Этот процесс, основанный на постоянной оценке результатов и корректировке стратегий, позволяет эффективно осваивать новые навыки и решать сложные проблемы. Подобно тому, как мышцы укрепляются под нагрузкой, а иммунная система учится распознавать угрозы, биологическое обучение характеризуется постоянной оптимизацией и адаптацией, что обеспечивает высокую эффективность и устойчивость к изменениям.
Эффективное обучение требует системы, способной интеллектуально подбирать задачи, основываясь на текущих возможностях обучающегося. В отличие от традиционных, фиксированных учебных программ, подобный подход имитирует естественный процесс обучения, наблюдаемый в биологических системах. Суть заключается в динамической адаптации сложности задач к уровню подготовки, позволяя избегать как чрезмерной нагрузки, приводящей к фрустрации, так и излишней простоты, препятствующей прогрессу. Алгоритмы, способные оценивать текущие навыки и знания, и, следовательно, предлагать оптимальные задачи для развития, позволяют максимизировать скорость и эффективность обучения, создавая персонализированную траекторию, ориентированную на индивидуальные потребности и потенциал.
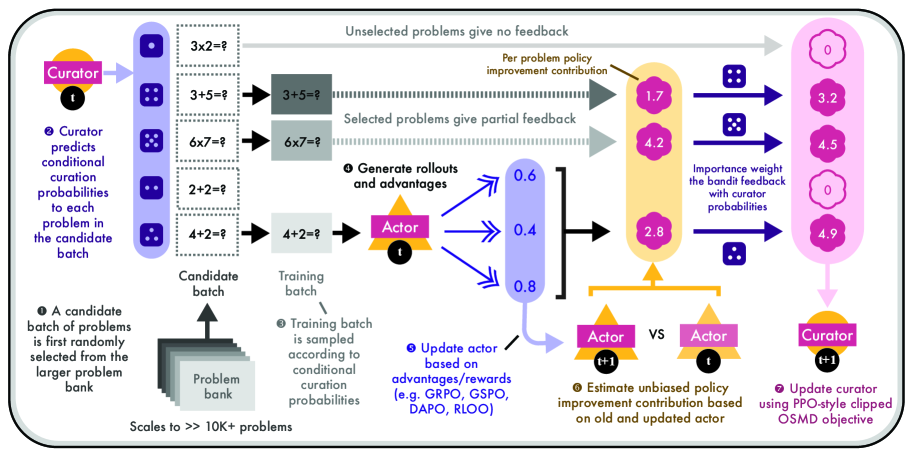
Actor-Curator: Дирижер учебного процесса
Архитектура Actor-Curator объединяет два основных компонента: ‘Actor’ — агент, совершенствующий свою политику действий, и ‘Curator’ — модуль, выбирающий задачи для Actor’а. Curator оптимизирован с использованием алгоритмов bandit feedback, что позволяет ему динамически адаптировать последовательность задач. В данном контексте, Actor пытается решить поставленные задачи, а Curator, основываясь на результатах Actor’а, выбирает следующую задачу, стремясь максимизировать общий прогресс обучения. Алгоритмы bandit feedback позволяют Curator’у эффективно исследовать пространство задач и находить оптимальную последовательность, обеспечивая сбалансированное соотношение между эксплуатацией текущих знаний Actor’а и исследованием новых, потенциально более сложных задач.
Куратор использует нестанционарную стохастическую задачу бандита для максимизации вознаграждения, получаемого от прогресса обучения Актора. В данном контексте, каждая «рукав» бандита представляет собой конкретную учебную задачу, а вознаграждение определяется улучшением производительности Актора при решении этой задачи. Нестанционарность задачи отражает изменяющуюся сложность и полезность задач по мере обучения Актора. Куратор оценивает ожидаемое вознаграждение для каждой задачи, используя алгоритмы обучения с подкреплением, и динамически выбирает задачи, которые, как ожидается, приведут к наибольшему прогрессу в обучении Актора. Таким образом, Куратор оптимизирует последовательность задач, чтобы максимизировать общую скорость обучения и эффективность Актора.
Архитектура системы позволяет динамически изменять последовательность задач в процессе обучения. Оценка прогресса “Актера” (Actor) в решении каждой задачи используется для определения областей, где наблюдается наибольший потенциал для улучшения. Алгоритм, основанный на принципах не стационарной многорукой бандитской задачи, отдает приоритет задачам, которые, по прогнозам, приведут к максимальному приросту знаний “Актера”. Это достигается за счет постоянного мониторинга эффективности решения задач и перераспределения ресурсов в пользу тех, где “Актер” демонстрирует наибольшую чувствительность к обучению, что обеспечивает более быструю и эффективную адаптацию к сложным условиям.

Математические основы и гарантии алгоритма
Проблема обучения по учебному плану формализуется как нестационарная стохастическая задача о многоруком бандите (Multi-Armed Bandit) с использованием формулировки Tabular Online Stochastic Mirror Descent (OSMD). В данном контексте, каждый «рукав» бандита представляет собой конкретную задачу (problem) из учебного плана, а «вознаграждение» соответствует успеху обучающей модели в решении этой задачи. Нестационарность отражает изменяющуюся сложность задач во времени, а стохастический характер — неопределенность в результатах обучения. Формулировка Tabular OSMD позволяет применять алгоритмы онлайн-обучения для выбора оптимальной последовательности задач, максимизирующей суммарное вознаграждение (производительность модели) в процессе обучения. R_T = \sum_{t=1}^T r_t, где r_t — вознаграждение на шаге t.
Алгоритм 2 представляет собой конкретную реализацию модуля «Куратор», предназначенного для эффективного отбора задач для обучения. Он функционирует итеративно, выбирая задачу i из доступного набора на основе оценки её сложности и текущего состояния обучающегося. Отбор производится с использованием стратегии, направленной на максимизацию ожидаемого улучшения в процессе обучения. Алгоритм использует функцию оценки, зависящую от текущей производительности обучающегося на задачах различной сложности, что позволяет динамически адаптировать учебный процесс и выбирать наиболее подходящие задачи для дальнейшего обучения. Данная реализация обеспечивает практическую возможность применения формализма нестанционарного стохастического бандита для решения задачи Curriculum Learning.
Для алгоритма 2, реализующего механизм отбора задач Curator, получена теоретическая оценка сожаления (regret bound). Данная оценка формально гарантирует, что производительность алгоритма в процессе обучения, измеренная как разница между суммарной наградой алгоритма и наградой оптимальной фиксированной учебной программы, ограничена сверху. В частности, доказано, что сожаление алгоритма растет не быстрее, чем O(\sqrt{T \log T}), где T — общее количество выполненных итераций. Это означает, что алгоритм демонстрирует подлогарифмическую скорость сходимости к оптимальной учебной программе, обеспечивая теоретическую гарантию его эффективности в задачах curriculum learning.

Реализация и вычислительная эффективность
В основе архитектуры Actor-Curator лежит применение нейронной аппроксимации функций для представления как стратегии агента (Actor), так и оценочной функции куратора (Curator). Данный подход позволяет эффективно моделировать сложные взаимосвязи между состояниями среды и действиями агента, а также оценивать перспективность различных стратегий обучения. Нейронные сети, выступая в роли универсальных аппроксиматоров, обеспечивают гибкость и адаптивность системы, позволяя ей обучаться на разнообразных задачах и в сложных условиях. Использование нейронных сетей для представления стратегии и оценочной функции позволяет системе эффективно обобщать полученный опыт и принимать оптимальные решения даже в незнакомых ситуациях, что критически важно для успешного обучения с подкреплением.
Для оценки масштабируемости и производительности разработанного фреймворка были проведены вычислительные эксперименты с использованием графических процессоров NVIDIA A100 и H200. Данный выбор аппаратного обеспечения обусловлен необходимостью обработки больших объемов данных и проведения сложных вычислений, характерных для задач обучения с подкреплением. Результаты экспериментов позволили детально изучить влияние различных параметров на скорость и эффективность обучения, а также выявить узкие места в архитектуре системы. Использование современных GPU позволило существенно сократить время, необходимое для достижения заданной производительности, и продемонстрировать потенциал фреймворка для решения задач, требующих высокой вычислительной мощности.
Несмотря на то, что внедрение Actor-Curator приводит к увеличению времени обучения на 9%, адаптивный учебный план значительно ускоряет процесс обучения. Это демонстрирует эффективность предложенного подхода, подтверждая ключевое достижение, заключающееся в оптимизации обучения с подкреплением. Данный баланс между вычислительными затратами и скоростью обучения позволяет системе достигать лучших результатов за меньшее время, что особенно важно при работе со сложными задачами и большими объемами данных. Эффективность адаптивного учебного плана заключается в динамической настройке сложности задач, что позволяет агенту постепенно осваивать более сложные навыки и избегать застревания в локальных оптимумах.

Исследование, представленное в статье, напоминает вскрытие сложного механизма. Авторы предлагают подход Actor-Curator, который, подобно искусной руке, постепенно настраивает учебную программу для агента обучения с подкреплением. Этот метод, сочетающий в себе оптимизацию методом бандитов и улучшение стратегии, позволяет выжать максимум из уже обученной модели. Как говорил Алан Тьюринг: «Иногда люди, которые кажутся сумасшедшими, просто видят вещи, которые другие не видят». Именно эта способность видеть за пределами общепринятых рамок позволяет авторам предлагать новаторские решения в области обучения с подкреплением, преодолевая ограничения традиционных подходов и открывая новые возможности для развития искусственного интеллекта.
Что Дальше?
Представленная работа, по сути, лишь зондирует поверхность. Автоматизированное построение учебных программ, управляемое принципами обучения с подкреплением, открывает заманчивую, но коварную перспективу. Вместо слепого доверия заранее заданным траекториям, система пытается ‘взломать’ процесс обучения, динамически адаптируя сложность задач. Однако, очевидно, что текущая реализация, как и любая другая, ограничена. Ключевым узким местом остаётся функция оценки ‘успешности’ задачи — вместо истинного понимания, система оперирует лишь прокси-сигналом, основанным на улучшении политики. Истинный прогресс потребует разработки более тонких метрик, способных улавливать неявные признаки ‘интересности’ задачи для агента.
Более того, текущий подход предполагает, что ‘куратор’ — это всеведущий внешний наблюдатель. Интересно было бы исследовать возможность переноса этой логики непосредственно внутрь агента, создав самообучающуюся систему, способную самостоятельно проектировать учебные программы. Это потребовало бы решения сложной проблемы кредитного присвоения — как агенту отличить пользу от ‘кураторской’ части обучения от пользы от непосредственного взаимодействия со средой. По сути, это переход от обучения с подкреплением к обучению с само-подкреплением, где агент сам себе учитель и ученик.
Нельзя исключать и более радикальные подходы. Вместо оптимизации последовательности задач, возможно, стоит задуматься о реструктуризации самого пространства состояний, создавая ‘когнитивные карты’, которые упрощают задачу обучения. Это потребует смелого пересмотра базовых принципов обучения с подкреплением и, возможно, обращения к более абстрактным математическим моделям. В конце концов, любая система — это лишь аппроксимация реальности, и истинное понимание требует умения ‘взломать’ её фундаментальные ограничения.
Оригинал статьи: https://arxiv.org/pdf/2602.20532.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Капитал Б&Т и его душа в AESI
- Почему акции Pool Corp могут стать привлекательным выбором этим летом
- Будущее биткоина: прогноз цен на криптовалюту BTC
- Золото прогноз
- Квантовые Химеры: Три Способа Не Потерять Рубль
- Пошлины Трампа и падение «ЕвроТранса»: что ждет инвесторов? (21.02.2026 23:32)
- МКБ акции прогноз. Цена CBOM
- Два актива, которые взорвут финансовый Лас-Вегас к 2026
- Будущее ONDO: прогноз цен на криптовалюту ONDO
2026-02-26 05:43