Автор: Денис Аветисян
Новый подход позволяет стабилизировать и ускорить обучение в задачах с ограничениями, адаптируя горизонт планирования в зависимости от их нарушения.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал![В рамках исследования стохастических горизонтов принятия решений (SDH) демонстрируется, как модуляция планируемого горизонта посредством вероятностей продолжения α приводит к переменному дисконтированию [latex]\tilde{\gamma}=\gamma\alpha[/latex] и взвешенной по выживанию отдаче [latex]\tilde{r}=\alpha r[/latex], что находит применение в задачах управления человекоподобной локомоцией Hyfydy, где оптимизация ходьбы с минимальными усилиями ограничена целевой скоростью, а также в средах Safety Gymnasium, сочетающих награды за достижение целей со стандартизированными затратами, связанными с опасностями.](https://arxiv.org/html/2602.04599v1/x1.png)
Представлен фреймворк стохастических горизонтов принятия решений (SDH) для обучения с подкреплением с ограничениями, использующий взвешенную по выживанию отдачу.
Ограничения в обучении с подкреплением часто усложняются необходимостью соблюдения дополнительных условий, таких как безопасность или целевые показатели. В работе ‘Stochastic Decision Horizons for Constrained Reinforcement Learning’ предложен новый подход, основанный на концепции стохастических горизонтов принятия решений, позволяющий динамически адаптировать процесс планирования в зависимости от степени нарушения ограничений. Предложенная методика формирует взвешенные по выживанию целевые функции, совместимые с внеполисными алгоритмами обучения с подкреплением, что обеспечивает более эффективное использование данных и стабильность обучения. Сможет ли этот подход открыть новые возможности для решения сложных задач обучения с подкреплением в реальных условиях с жесткими ограничениями?
За пределами фиксированного планирования: Ограничения традиционного подхода
Традиционное обучение с подкреплением часто основывается на планировании с фиксированным горизонтом, что представляет собой существенное ограничение при решении сложных задач, требующих долгосрочного планирования. Этот подход предполагает, что агент заранее знает длительность задачи и может оптимизировать свои действия на протяжении всего этого периода. Однако, в реальных сценариях, особенно в динамичных и непредсказуемых средах, такой подход оказывается неэффективным. Ограниченный горизонт планирования мешает агенту учитывать долгосрочные последствия своих действий, приводя к субоптимальным решениям. В результате, агент может сосредоточиться на немедленном вознаграждении, игнорируя возможности для достижения более значительных результатов в будущем. Эта проблема особенно актуальна в задачах, требующих последовательности действий на протяжении длительного времени, таких как робототехника, автономное вождение и управление сложными системами.
Традиционные алгоритмы обучения с подкреплением испытывают значительные трудности в средах, характеризующихся неопределенностью будущего или появлением неожиданных ограничений. Представьте себе робота, обучающегося ориентироваться в динамичном городском пространстве: внезапное появление пешехода, изменение дорожной обстановки или даже кратковременное отключение сигнала GPS могут кардинально изменить оптимальную траекторию. В таких ситуациях, когда заранее невозможно предсказать все возможные сценарии, фиксированный горизонт планирования становится серьезным препятствием, поскольку алгоритм не способен эффективно адаптироваться к новым обстоятельствам и часто принимает неоптимальные решения. Неспособность учитывать непредсказуемость и внезапные изменения приводит к снижению эффективности и надежности системы управления, подчеркивая необходимость разработки более гибких и адаптивных стратегий контроля.
В современных системах управления, особенно в сложных и динамичных средах, существует острая необходимость в стратегиях, способных адаптироваться к меняющимся условиям и неопределенности. Традиционные подходы часто полагаются на заранее заданные планы, которые оказываются неэффективными при появлении непредвиденных обстоятельств или когда горизонт планирования ограничен. Исследования показывают, что системы, способные к динамической корректировке своих действий на основе поступающей информации и прогнозированию будущих изменений, демонстрируют значительно более высокую устойчивость и эффективность. Разработка таких адаптивных стратегий требует интеграции методов машинного обучения, теории управления и анализа рисков, что позволит создавать интеллектуальные системы, способные успешно функционировать в условиях высокой неопределенности и сложности.
![Метод управления как вывод (Control as Inference, CaI) представляет оптимальное управление как вариационный вывод в вероятностной графической модели (PGM), где Бернулли-переменная [latex]C_{t}[/latex] определяет продолжение процесса в зависимости от состояний и действий.](https://arxiv.org/html/2602.04599v1/x2.png)
Стохастические горизонты: Адаптация к непредсказуемому
Стохастические горизонты планирования представляют собой новый подход к планированию, основанный на динамическом изменении длины горизонта планирования в зависимости от уровня неопределенности окружающей среды и выполнимости ограничений. В отличие от традиционных методов, использующих фиксированный горизонт, данный подход позволяет адаптировать горизонт к текущей ситуации, увеличивая его в стабильных и предсказуемых областях и сокращая там, где существуют значительные неопределенности или ограничения, препятствующие достижению целей. Это позволяет более эффективно использовать вычислительные ресурсы и избегать планирования в заведомо невыполнимых областях, фокусируясь на краткосрочных, достижимых задачах и повышая общую эффективность системы планирования.
В рамках стохастических горизонтов принятия решений, длина планируемого горизонта динамически сокращается в областях, где возникают нарушения ограничений или наблюдается высокая степень неопределенности будущего состояния среды. Это происходит за счет оценки вероятности нарушения ограничений или увеличения дисперсии прогнозируемых результатов. Сокращение горизонта позволяет избежать планирования действий, которые с высокой вероятностью окажутся невыполнимыми, и сосредоточиться на ближайших, достижимых целях, что повышает надежность и эффективность системы принятия решений в условиях неопределенности. Величина сокращения горизонта определяется степенью нарушения ограничений и уровнем неопределенности, что позволяет адаптировать планирование к конкретным условиям среды.
Динамическая адаптация к окружающей среде позволяет данной методике избегать избыточного планирования в областях, где ограничения не выполняются или прогнозирование будущего затруднено. Вместо попыток построить долгосрочные планы в невозможных ситуациях, система концентрируется на достижении ближайших, выполнимых целей. Это достигается путем сокращения горизонта планирования в регионах с высокой неопределенностью или нарушением ограничений, что позволяет эффективно распределять вычислительные ресурсы и повышать надежность принимаемых решений в условиях меняющейся обстановки.
Взвешивание выживаемости: Приоритет достижимым целям
Функции взвешенной выживаемости (Survival-Weighted Returns) играют ключевую роль в эффективном использовании стохастических горизонтов принятия решений. В основе этого подхода лежит принцип экспоненциального увеличения веса немедленных вознаграждений по мере сокращения временного горизонта. Математически это может быть представлено как R_t' = R_t <i> \alpha^{T-t} , где R_t — вознаграждение в момент времени t*, T — общий горизонт планирования, а α — коэффициент дисконтирования, близкий к единице. По мере приближения к концу горизонта ( t \rightarrow T ), вклад немедленных вознаграждений возрастает, что позволяет агенту фокусироваться на достижимых целях и избегать долгосрочных, нереалистичных планов, особенно в условиях неопределенности.
Применение функции взвешенной выживаемости (Survival-Weighted Returns) стимулирует агента к выбору действий, приносящих немедленную выгоду, даже в условиях неопределенности. Это достигается путем экспоненциального уменьшения веса будущих наград по мере сокращения временного горизонта принятия решений. В результате, агент склонен отдавать предпочтение краткосрочным целям, которые с большей вероятностью будут достигнуты, а не долгосрочным планам, вероятность реализации которых снижается из-за непредсказуемости окружения. Такой подход позволяет агенту оптимизировать свою стратегию в условиях ограниченной информации и высокой степени риска.
Комбинирование взвешенной по выживанию доходности (Survival-Weighted Return) с использованием стохастических горизонтов принятия решений (Stochastic Decision Horizons) обеспечивает приоритезацию достижимых целей и предотвращает застревание агента в долгосрочных, нереализуемых планах. Такой подход динамически корректирует вес будущих вознаграждений, снижая его по мере приближения к концу горизонта планирования. Это заставляет агента концентрироваться на действиях, приносящих немедленную выгоду, и избегать стратегий, требующих длительного выполнения и подверженных высоким рискам неудачи в условиях неопределенности. Фактически, агент оптимизирует свои действия, исходя из вероятности успешного достижения целей в рамках ограниченного временного интервала, что повышает общую эффективность и устойчивость системы.
Применение и валидация: Надежный контроль в сложных системах
Исследования демонстрируют, что разработанная структура Стохастического Горизонта Принятия Решений, в сочетании с алгоритмами, такими как Soft Actor-Critic и Maximum-a-Posteriori Policy Optimization, позволяет достичь значительных улучшений в эффективности обучения и балансе между получением вознаграждения и соблюдением ограничений. Данный подход успешно протестирован как в симулированных средах непрерывного управления (Safety Gymnasium), так и в высокоточных мускулоскелетных симуляциях движения (Hyfydy), причем важно отметить, что для достижения оптимальных результатов не требуется использование множителей Лагранжа. Это открывает новые возможности для создания более эффективных и надежных систем управления, способных адаптироваться к сложным и непредсказуемым условиям, оптимизируя как производительность, так и безопасность.
Для всесторонней проверки разработанного подхода к управлению в сложных системах использовались специализированные вычислительные среды, такие как Safety Gymnasium и высокоточные симуляции мускулоскелетной локомоции Hyfydy. Safety Gymnasium предоставляет широкий спектр контролируемых сценариев, позволяющих оценить алгоритмы в условиях, требующих соблюдения ограничений и предотвращения нарушений. В свою очередь, Hyfydy, благодаря своей реалистичной моделированию биомеханики, позволяет изучать управление сложными движениями, имитирующими ходьбу и бег, что особенно важно для разработки протезов и экзоскелетов. Сочетание этих сред обеспечивает как строгую проверку безопасности, так и оценку эффективности алгоритмов в задачах, приближенных к реальным физическим системам, что делает их идеальными площадками для валидации и отладки новых методов управления.
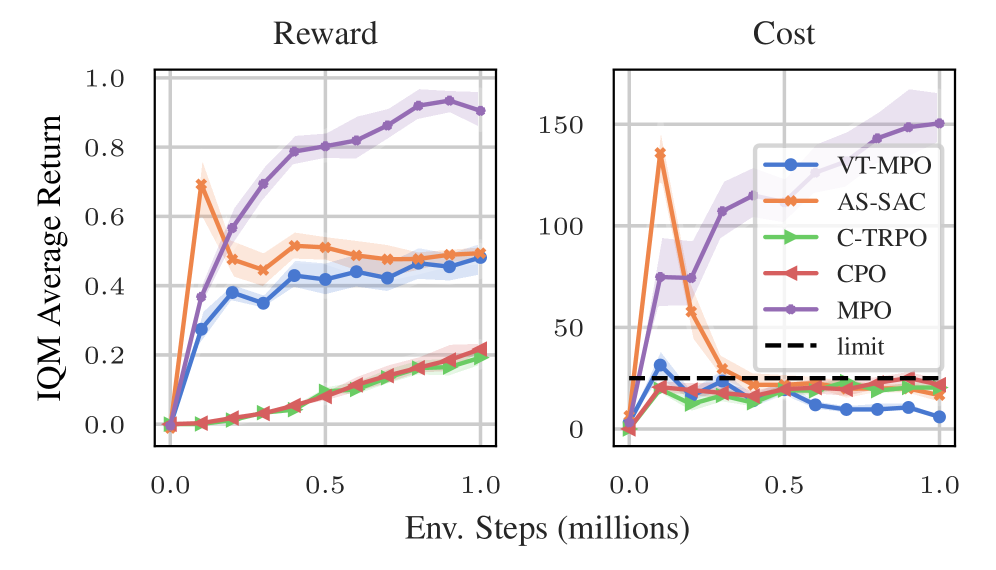
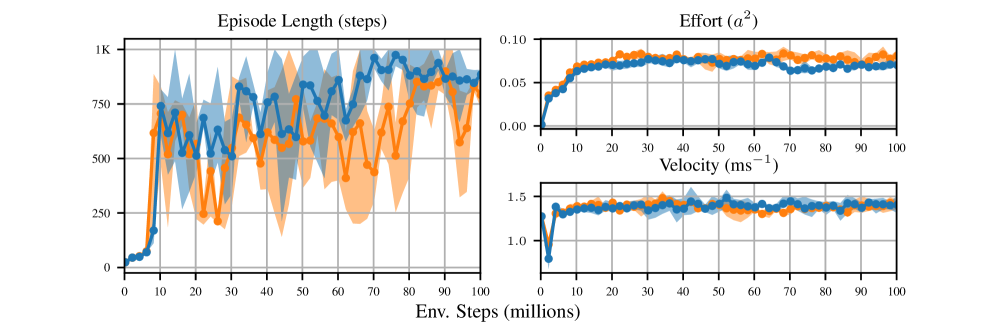
Результаты внедрения продемонстрировали значительное повышение эффективности в различных сложных системах. В рамках бенчмарка Safety Gymnasium разработанный подход превзошел алгоритмы CPO и C-TRPO, обеспечив более высокую суммарную награду и ускоренное обучение на начальных этапах. Кроме того, при моделировании мускулоскелетной локомоции в среде Hyfydy, были достигнуты более экономичные паттерны движения, характеризующиеся сниженными затратами энергии. В частности, разработанный метод последовательно демонстрировал превосходство над алгоритмом EWA в балансе между усилиями и скоростью, стабильно поддерживая целевую скорость в 1.1 м/с. Данные результаты подтверждают перспективность предложенного подхода для управления сложными системами, требующими оптимизации как эффективности, так и безопасности.
К адаптивным и устойчивым агентам: Перспективы развития
Исследования показывают, что объединение методов исследования пространства состояний, таких как DEP Exploration, со стохастическими горизонтами принятия решений значительно повышает способность агента находить эффективные стратегии в сложных средах. DEP Exploration, фокусируясь на обнаружении редких, но потенциально полезных состояний, позволяет агенту избегать застревания в локальных оптимумах. Сочетание этого подхода со стохастическими горизонтами, которые учитывают неопределенность будущего, позволяет агенту адаптироваться к изменяющимся условиям и планировать действия на различной глубине, что критически важно в задачах, где долгосрочное планирование затруднено. Такая интеграция обеспечивает более гибкое и эффективное исследование пространства действий, позволяя агенту быстро находить оптимальные решения даже в условиях высокой сложности и неопределенности.
Усовершенствование методов адаптации веса усилий играет ключевую роль в повышении точности движений агентов в мускулоскелетных симуляциях. Данные методы позволяют динамически регулировать величину активации мышц, что необходимо для выполнения сложных и скоординированных действий. Более точная адаптация веса усилий позволяет агенту компенсировать возмущения, такие как внешние силы или изменения в структуре тела, сохраняя стабильность и точность движений. Исследования в этой области направлены на разработку алгоритмов, которые могут предсказывать оптимальные значения веса усилий на основе текущего состояния агента и его целей, что приводит к более реалистичным и эффективным движениям в виртуальной среде. Подобные разработки особенно важны для создания протезов и экзоскелетов, а также для улучшения реалистичности симуляций человеческого движения.
Разработка интеллектуальных агентов, способных к адаптации и устойчивости в динамично меняющихся условиях, требует комплексного подхода, объединяющего адаптивные горизонты планирования с передовыми методами исследования и управления. Использование адаптивных горизонтов позволяет агенту динамически корректировать дальность прогнозирования, сосредотачиваясь на ближайших задачах в условиях неопределенности и расширяя горизонт при появлении стабильных условий. Сочетание этого с продвинутыми алгоритмами исследования, такими как DEP Exploration, позволяет агенту эффективно находить оптимальные стратегии даже в сложных средах, а усовершенствованные методы управления обеспечивают точное и эффективное выполнение действий. В результате, создаются агенты, не только способные выдерживать неожиданные препятствия, но и обладающие потенциалом к самообучению и адаптации к новым, ранее не встречавшимся задачам, что открывает широкие перспективы для их применения в робототехнике, автоматизированных системах и других областях.
Предложенный труд демонстрирует элегантный подход к решению задач обучения с подкреплением, где ограничения играют ключевую роль. Авторы, подобно скульпторам, отсекают избыточное, формируя горизонт планирования на основе нарушений ограничений. Такой метод, как Stochastic Decision Horizons, позволяет добиться стабильности и эффективности обучения даже при работе с данными, полученными не в текущей политике. Грейс Хоппер однажды заметила: «Лучший способ предсказать будущее — создать его». Именно этим и занимаются исследователи, создавая инструменты для более надежного и предсказуемого обучения агентов, способных оперировать в сложных и ограниченных средах.
Куда Далее?
Представленный подход, оперируя горизонтом принятия решений, зависимым от нарушения ограничений, не решает проблему избыточности, присущую большинству систем обучения с подкреплением. Скорее, он изящно переносит ее в плоскость определения этого самого горизонта. Необходимо признать, что стабильность обучения, достигнутая посредством взвешенных по выживанию возвратов, не является самоцелью, а лишь инструментом для приближения к более простому, понятому решению. Дальнейшие исследования должны быть направлены не на усложнение механизмов адаптации горизонта, а на поиск минимального набора условий, достаточных для его эффективной работы.
Очевидным направлением является изучение взаимодействия между стохастическим горизонтом принятия решений и структурой пространства состояний. Возможно, в определенных задачах, упрощение самого пространства, а не адаптация горизонта, окажется более эффективным решением. Необходимо также рассмотреть возможность применения предложенного подхода в контексте обучения с подкреплением, ориентированного на агента, где горизонт принятия решений может быть не просто параметром, а отражением внутренней модели агента о мире.
В конечном счете, ценность любой системы обучения с подкреплением определяется не ее способностью к адаптации к сложным условиям, а ее способностью к предсказанию и упрощению. Задача состоит не в том, чтобы создать систему, способную решать любые задачи, а в том, чтобы создать систему, способную признать, когда задача слишком сложна, и предложить более простое решение.
Оригинал статьи: https://arxiv.org/pdf/2602.04599.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Недвижимость и авиа: что ждет потребителей в России? Анализ рынка и новые маршруты (28.03.2026 19:32)
- АЛРОСА акции прогноз. Цена ALRS
- Супернус: Продажа Акций и Нервные Тики
- Будущее FET: прогноз цен на криптовалюту FET
- Будущее KAS: прогноз цен на криптовалюту KAS
- Южнокорейский Крипто-Консолидация: Захват Доли и Риски для Инвесторов (03.04.2026 06:15)
- СириусXM: Пыль дорог и звон монет
- Управление рисками в условиях неопределенности: современные подходы
- ПИК акции прогноз. Цена PIKK
2026-02-05 13:03