Автор: Денис Аветисян
Исследователи предлагают инновационную систему обучения, позволяющую значительно повысить качество рассуждений больших языковых моделей и сделать их более устойчивыми к ошибкам.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал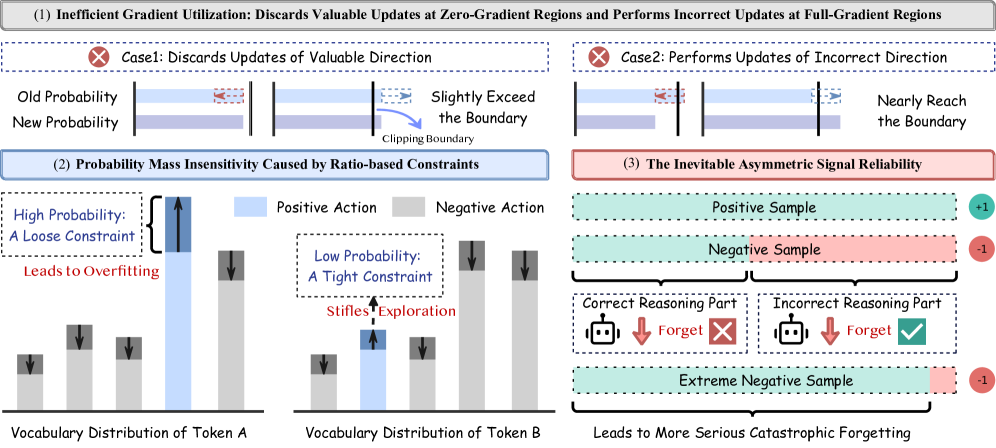
Представленный алгоритм MASPO объединяет использование градиентов, распределение вероятностей и надёжность сигналов для эффективного обучения с подкреплением.
Существующие алгоритмы обучения с подкреплением и верифицируемыми наградами (RLVR) часто страдают от неэффективности при работе со сложной динамикой больших языковых моделей (LLM). В данной работе, представленной под названием ‘MASPO: Unifying Gradient Utilization, Probability Mass, and Signal Reliability for Robust and Sample-Efficient LLM Reasoning’, мы выявляем три ключевые проблемы: неоптимальное использование градиентов, нечувствительность распределения вероятностей и асимметричную надежность сигналов. Для их решения предложен фреймворк Mass-Adaptive Soft Policy Optimization (MASPO), объединяющий дифференцируемое управление градиентами, адаптивный лимитер и асимметричный контроллер рисков. Может ли MASPO стать универсальным решением для повышения надежности и эффективности обучения LLM, способным превзойти существующие подходы?
Хрупкость Разума: Вызовы Надежного Логического Вывода
Несмотря на впечатляющие возможности, демонстрируемые большими языковыми моделями (LLM) в различных задачах, их способность к логическому мышлению остается хрупкой и подверженной ошибкам, особенно при решении сложных проблем. LLM часто демонстрируют уверенность в неверных ответах, что связано с тем, что они основаны на статистических закономерностях в данных, а не на глубоком понимании сути вопроса. Эта «хрупкость» проявляется в чувствительности к незначительным изменениям в формулировке задачи или в наличии отвлекающих факторов, что приводит к резкому снижению точности. В то время как модели могут успешно справляться с простыми вопросами, требующими запоминания информации, они испытывают трудности с задачами, требующими многоступенчатого рассуждения, абстрактного мышления или применения знаний в новых контекстах. Это ограничивает их применение в критически важных областях, где надежность и точность имеют первостепенное значение.
Традиционное обучение с подкреплением, использующее проверяемые награды, представляет собой перспективный подход к улучшению рассуждений больших языковых моделей. Однако, несмотря на теоретическую привлекательность, этот метод сталкивается с серьезными трудностями. Нестабильность процесса обучения часто приводит к колебаниям и сходимости к субоптимальным решениям, а неэффективное исследование пространства политик замедляет прогресс и требует огромных вычислительных ресурсов. Это означает, что модели могут испытывать трудности с обобщением знаний и адаптацией к новым, незнакомым задачам, даже если они успешно справляются с проверенными сценариями. Разработка более устойчивых и эффективных алгоритмов исследования пространства политик является ключевой задачей для реализации полного потенциала обучения с подкреплением в контексте больших языковых моделей.

MASPO: Новая Архитектура для Надежного Обучения
Методика MASPO является развитием алгоритма Soft Policy Optimization (SPO), направленным на повышение эффективности обучения в сложных средах с неоднозначными сигналами вознаграждения. В отличие от стандартного SPO, MASPO использует адаптивные механизмы, позволяющие более эффективно исследовать пространство действий и находить оптимальную политику даже при наличии разреженных или зашумленных вознаграждений. Это достигается за счет динамической настройки параметров обучения, что позволяет алгоритму быстро адаптироваться к изменяющимся условиям среды и избегать застревания в локальных оптимумах. \mathbb{E}_{\tau \sim \pi} [R(\tau)] — ожидаемое вознаграждение, максимизируемое MASPO.
Механизм Mass-Adaptive Limiter, внедренный в MASPO, динамически регулирует границы доверительной области при оптимизации политики. В отличие от фиксированных границ, используемых в традиционных методах, данный механизм адаптирует их размер на основе массы вероятности токенов (tokens). Более высокая масса вероятности указывает на уверенность в предсказании и позволяет уменьшить границы доверительной области для более эффективной эксплуатации. И наоборот, низкая масса вероятности расширяет границы, стимулируя исследование новых действий и предотвращая преждевременную сходимость к локальным оптимумам. Это адаптивное поведение позволяет MASPO эффективно балансировать между исследованием и эксплуатацией, повышая стабильность и скорость обучения в сложных средах.
Асимметричный контроллер риска (Asymmetric Risk Controller) является ключевым нововведением, направленным на повышение стабильности обучения. Он осуществляет модуляцию величины обновлений параметров политики, основываясь на двух основных факторах: уверенности в сигнале (signal confidence) и надежности вознаграждения (reward reliability). Высокая уверенность в сигнале, определяемая, например, дисперсией оценки преимущества, позволяет увеличить величину обновления для ускорения обучения. В то же время, низкая надежность вознаграждения, вызванная шумом или неточностью в оценке, приводит к уменьшению величины обновления для предотвращения расхождения и обеспечения более консервативного и стабильного обучения. Такой асимметричный подход позволяет динамически адаптировать процесс обучения к различным условиям и повысить его устойчивость.
![Архитектура MASP объединяет адаптивный ограничитель массы, масштабирующий ограничения обратно пропорционально вероятности токена, и асимметричный контроль рисков, модулирующий величину обновления на основе сигналов преимущества, используя дифференцируемый механизм мягкого гауссовского гейтинга [latex] \mathcal{G} [/latex].](https://arxiv.org/html/2602.17550v1/x2.png)
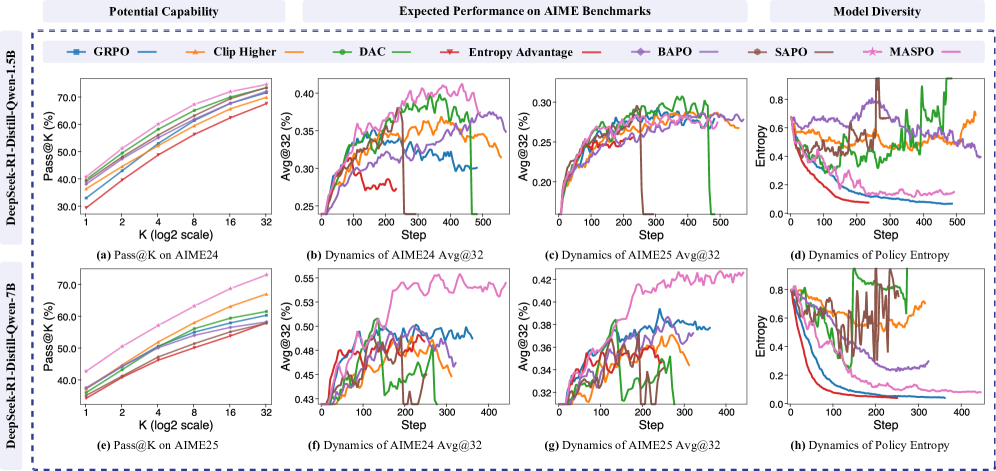
Экспериментальное Подтверждение и Приращение Производительности
В ходе тестирования на наборе данных DAPO-Math-17k, модель MASPO демонстрирует стабильное превосходство над базовым алгоритмом GRPO в задачах математического рассуждения. На модели размером 1.5B, MASPO достигает улучшения показателя Avg@32 на 3.0%, а на 7B модели — на 2.6% по сравнению с GRPO. Данные результаты подтверждают эффективность MASPO в решении сложных математических задач и указывают на её способность к более точным и надёжным рассуждениям.
Для эффективной обработки длинных последовательностей и обучения крупных моделей в MASPO используются такие методы, как PagedAttention и Fully Sharded Data Parallel (FSDP). PagedAttention оптимизирует использование памяти за счет разбиения входных данных на страницы и загрузки только необходимых частей в процессе вычислений. FSDP, в свою очередь, позволяет распределить параметры модели между несколькими графическими процессорами, снижая требования к памяти каждого отдельного устройства и обеспечивая масштабируемость обучения. Комбинация этих методов позволяет MASPO эффективно работать с моделями, содержащими миллиарды параметров, и длинными последовательностями входных данных, что критически важно для сложных задач математического рассуждения.
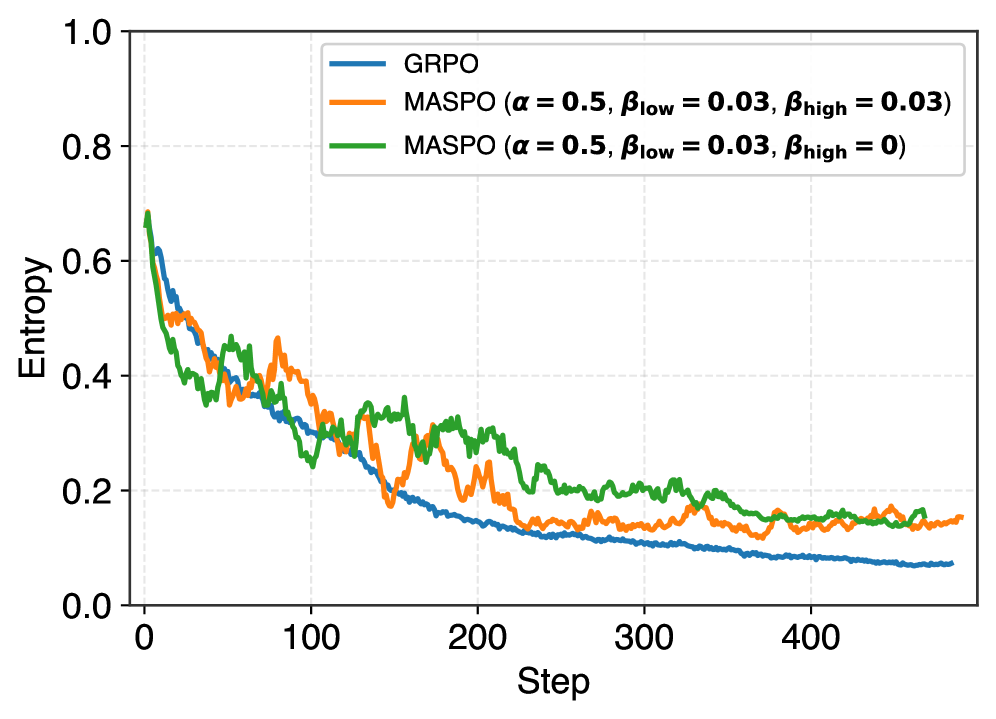
Целевая функция MASPO, основанная на принципе максимальной энтропии и использующая метрику Total Variation Distance, обеспечивает баланс между точностью и устойчивостью модели. Принцип максимальной энтропии позволяет максимизировать неопределенность в распределении вероятностей, что способствует обобщающей способности. Использование Total Variation Distance как регуляризатора минимизирует расстояние между предсказанным распределением вероятностей и равномерным распределением, тем самым повышая устойчивость модели к незначительным изменениям входных данных и предотвращая переобучение. Это обеспечивает надежные результаты даже в условиях неполной или зашумленной информации.
Влияние и Перспективы Развития
Способность MASPO успешно справляться со сложными задачами рассуждения открывает широкие перспективы для областей, требующих надежного и интерпретируемого искусственного интеллекта. В частности, данная технология может значительно ускорить процессы научных открытий, позволяя автоматизировать анализ больших объемов данных и выдвижение гипотез, которые затем проверяются исследователями. Кроме того, MASPO демонстрирует потенциал в области автоматического доказательства теорем, где точность и прозрачность рассуждений имеют первостепенное значение. Возможность построения логически обоснованных цепочек выводов делает систему ценным инструментом для математиков и других ученых, стремящихся к формальной верификации своих результатов. Развитие MASPO может привести к созданию интеллектуальных помощников, способных не только решать сложные задачи, но и объяснять ход своих рассуждений, что повышает доверие к результатам и способствует более глубокому пониманию исследуемых явлений.
В рамках разработанной системы акцент на надёжности сигнала вознаграждения, количественно оцениваемой посредством соотношения сигнал/шум (Signal-to-Noise Ratio, SNR), представляет собой ценный инструмент для оценки качества обучающих сигналов. Высокий SNR указывает на то, что полезная информация, определяющая желаемое поведение, преобладает над случайными помехами, что способствует более эффективному и стабильному обучению. Использование SNR позволяет не только оценить адекватность формируемых вознаграждений, но и выявить потенциальные источники шума в процессе обучения, что критически важно для создания надежных и интерпретируемых моделей искусственного интеллекта. Данный показатель открывает возможности для автоматической настройки параметров обучения и оптимизации стратегий вознаграждения, что в конечном итоге способствует повышению производительности и обобщающей способности алгоритмов.
Предстоит дальнейшее исследование возможностей интеграции MASPO с передовыми стратегиями декодирования, что позволит повысить эффективность и точность решения сложных задач. Особое внимание будет уделено применению данной структуры за пределами математического обоснования, в частности, к областям, требующим надежного и интерпретируемого искусственного интеллекта, таким как научные открытия и автоматизированное доказательство теорем. Расширение области применения MASPO позволит оценить его универсальность и потенциал в решении широкого спектра проблем, а также выявить новые направления для развития алгоритмов искусственного интеллекта, способных к сложному рассуждению и логическому выводу.
Представленная работа демонстрирует стремление к оптимизации процесса обучения больших языковых моделей. В основе MASPO лежит принцип эффективного использования градиентов и адаптации к вероятностным массам, что позволяет повысить надежность и результативность рассуждений модели. Этот подход созвучен высказыванию Джона Маккарти: «Наилучшая вещь в программировании — это то, что ты можешь выразить много вещей небольшим количеством усилий». Упрощение и эффективность, достигнутые в MASPO за счет оптимизации использования сигналов и адаптации политики, являются ярким примером реализации этой идеи в области машинного обучения.
Что Дальше?
Представленный подход, MASPO, пытается обуздать неустойчивость обучения больших языковых моделей. Однако, абстракции стареют. Улучшение использования градиентов, учет массы вероятности и надёжности сигнала — это тактические решения. Стратегическая проблема остается: как создать действительно понимающую систему, а не просто статистическую машину, умело имитирующую рассуждения.
Каждая сложность требует алиби. MASPO смягчает симптомы, но не устраняет первопричину — хрупкость обратной связи в пространствах высокой размерности. Следующим шагом представляется не просто оптимизация алгоритмов, а переосмысление самой постановки задачи обучения. Необходимо искать принципы, устойчивые к шуму и неточностям, принципы, которые не требуют постоянной подстройки под конкретную архитектуру модели.
Поиск надёжности не должен сводиться к усложнению. Необходимо помнить: простота — признак мастерства. Будущие исследования, вероятно, будут сосредоточены на создании более компактных, интерпретируемых моделей, способных к самопроверке и адаптации, а не на бесконечной гонке за параметрами.
Оригинал статьи: https://arxiv.org/pdf/2602.17550.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- ЕвроТранс акции прогноз. Цена EUTR
- Серебро прогноз
- РУСАЛ акции прогноз. Цена RUAL
- Российский рынок: Нефть, дивиденды и геополитика. Что ждет инвесторов? (23.03.2026 18:32)
- Хэдхантер акции прогноз. Цена HEAD
- Крипто-волатильность, лицензии MiCA и риски безопасности: Дайджест главных новостей недели
- Прогноз нефти
- ДЭК акции прогноз. Цена DVEC
- АЛРОСА акции прогноз. Цена ALRS
2026-02-20 11:38