Автор: Денис Аветисян
Исследователи предлагают инновационную методику для обучения агентов в задачах с дискретными действиями, используя данные, собранные ранее, без необходимости интерактивного взаимодействия со средой.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал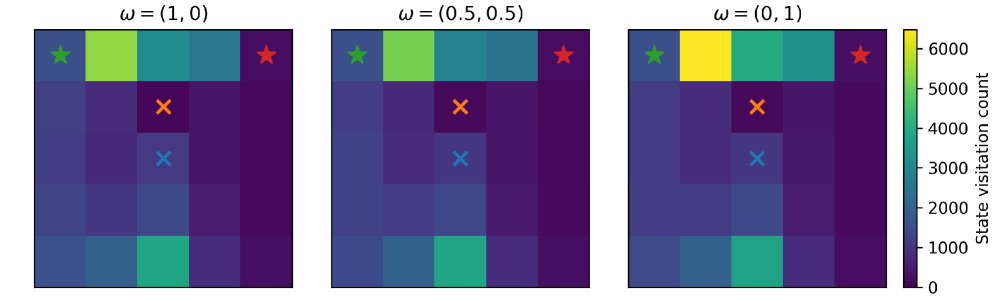
Предложен метод, основанный на Continuous-Time Markov Chains (CTMC) и Q-взвешенном flow matching, для эффективного обучения в задачах offline reinforcement learning с учетом предпочтений пользователя и в многоцелевых средах.
Несмотря на успехи методов, основанных на диффузионных моделях и flow matching в обучении с подкреплением, их применение в задачах с дискретными действиями оставалось ограниченным. В статье ‘Flow Matching for Offline Reinforcement Learning with Discrete Actions’ предложен новый подход, расширяющий возможности flow matching для работы с дискретными пространствами действий и множественными целями. В основе метода лежит использование непрерывно-временных марковских цепей (CTMC) и Q-взвешенной функции потерь, позволяющей обучать эффективные стратегии, учитывающие предпочтения пользователя. Открывает ли это путь к созданию более гибких и мощных систем обучения с подкреплением, способных адаптироваться к сложным и многогранным задачам?
Вызов автономного обучения с подкреплением
Традиционное обучение с подкреплением, краеугольный камень современного искусственного интеллекта, часто требует активного взаимодействия агента со средой. Этот процесс подразумевает постоянное выполнение действий и получение обратной связи для корректировки стратегии. Однако, подобный подход оказывается непозволительной роскошью или вовсе невозможным в ряде практических сценариев. Например, в медицине, робототехнике или управлении сложными системами, активное обучение может быть дорогостоящим, опасным или попросту нереализуемым из-за ограниченных ресурсов или риска нанесения ущерба. В таких случаях, необходимость в алгоритмах, способных эффективно обучаться без постоянной обратной связи со средой, становится особенно актуальной и определяет перспективные направления развития исследований в области искусственного интеллекта.
В отличие от традиционного обучения с подкреплением, требующего активного взаимодействия с окружающей средой, обучение с подкреплением в автономном режиме (Offline RL) использует статические наборы данных для извлечения знаний. Однако, такой подход сопряжен с серьезными трудностями, обусловленными смещением распределений (distribution shift). Поскольку алгоритм обучается на данных, собранных другой политикой, он может столкнуться с ситуациями, которых не встречалось в обучающем наборе, что приводит к непредсказуемому и нестабильному поведению. Этот феномен особенно ярко проявляется при работе с дискретными пространствами действий, где даже небольшие отклонения в распределении могут привести к существенным ошибкам и снижению эффективности обучения. Успешное применение Offline RL требует разработки алгоритмов, способных эффективно справляться с этими проблемами и гарантировать стабильное и надежное обучение на статических данных.
Успешное использование статических наборов данных в обучении с подкреплением вне сети требует алгоритмов, устойчивых к смещению распределений и нестабильности. Особенно сложной задачей является применение таких алгоритмов в дискретном пространстве действий, где даже небольшие ошибки в оценке ценности действий могут привести к значительным отклонениям от оптимальной стратегии. Разработка алгоритмов, способных эффективно экстраполировать знания из ограниченного набора данных и обобщать их на новые, ранее не встречавшиеся ситуации, является ключевой областью исследований. Это включает в себя методы регуляризации, ограничения на политику и алгоритмы, учитывающие неопределенность в оценках, чтобы обеспечить стабильность обучения и избежать нежелательных побочных эффектов, связанных с использованием данных, собранных другим агентом или в иных условиях.
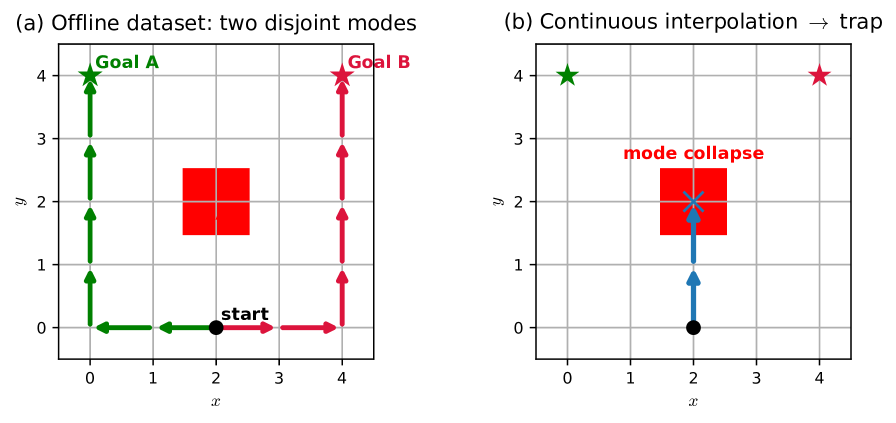
Потоковое сопоставление: генеративный подход к обучению политике
Метод Flow Matching представляет собой мощный генеративный подход к обучению сложных распределений данных, что делает его особенно подходящим для представления политик в задачах обучения с подкреплением. В отличие от традиционных генеративных моделей, Flow Matching непосредственно моделирует поле скоростей, преобразующее простое, известное распределение (например, гауссово) в целевое распределение политик. Это позволяет избежать проблем, связанных с нестабильностью обучения и сложностью выборки, характерных для вариационных автоэнкодеров и генеративно-состязательных сетей. По сути, Flow Matching преобразует задачу обучения политики в задачу обучения непрерывного потока, что обеспечивает более стабильный и эффективный процесс обучения, особенно при работе с данными из `OfflineDataset`.
Метод Flow Matching обходит типичные недостатки других генеративных моделей, моделируя поле скоростей, которое преобразует простое распределение в целевое распределение политики. В отличие от подходов, требующих прямого моделирования сложного целевого распределения, Flow Matching фокусируется на изучении непрерывного преобразования из простого, известного распределения (например, стандартного нормального) в распределение политики. Это позволяет избежать проблем, связанных с оценкой плотности вероятности в высокоразмерных пространствах, и повышает стабильность обучения, поскольку процесс обучения сводится к прогнозированию вектора скорости, определяющего направление движения в фазовом пространстве. Такой подход обеспечивает более эффективное и надежное обучение политик, особенно в задачах обучения с подкреплением из оффлайн-данных.
Эффективность Flow Matching напрямую зависит от способности алгоритма использовать данные из `OfflineDataset` для обучения трансформации распределений и обобщать полученные знания на ранее не встречавшиеся состояния. Ключевым аспектом является качество и репрезентативность этого набора данных, поскольку он определяет, насколько точно можно смоделировать целевое распределение политики. Успешное обобщение на невидимые состояния требует, чтобы обученное преобразование было устойчиво к вариациям входных данных и не переобучалось на специфические особенности `OfflineDataset`. Недостаточное покрытие состояний в наборе данных или низкая его достоверность могут привести к снижению производительности алгоритма при работе в реальных условиях.
QDFM: преодолевая разрыв для дискретных пространств действий
Q-взвешенное дискретное сопоставление потоков (QDFM) решает проблему применения сопоставления потоков к дискретным пространствам действий путем интеграции Q-функции. Традиционное сопоставление потоков, предназначенное для непрерывных пространств, сталкивается с трудностями при обработке дискретных действий из-за отсутствия дифференцируемости. QDFM обходит это ограничение, используя Q-функцию для оценки качества каждого дискретного действия в данном состоянии. Это позволяет алгоритму направлять процесс сопоставления потоков к действиям с более высокой ожидаемой наградой, эффективно преодолевая разрыв между непрерывной оптимизацией потоков и дискретными пространствами действий. Таким образом, QDFM обеспечивает возможность обучения политики на основе данных, даже в сложных средах с дискретными вариантами действий.
QDFM использует непрерывную цепь Маркова (CTMC) для моделирования политики и выбора действий, что обеспечивает допустимое и эффективное исследование пространства действий. В CTMC, вероятности переходов между состояниями определяются функцией Q, которая оценивает ожидаемую выгоду от выполнения конкретного действия в определенном состоянии. Это позволяет алгоритму последовательно выбирать действия, максимизирующие долгосрочную награду, избегая при этом случайных или невалидных действий, характерных для дискретных пространств. Использование CTMC обеспечивает плавный и управляемый процесс исследования, что особенно важно для сложных задач с многомерными дискретными пространствами действий, поскольку гарантирует, что каждое действие является логичным продолжением текущей стратегии.
Метод QDFM (Q-weighted Discrete Flow Matching) позволяет эффективно обучать политику на основе оффлайн-данных, даже в задачах с дискретным и сложным пространством действий. Комбинируя Flow Matching с Q-функцией и Continuous-Time Markov Chain (CTMC), QDFM обеспечивает возможность обучения в задачах с несколькими целевыми функциями, демонстрируя передовые результаты по сравнению с существующими алгоритмами. Использование CTMC позволяет моделировать политику и осуществлять выбор действий, обеспечивая эффективное исследование пространства действий. Данный подход особенно актуален в задачах, где получение данных в реальном времени затруднено или нецелесообразно.
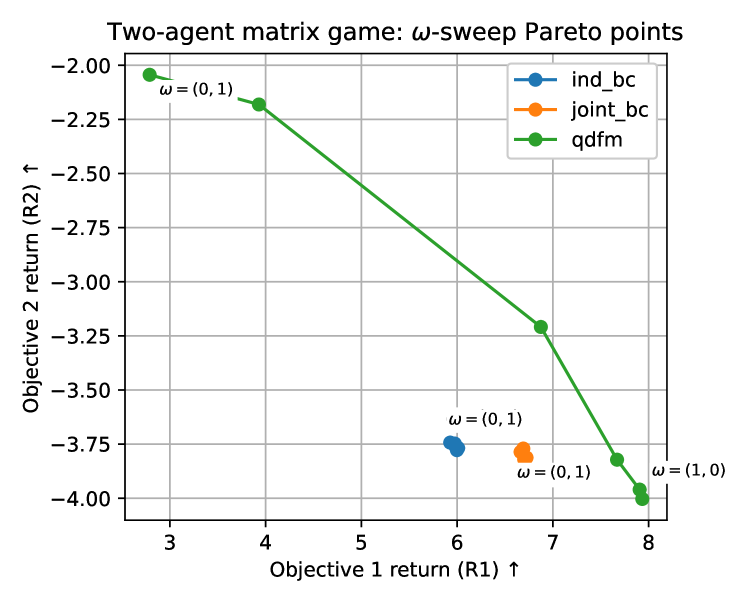
Улучшение обучения политике с помощью контрастного предсказания
Алгоритм QDFM использует предсказание контрастивной энергии для существенного улучшения процесса обучения политики, направляя его к оптимальным действиям. В основе этого подхода лежит идея оценки различий между потенциальными действиями и их последствиями, что позволяет более эффективно определять наиболее выгодные стратегии. Вместо простого предсказания вознаграждения, система учится различать «хорошие» и «плохие» состояния, используя контрастивный сигнал. Это, в свою очередь, позволяет алгоритму быстрее сходиться к оптимальной политике, особенно в сложных средах, где прямое оценивание вознаграждения может быть затруднено или неполным. Использование контрастивного подхода повышает стабильность обучения и позволяет QDFM достигать лучших результатов в задачах, требующих долгосрочного планирования и адаптации к меняющимся условиям.
В рамках алгоритма QDFM, ключевым аспектом повышения эффективности обучения является разработка и использование функции энергии, способной точно отражать ценность различных состояний и действий. Эта функция позволяет алгоритму более эффективно оценивать перспективность различных стратегий, что существенно снижает потребность в большом количестве проб и ошибок — повышая, таким образом, скорость обучения. Точное определение ценности состояний и действий также способствует стабилизации процесса обучения, предотвращая резкие колебания и обеспечивая более плавное схождение к оптимальному решению. В результате, QDFM демонстрирует повышенную устойчивость и надежность даже в сложных и динамичных средах, где традиционные методы обучения могут столкнуться с трудностями.
В рамках совершенствования алгоритмов обучения с подкреплением, использование расхождения Брегмана в процессе предсказания энергии позволяет сформировать надежную и четко определенную метрику улучшения политики. Данный подход обеспечивает более устойчивое обучение, особенно в сложных средах сбора ресурсов, где требуется оптимизация нескольких параметров одновременно. В частности, применение расхождения Брегмана способствует расширению парето-фронта, что означает возможность достижения более разнообразных и эффективных стратегий сбора ресурсов. D_{\phi}(x, y) — расхождение Брегмана измеряет «расстояние» между состояниями или действиями, позволяя алгоритму более точно оценивать их ценность и выбирать оптимальные решения для достижения поставленных целей. Такой подход обеспечивает не только повышение эффективности, но и улучшение стабильности процесса обучения, позволяя алгоритму адаптироваться к меняющимся условиям окружающей среды.
За пределами единичных целей: к многоаспектному управлению
Алгоритм QDFM демонстрирует естественное расширение возможностей в контексте обучения с подкреплением для множественных целей (MultiObjectiveRL). В отличие от традиционных подходов, ориентированных на максимизацию единственной функции вознаграждения, QDFM позволяет агенту одновременно оптимизировать несколько, потенциально конфликтующих, целей. Это достигается за счет разработки политик, способных находить компромиссы и баланс между различными задачами, что особенно важно в сложных сценариях, где требуется учитывать множество факторов. Способность к адаптации к различным приоритетам и достижению оптимального решения в условиях противоречивых целей делает QDFM перспективным инструментом для создания интеллектуальных систем, способных решать широкий спектр задач, требующих многоаспектного подхода.
Алгоритм QDFM обладает уникальной способностью к адаптации благодаря механизму “условного предпочтения пользователя”. Этот подход позволяет настраивать поведение системы в соответствии с конкретными требованиями и желаемыми результатами. В ходе исследований было установлено, что, акцентируя внимание на вознаграждении за выполнение задачи, алгоритм демонстрирует почти идеальную координацию действий. Такая гибкость открывает возможности для создания персонализированных систем искусственного интеллекта, способных эффективно решать сложные задачи в различных областях, от управления ресурсами до автоматизации производственных процессов, обеспечивая высокую степень соответствия ожиданиям пользователя.
Алгоритм QDFM демонстрирует значительный потенциал в создании адаптивных и персонализированных систем искусственного интеллекта, применимых в широком спектре задач. Его гибкость позволяет не просто достигать поставленных целей, но и подстраиваться под специфические требования и предпочтения пользователя. Практические испытания, в частности, в задачах по сбору ресурсов, показали улучшение средней возвращаемой прибыли, что подтверждает эффективность QDFM в оптимизации процессов и повышении продуктивности. Данная способность к адаптации делает QDFM перспективным инструментом для разработки интеллектуальных систем, способных к самообучению и оптимизации своей работы в динамично меняющихся условиях.
Исследование, представленное в статье, демонстрирует закономерную эволюцию систем обучения с подкреплением. Подход, основанный на Continuous-Time Markov Chains (CTMC) и взвешенном соответствии потоков, позволяет создавать более устойчивые и адаптивные алгоритмы, способные учитывать сложные дискретные пространства действий. Как заметила Барбара Лисков: «Хорошая абстракция — это, прежде всего, способ организации программы, который позволяет ей меняться с минимальными затратами». Эта мысль находит отражение в предложенном фреймворке, который обеспечивает гибкость и расширяемость, позволяя адаптироваться к различным задачам и условиям, а также учитывать многоцелевую оптимизацию. Очевидно, что системы стареют, и предложенный подход направлен на то, чтобы обеспечить их достойное долголетие в постоянно меняющейся среде.
Куда же дальше?
Представленная работа, стремясь обуздать дискретные пространства действий в обучении с подкреплением оффлайн, неизбежно обнажает границы текущего понимания. Каждый сбой в сходимости, каждая неточность в аппроксимации — это сигнал времени, напоминание о том, что любая модель — лишь мгновенный снимок сложной, динамичной реальности. Использование непрерывных цепей Маркова (CTMC) как инструмента для моделирования дискретных процессов — элегантное решение, но и оно не свободно от изъянов. В частности, остается открытым вопрос о масштабируемости данного подхода к задачам с чрезвычайно большим количеством состояний и действий.
Рефакторинг, в данном контексте, представляет собой диалог с прошлым. Возможность учета предпочтений пользователя и работа в многоцелевой среде — важный шаг, но требует дальнейшей проработки вопросов стабильности и надежности. Следующим этапом представляется разработка методов, позволяющих не просто адаптироваться к предпочтениям, но и предвидеть их изменения, создавая политики, способные к самообучению и эволюции.
В конечном счете, все системы стареют — вопрос лишь в том, делают ли они это достойно. Успех данного направления исследований будет определяться не только способностью создавать эффективные политики, но и умением проектировать системы, способные к долгосрочному обучению и адаптации в постоянно меняющейся среде. Отказ от упрощающих предположений и стремление к более реалистичному моделированию — вот путь, который предстоит пройти.
Оригинал статьи: https://arxiv.org/pdf/2602.06138.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Серебро прогноз
- Мечел акции прогноз. Цена MTLR
- АЛРОСА акции прогноз. Цена ALRS
- Геополитика, Швейцарский Цифровой Франк и Инсайдерская Торговля: Обзор Ключевых Событий Недели (08.04.2026 13:45)
- Российский рынок: между нефтью, рублем и геополитикой: обзор ключевых трендов и перспектив (04.04.2026 01:32)
- XLP против VDC: Более низкие комиссии или более широкое покрытие?
- Стоит ли покупать доллары за новозеландские доллары сейчас или подождать?
- Группа Аренадата акции прогноз. Цена DATA
- Осторожно: Ваш криптовалютный кошелек может привлекать вредоносный софт! 😱💰
2026-02-09 14:51