Автор: Денис Аветисян
Новый подход к обучению с подкреплением позволяет повысить эффективность и устойчивость больших языковых моделей при решении сложных задач.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал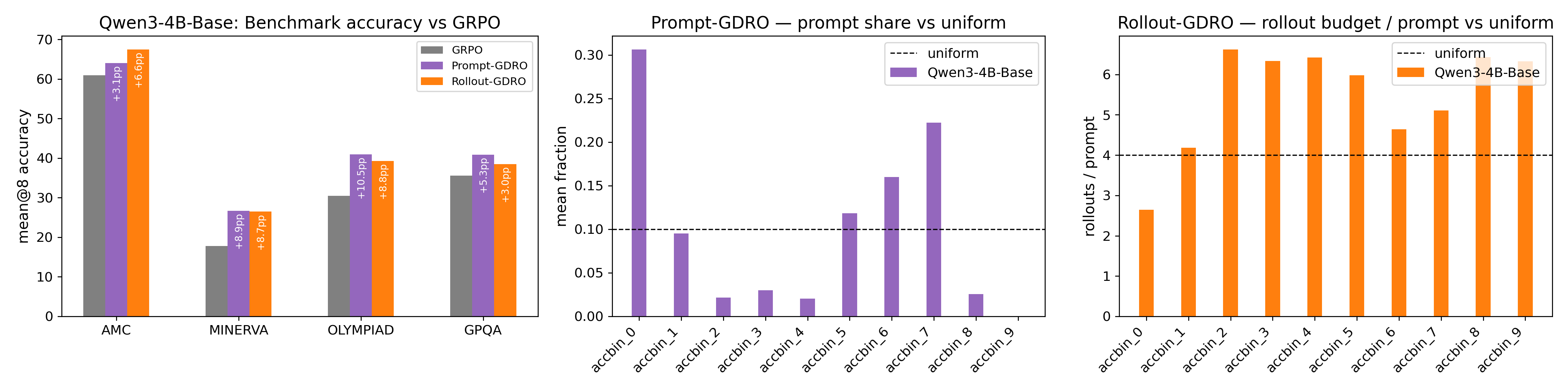
В статье представлены механизмы Rollout-GDRO и Prompt-GDRO для динамического распределения вычислительных ресурсов и перевзвешивания данных на основе сложности задач.
Стандартные алгоритмы обучения с подкреплением часто сталкиваются с неэффективностью при работе с неоднородными данными, особенно в задачах, требующих сложного рассуждения. В данной работе, посвященной ‘Group Distributionally Robust Optimization-Driven Reinforcement Learning for LLM Reasoning’, предложен новый подход, использующий методы робастной оптимизации для адаптивного распределения вычислительных ресурсов и взвешивания данных в процессе обучения больших языковых моделей. Разработанные механизмы Prompt-GDRO и Rollout-GDRO динамически перераспределяют усилия на сложные примеры, обеспечивая прирост точности до 10% по сравнению с традиционными методами. Сможет ли подобный адаптивный подход открыть новые горизонты в обучении моделей, способных к более надежному и эффективному рассуждению?
Вызов Эффективного Рассуждения в Больших Моделях
Несмотря на значительные успехи в разработке трансформаторных моделей, углубление процесса рассуждений остается вычислительно затратной и неэффективной задачей. По мере увеличения сложности задач и требуемой глубины анализа, потребность в вычислительных ресурсах растет экспоненциально, что ограничивает возможности применения этих моделей к крупномасштабным и ресурсоемким задачам. Традиционные подходы к увеличению масштаба моделей часто приводят к закономерному снижению отдачи от вложенных ресурсов, поскольку сложность вычислений перерастает возможности эффективной параллелизации и оптимизации. Данная проблема требует поиска новых архитектур и алгоритмов, способных обеспечить более эффективное использование вычислительных ресурсов при сохранении или даже улучшении качества рассуждений.
Традиционные методы обработки информации в крупных языковых моделях часто сталкиваются с проблемой неэффективного распределения вычислительных ресурсов при решении сложных задач. Вместо того чтобы фокусироваться на наиболее важных этапах логического вывода, системы, как правило, равномерно распределяют усилия по всем операциям, что приводит к экспоненциальному росту затрат с увеличением глубины рассуждений. В результате, прирост производительности при масштабировании модели начинает снижаться, демонстрируя эффект уменьшающейся отдачи. Такой подход особенно критичен в задачах, требующих многоступенчатого логического анализа, где неоптимальное распределение ресурсов может привести к значительному увеличению времени обработки и снижению точности получаемых результатов. Поэтому, разработка более интеллектуальных стратегий управления ресурсами является ключевой задачей для повышения эффективности и масштабируемости современных языковых моделей.
Динамическое Распределение Ресурсов с Игровой Динамикой
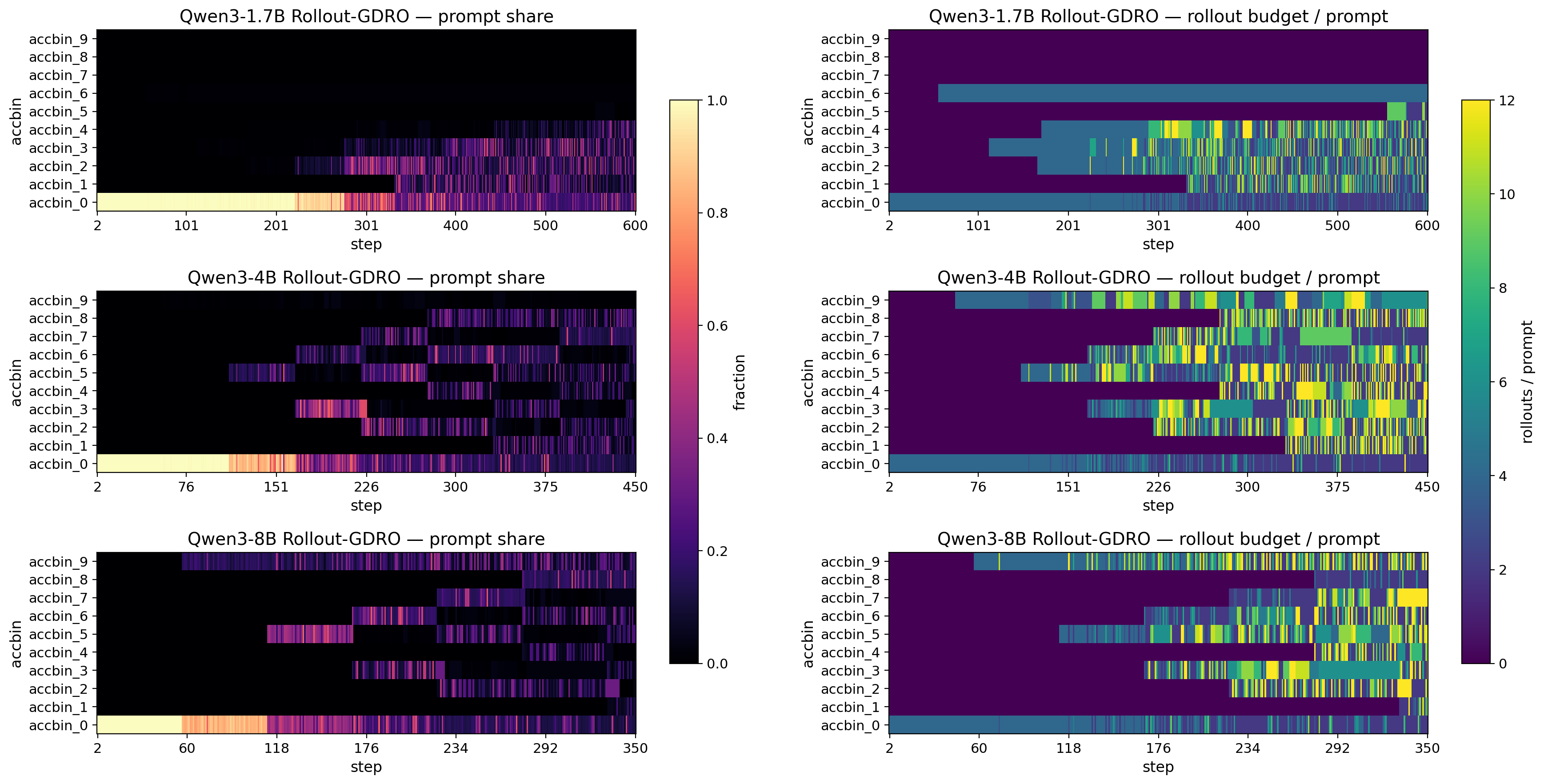
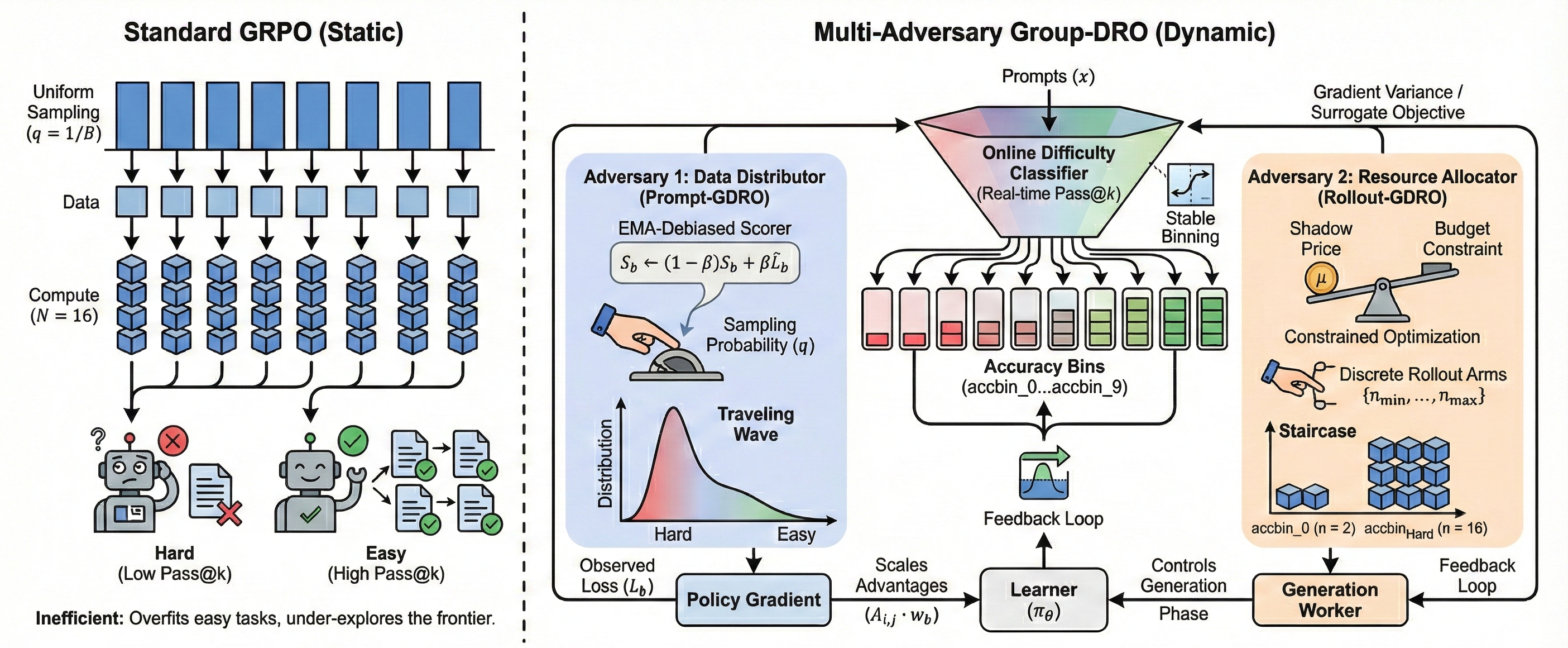
В рамках предложенного подхода, основанного на GRPO, реализованы механизмы динамического распределения вычислительных ресурсов — Rollout-GDRO и Prompt-GDRO. Rollout-GDRO использует итеративный процесс развертывания для оценки потенциала различных стратегий распределения ресурсов, а Prompt-GDRO применяет подсказки для направления процесса поиска оптимального решения. Оба механизма позволяют адаптировать объем выделяемых ресурсов в зависимости от характеристик решаемой задачи, что обеспечивает более эффективное использование вычислительных мощностей и повышение производительности системы.
Методы Rollout-GDRO и Prompt-GDRO используют принципы динамики игр с отсутствием сожаления (No-Regret Game Dynamics) для эффективного исследования и использования пространства рассуждений. В основе лежит концепция, согласно которой агенты (в данном случае, алгоритмы распределения ресурсов) стремятся минимизировать разницу между полученной выгодой и выгодой, которую можно было бы получить, выбрав всегда наилучшую стратегию задним числом. Это достигается путем итеративного обновления стратегий на основе наблюдаемых результатов, что позволяет алгоритмам адаптироваться к сложности задач и находить оптимальное распределение ресурсов для максимизации производительности. Использование No-Regret Learning гарантирует, что средняя выгода агента стремится к оптимальной при неограниченном количестве итераций, обеспечивая сходимость к эффективному решению.
Адаптивное распределение вычислительных ресурсов, основанное на сложности решаемой задачи, позволяет оптимизировать производительность при минимальных затратах. Данный подход предполагает динамическое изменение объема выделяемых ресурсов — процессорного времени, памяти, пропускной способности — в зависимости от оценки сложности текущей задачи. Более сложные задачи получают больше ресурсов для обеспечения необходимой скорости и точности решения, в то время как для простых задач выделяется минимально необходимое количество ресурсов, что позволяет избежать их неэффективного использования и снизить общую вычислительную стоимость. Такая стратегия направлена на достижение оптимального баланса между скоростью выполнения, точностью решения и потреблением ресурсов, обеспечивая максимальную эффективность системы в целом.
Детали Реализации: Гиперпараметры и Адверсарное Обучение
Оба метода, Rollout-GDRO и Prompt-GDRO, используют многоадверсарную структуру (Multi-Adversary Framework) для распределения ресурсов. В основе лежит алгоритм EMA-Debiased GDRO-EXP3P, который обеспечивает взвешенное распределение ресурсов между различными противниками (adversaries) на основе их эффективности. Алгоритм использует экспоненциально взвешенное среднее (Exponential Moving Average, EMA) для оценки производительности каждого противника и алгоритм EXP3P для выбора, какие противники получат больше ресурсов на следующем шаге. Этот подход позволяет динамически адаптировать распределение ресурсов, фокусируясь на наиболее перспективных стратегиях и снижая риски, связанные с неэффективными подходами.
Для оптимизации производительности алгоритмов Rollout-GDRO и Prompt-GDRO применяются критически важные гиперпараметры, подобранные в результате экспериментов. Коэффициент исследования (γ) установлен на уровне 0.01, что определяет баланс между использованием известных стратегий и исследованием новых. Экспоненциальное скользящее среднее (EMA) для оценки результатов (β) имеет значение 0.12, обеспечивая сглаживание и стабильность обучения. Скорость обучения для противника (ηq) установлена на уровне 0.65, что определяет скорость адаптации к изменениям в среде. Максимальное ограничение веса класса (Max Class Weight Cap) равно 15.0, что предотвращает чрезмерное влияние отдельных классов на процесс обучения и способствует более сбалансированной модели.
В обоих методах, Rollout-GDRO и Prompt-GDRO, применяется нормализация функции потерь (Loss Normalization) для снижения влияния частотной предвзятости (frequency bias). Данная техника предполагает масштабирование значений потерь для каждого класса или примера, что предотвращает доминирование классов с большим количеством примеров в процессе обучения. Нормализация позволяет модели более эффективно обучаться на несбалансированных наборах данных, обеспечивая более надежную и стабильную работу, а также улучшая обобщающую способность модели за счет снижения риска переобучения на доминирующих классах.
В Rollout-GDRO для оценки неопределенности и определения количества дискретных прогонов используется прокси-вариация (Variance Proxy). Этот механизм позволяет алгоритму более эффективно распределять вычислительные ресурсы, фокусируясь на областях, где требуется дополнительное исследование. Обе рассматриваемые методики, Rollout-GDRO и Prompt-GDRO, применяют Online Pass@k с 10 бинами для группировки результатов. Данный подход позволяет оценить качество полученных результатов, разделяя их на группы в зависимости от релевантности и точности, что упрощает анализ и оптимизацию процесса обучения.
Продемонстрированная Эффективность и Перспективы Развития
Исследования показали, что алгоритмы Rollout-GDRO и Prompt-GDRO демонстрируют превосходство над традиционными методами в задачах, требующих сложного рассуждения. Ключевым результатом является значительное снижение вычислительных затрат при сохранении, а зачастую и увеличении, точности решений. В отличие от подходов, требующих обширных вычислительных ресурсов, Rollout-GDRO и Prompt-GDRO позволяют достигать сопоставимых результатов при существенно меньших затратах энергии и времени, что открывает перспективы для применения продвинутых моделей рассуждения в условиях ограниченных ресурсов, например, на мобильных устройствах или в системах с низким энергопотреблением. Такое повышение эффективности является важным шагом на пути к созданию более доступных и практичных систем искусственного интеллекта.
Повышенная эффективность, достигнутая благодаря новым алгоритмам, открывает перспективные возможности для внедрения сложных моделей рассуждений на устройствах с ограниченными вычислительными ресурсами. Ранее, развертывание таких моделей требовало значительных затрат энергии и мощностей, что ограничивало их применение в мобильных устройствах, встроенных системах и других сценариях, где ресурсы ограничены. Теперь, благодаря снижению вычислительных издержек, становится возможным использование продвинутых методов рассуждения, таких как логический вывод и решение проблем, непосредственно на этих устройствах, расширяя область применения искусственного интеллекта и обеспечивая более быстрое и эффективное принятие решений в различных областях, от автономной робототехники до персональных ассистентов.
Дальнейшие исследования направлены на расширение применимости разработанных методов к задачам, требующим более сложного логического вывода и анализа. Особое внимание будет уделено адаптивной настройке гиперпараметров, что позволит автоматически оптимизировать производительность моделей в различных условиях и для разных типов задач. Это подразумевает разработку алгоритмов, способных динамически подстраивать параметры обучения в процессе работы, избегая необходимости ручного подбора и обеспечивая максимальную эффективность использования вычислительных ресурсов. Ожидается, что подобный подход позволит значительно повысить надежность и универсальность систем искусственного интеллекта, способных к сложному рассуждению.
Постоянное совершенствование предложенного подхода направлено на раскрытие всего потенциала эффективного рассуждения в больших языковых моделях. Исследования показывают, что дальнейшая оптимизация алгоритмов и адаптация к более сложным задачам позволит значительно повысить производительность и снизить вычислительные затраты. Особое внимание уделяется разработке стратегий адаптивной настройки гиперпараметров, что позволит моделям динамически подстраиваться под конкретные условия и требования задачи. Это, в свою очередь, открывает возможности для создания более интеллектуальных и экономичных систем искусственного интеллекта, способных решать сложные проблемы с высокой точностью и скоростью. Подобный прогресс имеет ключевое значение для расширения сферы применения больших языковых моделей в различных областях, от автоматизированного анализа данных до разработки интеллектуальных помощников.
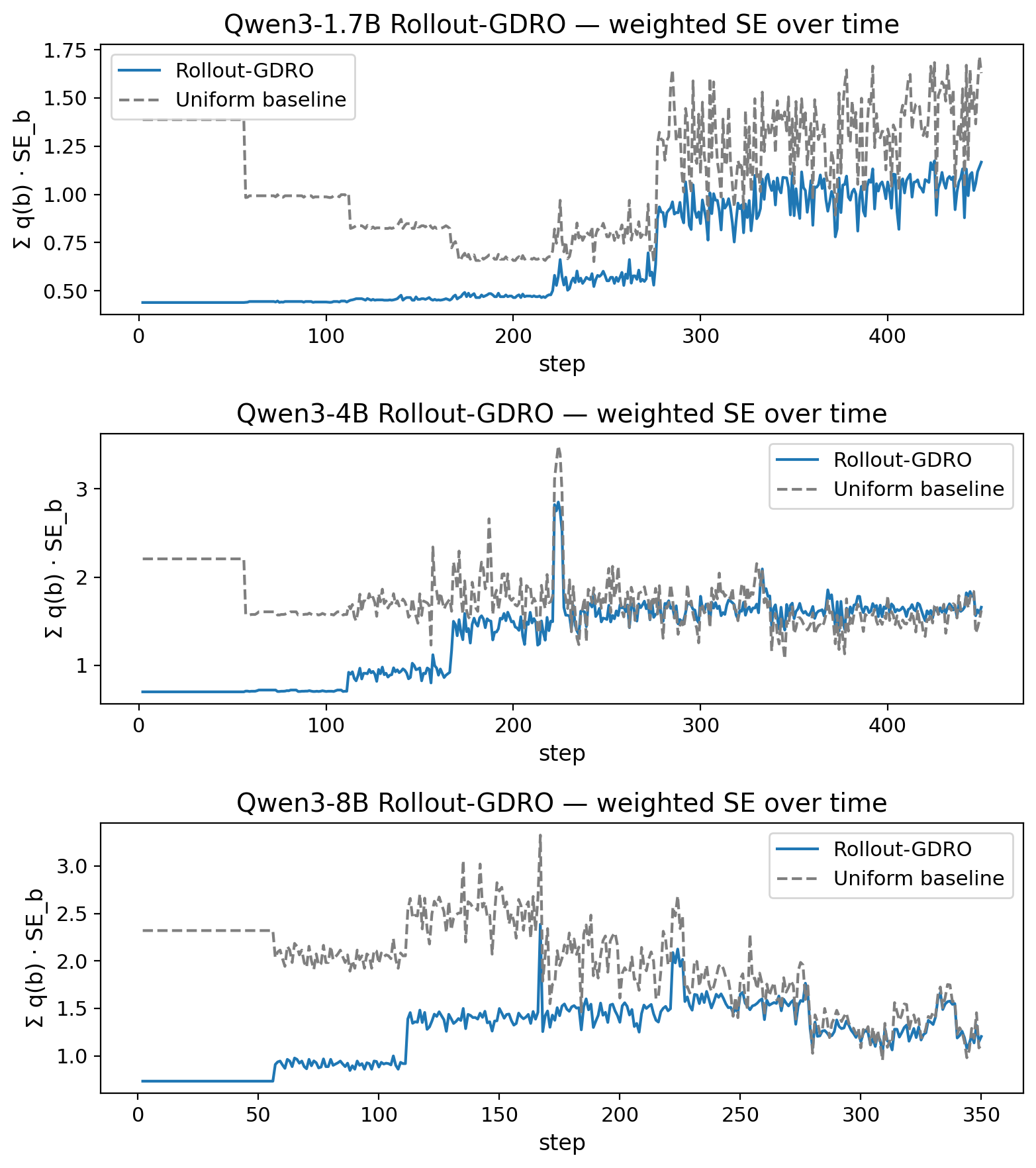
![Анализ динамики распределения ресурсов показывает, что модель 8B (зеленый график) поддерживает разнообразие стратегии даже при решении более простых задач, в отличие от модели 1.7B (синий график), тогда как механизм двойных переменных обеспечивает фиксированный бюджет, перераспределяя ресурсы в сторону сложных задач ([latex] \geq \texttt{accbin}_{\texttt{8}} [/latex]).](https://arxiv.org/html/2601.19280v1/figures/rollout_scalar_summaries.png)
Исследование, представленное в данной работе, стремится к оптимизации процессов обучения, фокусируясь на уменьшении вычислительной нагрузки и повышении устойчивости алгоритмов. Авторы предлагают механизмы Rollout-GDRO и Prompt-GDRO, динамически перераспределяющие ресурсы и корректирующие данные в зависимости от сложности решаемой задачи. Это напоминает подход Дональда Дэвиса: «Сложность — это тщеславие. Ясность — милосердие». Подобно тому, как Дэвис стремился к упрощению систем, данное исследование направлено на «сжатие» процесса обучения, устраняя избыточные вычисления и фокусируясь на наиболее важных аспектах задачи. Принцип снижения дисперсии, лежащий в основе предлагаемых методов, служит аналогией стремлению к ясности и эффективности, избегая ненужной сложности и обеспечивая более надежные результаты.
Что дальше?
Предложенные механизмы, Rollout-GDRO и Prompt-GDRO, словно выточенные из камня, обнажают суть проблемы: распределение вычислительных ресурсов и перевзвешивание данных не просто оптимизация, а признание неоднородности ландшафта сложности. Однако, сама идея «групповой сложности» требует дальнейшей деконструкции. Что определяет эту группу? Является ли она статичной или динамически формируется в процессе обучения? Не превращается ли стремление к «устойчивости» в самоцель, отвлекая от истинной задачи — осмысленного решения проблемы, а не просто минимизации риска?
Очевидно, что сокращение дисперсии, достигаемое предложенными методами, — лишь один аспект. Гораздо интереснее исследовать, как адаптивное распределение ресурсов влияет на саму структуру знаний, формирующихся в процессе обучения. Не приводит ли это к упрощению, к отказу от исследования менее очевидных, но потенциально более плодотворных путей? Необходимо помнить: совершенство не в отсутствии шума, а в способности его фильтровать, сохраняя сигнал.
Будущие исследования должны быть направлены не только на повышение эффективности алгоритмов, но и на более глубокое понимание природы сложности. Возможно, истинная ценность предложенного подхода заключается не в его практической реализации, а в том, что он заставляет задуматься о том, что мы на самом деле оптимизируем, и какова цена этой оптимизации.
Оригинал статьи: https://arxiv.org/pdf/2601.19280.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Газовый кризис и валютные риски: что ждет российский рынок? (14.03.2026 18:32)
- Рубль, ставка ЦБ и геополитика: Что ждет российский рынок в ближайшее время
- Будущее WLD: прогноз цен на криптовалюту WLD
- XRP Получил Статус Цифрового Товара: Что Это Значит для Инвесторов и Рынка? (18.03.2026 06:15)
- Является ли эта искусственная интеллект-транспортационная акция самой большой угрозой амбициям Теслы по созданию автономии?
- Нефть, Бюджет и Ставка: Что ждет Российский Рынок в Ближайшее Время? (12.03.2026 15:32)
- Кока-Кола: как одна акция превратилась в 9216, или Капитализм с газировкой 🥤
- Если бы я мог купить и держать только одну акцию, это была бы она.
- ADA рухнет или взлетит? Тайна $0,75 углубляется 🤔
2026-01-29 06:12