Автор: Денис Аветисян
Исследователи предлагают эффективный метод для повышения стабильности и результативности обучения больших языковых моделей, взаимодействующих с пользователем в многошаговых сценариях.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал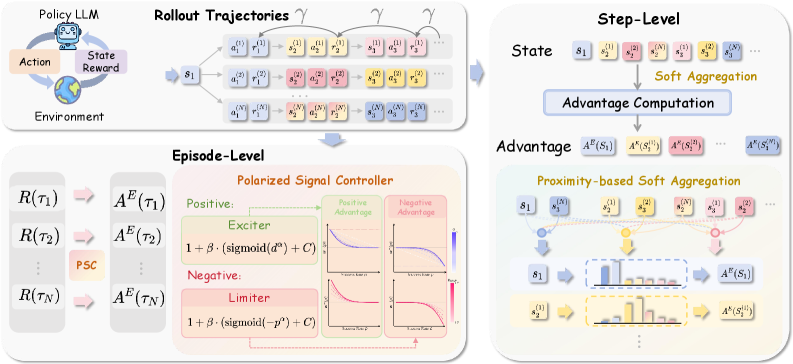
Предложенная схема ProxMO улучшает распределение вознаграждений в обучении с подкреплением, учитывая глобальный контекст на каждом этапе взаимодействия.
В задачах обучения агентов на основе больших языковых моделей, эффективное разделение полезных сигналов от случайного шума является критически сложным. В данной работе, ‘Proximity-Based Multi-Turn Optimization: Practical Credit Assignment for LLM Agent Training’, предложен фреймворк ProxMO, обеспечивающий более точную оценку вклада отдельных действий в долгосрочный успех, за счет учета глобального контекста на уровне эпизода и шага. ProxMO динамически адаптирует интенсивность градиента и использует взвешенное усреднение на основе семантической близости, демонстрируя значительное улучшение производительности на задачах ALFWorld и WebShop. Не откроет ли это путь к созданию более надежных и эффективных агентов, способных к сложным интерактивным задачам в реальных условиях?
Преодоление Проблемы Отложенного Вознаграждения
Традиционное обучение с подкреплением сталкивается с серьезными трудностями при работе с отложенным вознаграждением в сложных, многошаговых задачах. Суть проблемы заключается в том, что алгоритму сложно установить связь между совершенными действиями и полученным результатом, когда промежуток между ними значителен. Это особенно актуально для задач, требующих планирования и долгосрочной стратегии, где немедленная отдача отсутствует. В результате, алгоритм может неверно оценить вклад каждого действия в конечный успех, что приводит к замедлению обучения или даже к его полной остановке. Алгоритмы, основанные на немедленном вознаграждении, оказываются неэффективными в ситуациях, где успех зависит от последовательности действий, а не от мгновенной реакции на стимул, что значительно ограничивает их применимость в реальных, сложных сценариях.
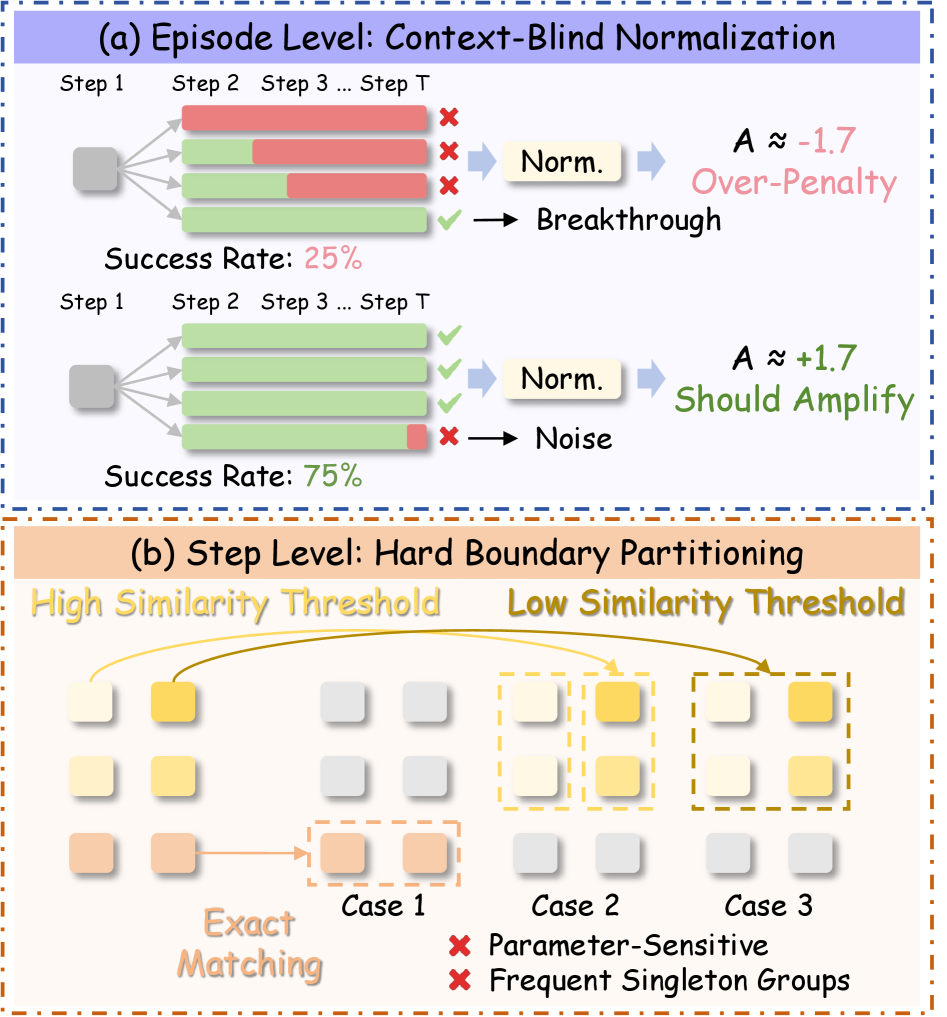
Применяемые в обучении с подкреплением методы упрощения задачи отнесения заслуг, такие как жесткое разделение на сегменты и нормализация по Z-оценке, зачастую вносят неточности и асимметрии в процесс. Исследования показывают, что эти подходы приводят к формированию изолированных групп, представляющих до 30-36% всех шагов траектории. Это означает, что значительная часть действий остается вне контекста, что затрудняет правильную оценку их вклада в конечный результат и, как следствие, снижает эффективность обучения, особенно в задачах, требующих долгосрочного планирования и рассуждений.
Ограничения существующих методов обучения с подкреплением становятся особенно заметными при анализе последовательных взаимодействий, требующих долгосрочного планирования. В ситуациях, когда полезный сигнал приходит лишь спустя значительное количество шагов, алгоритмам сложно корректно оценить вклад каждого действия в конечный результат. Эта проблема усугубляется в задачах, где необходимо учитывать сложные взаимосвязи между событиями, происходящими на разных этапах взаимодействия. Неспособность адекватно распределить «кредит» между различными действиями приводит к замедлению обучения и снижению эффективности алгоритмов, особенно в сценариях, требующих прогнозирования и адаптации к изменяющимся условиям на протяжении длительных временных интервалов.
Оптимизация на Основе Близости Состояний: Новый Подход
Оптимизация на основе близости состояний (ProxMO) представляет собой новый подход к распределению заслуг в задачах обучения с подкреплением. Вместо использования дискретных границ для определения вклада отдельных шагов, ProxMO оценивает семантическую близость между состояниями, что позволяет более точно определить, какие действия оказали наибольшее влияние на достижение цели. Данный подход использует метрики семантического сходства для непрерывной оценки вклада каждого состояния, обеспечивая более детальное и гибкое распределение заслуг по сравнению с традиционными методами, основанными на жестких критериях.
В рамках ProxMO, традиционные дискретные границы между состояниями в процессе обучения заменяются на систему непрерывного взвешивания, основанную на семантической близости между ними. Вместо четкого разделения, каждому состоянию присваивается вес, пропорциональный его сходству с целевым состоянием или состоянием, за которое необходимо выдать награду. Это позволяет более точно распределять заслуги (кредит) между различными шагами, учитывая вклад каждого состояния в достижение конечного результата. В отличие от систем, использующих жесткие границы, непрерывное взвешивание позволяет учитывать частичный вклад состояний, находящихся вблизи целевых, что повышает точность и эффективность обучения.
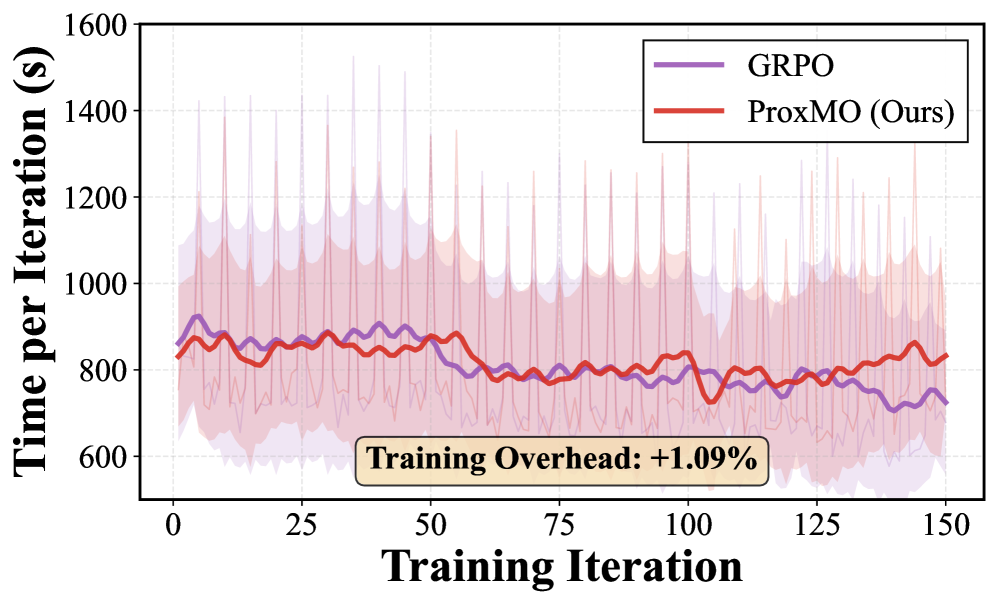
Предлагаемый фреймворк Proximity-Based Multi-Turn Optimization (ProxMO) базируется на принципах обучения с подкреплением, что обеспечивает масштабируемость и адаптивность решения для задач повышенной сложности. В ходе тестирования было установлено, что использование ProxMO не приводит к существенному увеличению времени обучения — накладные расходы составляют всего 1.09% по сравнению с алгоритмом GRPO, что делает его эффективным инструментом для широкого спектра приложений, требующих оптимизации в динамических средах.
Уточнение Распределения Заслуг с Помощью Мягкой Агрегации и Модуляции
В ProxMO для оценки семантической близости состояний используется метод TF-IDF (Term Frequency-Inverse Document Frequency). Этот метод позволяет количественно определить релевантность состояний, основываясь на частоте встречаемости слов в каждом состоянии и их редкости во всем наборе данных. В результате, при агрегации сигналов, состояния, семантически близкие к текущему, получают больший вес, что обеспечивает более точную оценку вклада каждого состояния в итоговый результат. Вес каждого состояния пропорционален его релевантности, вычисленной посредством TF-IDF, что позволяет эффективно фокусироваться на наиболее значимых данных.
Динамическое регулирование распределения вознаграждения (Success-Rate-Aware Modulation) в ProxMO осуществляет адаптацию к сложности задачи, оценивая вероятность успешного выполнения. В сложных сценариях, где вероятность успеха низкая, система усиливает сигналы, связанные с промежуточными шагами, что облегчает обучение агента. В простых задачах, где вероятность успеха высока, происходит ослабление сигналов, уменьшая влияние случайного шума и повышая стабильность обучения. Данный механизм позволяет более эффективно использовать информацию о вознаграждении, оптимизируя процесс обучения в различных условиях и повышая общую производительность агента.
Взаимодействие механизмов мягкой агрегации на основе близости и модуляции, учитывающей успешность выполнения, формирует устойчивую и адаптируемую систему распределения вознаграждений. Эта система критически важна для успешного обучения в задачах с горизонтом планирования, требующих последовательных действий. Экспериментальные результаты, полученные на платформах ALFWorld и WebShop, демонстрируют статистически значимое повышение процента успешного выполнения задач при использовании данной системы по сравнению с традиционными подходами к распределению вознаграждений.
Оценка ProxMO в Многошаговых Интерактивных Средах
Исследования показывают, что ProxMO демонстрирует впечатляющую эффективность при использовании с большими языковыми моделями (LLM) в задачах, требующих многошагового взаимодействия. В сложных сценариях, где агенту необходимо последовательно выполнять действия и учитывать предыдущие результаты, ProxMO позволяет LLM демонстрировать производительность, сопоставимую или превосходящую закрытые коммерческие решения. Это особенно важно для реалистичных задач, где требуется не просто выполнение одной команды, а длительное взаимодействие с окружением и адаптация к изменяющимся условиям, что делает ProxMO ценным инструментом для создания более интеллектуальных и автономных агентов.
Исследования, проведенные в интерактивных средах, таких как ALFWorld и WebShop, демонстрируют выдающиеся возможности ProxMO в решении сложных задач, требующих развернутого логического мышления. В этих реалистичных сценариях, имитирующих взаимодействие с окружающим миром и онлайн-магазинами, ProxMO не только успешно справляется с поставленными задачами, но и достигает результатов, сопоставимых или превосходящих показатели ведущих закрытых больших языковых моделей. Такое превосходство подчеркивает потенциал ProxMO для создания более интеллектуальных и эффективных агентов, способных к продолжительному и сложному взаимодействию с окружающей средой.
Метод ProxMO открывает новые возможности для обучения языковых моделей в сложных интерактивных средах благодаря более точному распределению «наград» за действия. Традиционно, оценка эффективности агента в многошаговом взаимодействии затруднена из-за неясности, какие конкретно действия привели к успеху или неудаче. ProxMO решает эту проблему, позволяя более четко определить вклад каждого шага в конечный результат. Это, в свою очередь, значительно улучшает процесс обучения, позволяя агентам быстрее осваивать сложные задачи и демонстрировать превосходные результаты в реалистичных сценариях, таких как выполнение бытовых поручений или совершение покупок в интернете. Повышенная точность в определении причинно-следственных связей между действиями и результатами является ключевым фактором для создания действительно интеллектуальных и адаптивных агентов.
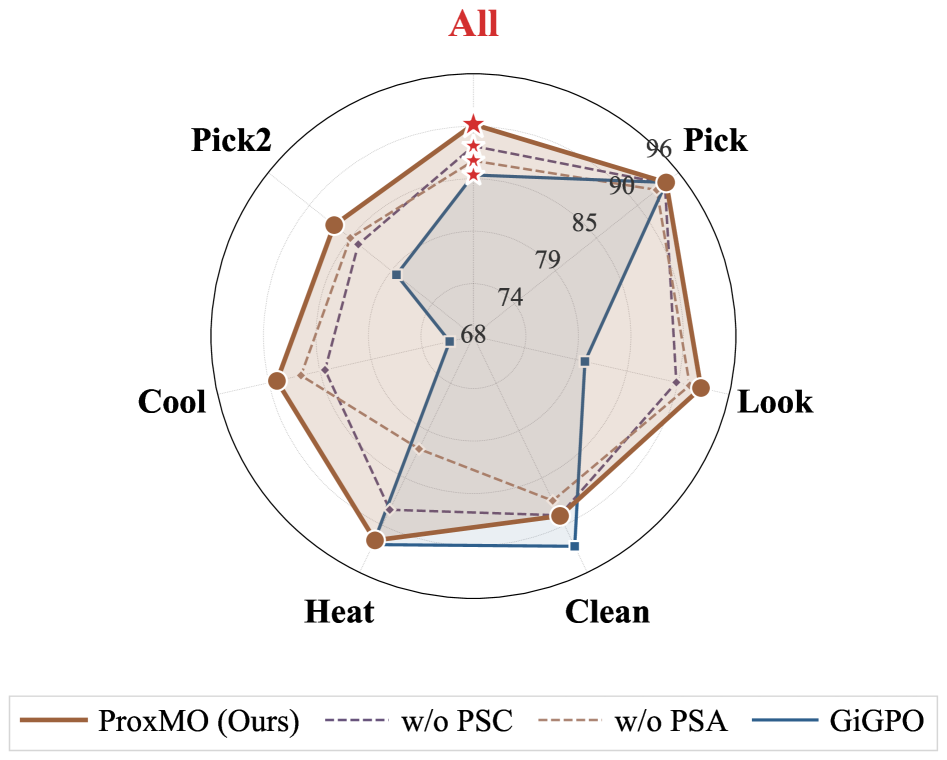
Исследование представляет подход, в котором целостность системы играет ключевую роль в обучении агентов на основе больших языковых моделей. Авторы подчеркивают важность учета глобального контекста на каждом этапе взаимодействия, чтобы избежать локальных оптимизаций, которые могут нарушить общую структуру поведения. Это созвучно словам Джона Маккарти: «Искусственный интеллект — это изучение того, как сделать так, чтобы машины вели себя разумно». Подобно тому, как нельзя успешно пересадить сердце, не понимая кровотока всей системы, так и ProxMO стремится к улучшению назначения вознаграждений, рассматривая взаимодействие как единый, взаимосвязанный процесс. Оптимизация на основе близости, предложенная в работе, позволяет агенту лучше понимать последствия своих действий в контексте всей эпизода, что ведет к более стабильному и эффективному обучению.
Куда двигаться дальше?
Представленный подход, безусловно, демонстрирует улучшение в задаче кредитного распределения, но необходимо признать, что это лишь частичное решение. Мы оптимизируем не то, что нужно, а то, что возможно в рамках существующей архитектуры обучения с подкреплением. Глобальный контекст, включенный в ProxMO, является полезным, но не устраняет фундаментальной проблемы: сложность многошаговых взаимодействий неизбежно приводит к экспоненциальному росту неопределенности. Простота масштабируется, изощрённость — нет, и эта истина особенно актуальна здесь.
Будущие исследования должны сосредоточиться на разработке принципиально новых методов, которые позволят агентам не просто лучше распределять кредит, а более эффективно планировать и предвидеть последствия своих действий. Интересным направлением представляется интеграция ProxMO с моделями, способными к абстрактному рассуждению и построению причинно-следственных связей. Зависимости — настоящая цена свободы, и необходимо тщательно оценивать компромисс между выразительностью модели и сложностью обучения.
Хорошая архитектура незаметна, пока не ломается. Представленная работа — это шаг вперед, но истинный прогресс потребует отхода от упрощенных моделей и признания того, что обучение агентов — это не просто оптимизация функции, а создание сложной, самоорганизующейся системы. Необходимо помнить, что каждая абстракция уязвима, и поиск оптимального баланса между обобщением и детализацией — ключевая задача на будущее.
Оригинал статьи: https://arxiv.org/pdf/2602.19225.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- ЕвроТранс акции прогноз. Цена EUTR
- Серебро прогноз
- Российский рынок: Нефть, дивиденды и геополитика. Что ждет инвесторов? (23.03.2026 18:32)
- РУСАЛ акции прогноз. Цена RUAL
- ДЭК акции прогноз. Цена DVEC
- Крипто-волатильность, лицензии MiCA и риски безопасности: Дайджест главных новостей недели
- Хэдхантер акции прогноз. Цена HEAD
- Прогноз нефти
- Как два ETF играют в одни ворота, но с разными мячами
2026-02-24 23:24