Автор: Денис Аветисян
Исследование предлагает теоретическую основу для более эффективной настройки больших языковых моделей, направленную на улучшение обобщающей способности и предотвращение катастрофического забывания.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал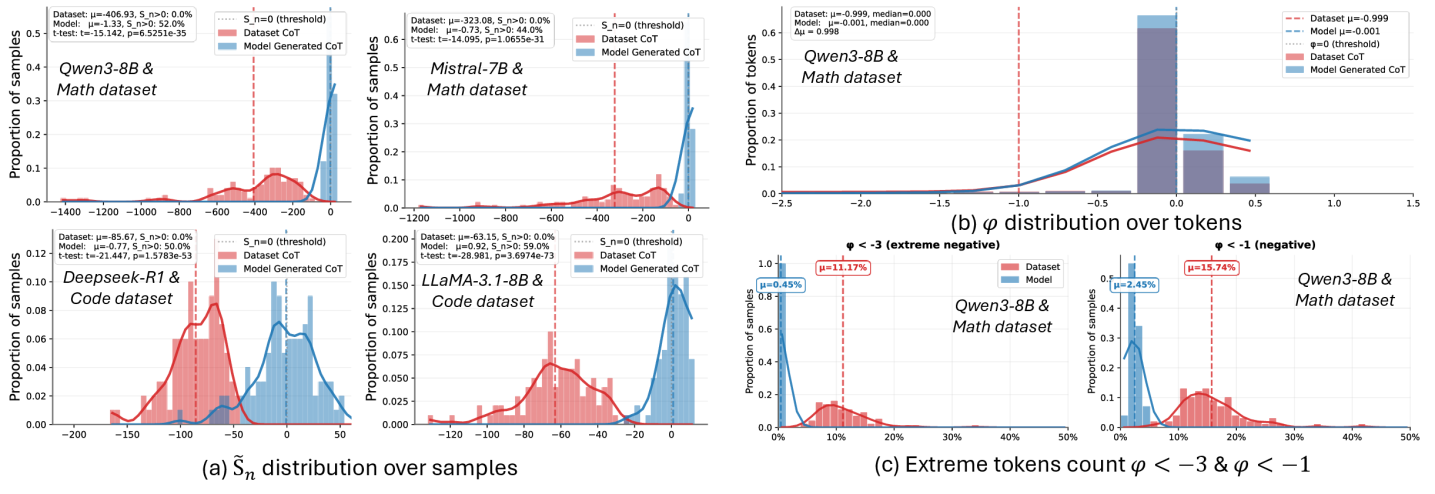
В статье представлена теория дискриминации распределений и ее применение для оптимизации on-policy SFT (Supervised Fine-Tuning).
Несмотря на вычислительную эффективность, контролируемое обучение часто уступает обучению с подкреплением в обобщающей способности. В данной работе, ‘Towards On-Policy SFT: Distribution Discriminant Theory and its Applications in LLM Training’, предложена методология, позволяющая приблизить контролируемое обучение к уровню обучения с подкреплением за счет использования он-полиси данных. Ключевым элементом является разработанная теория дискриминации распределений (Distribution Discriminant Theory), позволяющая количественно оценить и выровнять распределение данных и распределение, индуцированное моделью, а также предложены методы In-Distribution Finetuning и Hinted Decoding. Сможет ли предложенный подход обеспечить практичную альтернативу обучению с подкреплением в тех областях, где его применение затруднено?
Смещение Распределений: Фундаментальный Вызов для Языковых Моделей
Современные большие языковые модели (LLM) демонстрируют впечатляющую способность к генерации текста и решению различных задач, однако их производительность заметно снижается при столкновении с данными, отличными от тех, на которых они обучались. Это явление, известное как смещение распределения, представляет собой фундаментальную проблему, ограничивающую практическое применение LLM в реальных условиях. Модели, обученные на определенном наборе данных, могут испытывать трудности с обработкой информации, отличающейся по стилю, содержанию или тематике, что приводит к снижению точности, релевантности и общей полезности генерируемых результатов. Понимание механизмов, лежащих в основе этой уязвимости, критически важно для разработки более надежных и адаптивных языковых моделей, способных эффективно функционировать в разнообразных и динамично меняющихся средах.
Явление “сдвига распределения” представляет собой фундаментальное ограничение для больших языковых моделей (LLM), существенно влияющее на их применимость в реальных условиях. Производительность LLM неуклонно снижается при столкновении с данными, отличающимися от тех, на которых они обучались, что делает их менее надежными в динамично меняющейся среде. Это несоответствие между тренировочными данными и реальными сценариями требует разработки надежных стратегий адаптации, направленных на повышение устойчивости моделей к новым, неожиданным данным. Необходимость таких стратегий обусловлена тем, что LLM, будучи обученными на определенном наборе данных, склонны к ошибкам при обработке информации, выходящей за рамки этого набора, что препятствует их эффективному использованию в широком спектре практических задач.
Традиционная процедура дообучения с учителем (SFT), несмотря на свою кажущуюся простоту, зачастую усугубляет проблему смещения распределений. В процессе дообучения на новом наборе данных, модель может переобучиться, запоминая специфические особенности этого набора, а не обобщая знания. Это особенно критично, если новый набор данных содержит смещения или не репрезентативен для реального мира. В результате, модель демонстрирует отличные результаты на дообучающем наборе, но её производительность резко снижается при работе с данными, отличающимися от него. Таким образом, SFT, при отсутствии должного контроля и регуляризации, может привести к ухудшению обобщающей способности модели и усилению существующих предвзятостей, что препятствует её надежному применению в реальных условиях.
Для преодоления проблем, связанных со смещением распределений данных, необходимо углубленное понимание того, как большие языковые модели (LLM) представляют и обобщают информацию из различных распределений. Исследования показывают, что LLM не просто запоминают тренировочные данные, но и формируют внутреннее представление о закономерностях, лежащих в их основе. Однако, это представление может быть искажено или неполным, если модель сталкивается с данными, существенно отличающимися от тех, на которых она обучалась. Понимание того, как LLM кодируют эти закономерности, какие признаки оказываются наиболее важными для обобщения, и как различные архитектуры моделей влияют на эту способность, является ключевым для разработки более устойчивых и адаптивных систем. Изучение механизмов обобщения позволит создать стратегии, позволяющие моделям эффективно переносить знания из одного распределения данных в другое, минимизируя влияние смещения и повышая надежность в реальных условиях.
Количественная Оценка Согласованности: CLL и DDT
Центрированная логарифмическая вероятность (CLL) представляет собой строгий статистический подход к количественной оценке соответствия между предсказанным моделью распределением и наблюдаемыми данными. В основе CLL лежит вычисление логарифмической вероятности каждого элемента данных относительно предсказанного распределения, с последующим усреднением этих значений. Этот метод позволяет оценить, насколько хорошо модель захватывает истинное распределение данных, и предоставляет числовую метрику для сравнения различных моделей или конфигураций. В отличие от простых метрик точности, CLL учитывает не только правильные предсказания, но и уверенность модели в этих предсказаниях, что особенно важно для вероятностных моделей. CLL = \frac{1}{N} \sum_{i=1}^{N} log(p(x_i)), где N — количество элементов данных, а p(x_i) — предсказанная моделью вероятность для элемента x_i.
Теория дискриминации распределений (DDT) представляет собой методологию анализа характеристик вероятностных распределений, генерируемых большими языковыми моделями (LLM). В рамках LLM, DDT позволяет оценить, насколько хорошо модель различает различные классы данных и выявляет особенности, определяющие эти различия в распределениях. Применение DDT позволяет характеризовать распределения, описывая их форму, дисперсию и другие статистические параметры, что необходимо для понимания способности модели к генерации реалистичных и когерентных текстов. Анализ с использованием DDT включает в себя оценку φ (отношения сигнал/шум) для определения степени соответствия между предсказанными и эмпирическими распределениями.
Центрированная функция логарифмической правдоподобности (CLL) использует концепцию логарифмической правдоподобности LL(D|M) для оценки соответствия между предсказанным моделью распределением и эмпирическим распределением данных. Логарифмическая правдоподобность количественно определяет, насколько вероятно наблюдение фактических данных, учитывая предсказанное моделью распределение вероятностей. Более высокие значения LL указывают на лучшее соответствие между предсказаниями модели и наблюдаемыми данными, что свидетельствует о более высокой степени согласованности модели с эмпирическим распределением. CLL расширяет этот принцип, центрируя функцию правдоподобности для улучшения статистических свойств и обеспечения более надежной оценки соответствия распределений.
Комбинированное применение метрики Centered Log-Likelihood (CLL) и теории дискриминации распределений (DDT) позволило исследователям достичь среднего значения φ (отношения сигнал/шум) равного -0.032141. Данный результат свидетельствует об улучшении согласованности между предсказанным моделью распределением и эмпирическим распределением данных, что указывает на более точное представление данных и повышение качества модели. Полученное значение φ служит количественной оценкой степени выравнивания, позволяя сравнивать различные модели и методы улучшения согласованности.
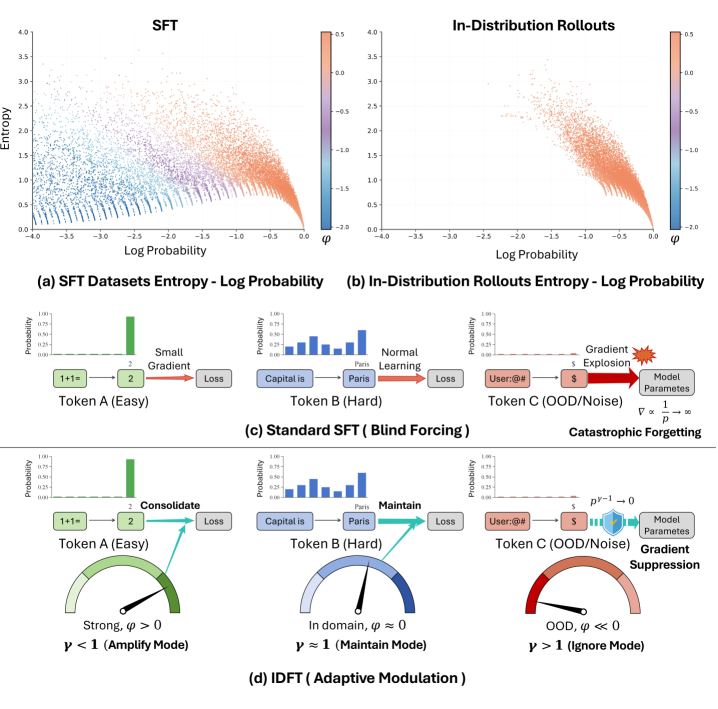
Адаптация в Распределении: Новая Стратегия
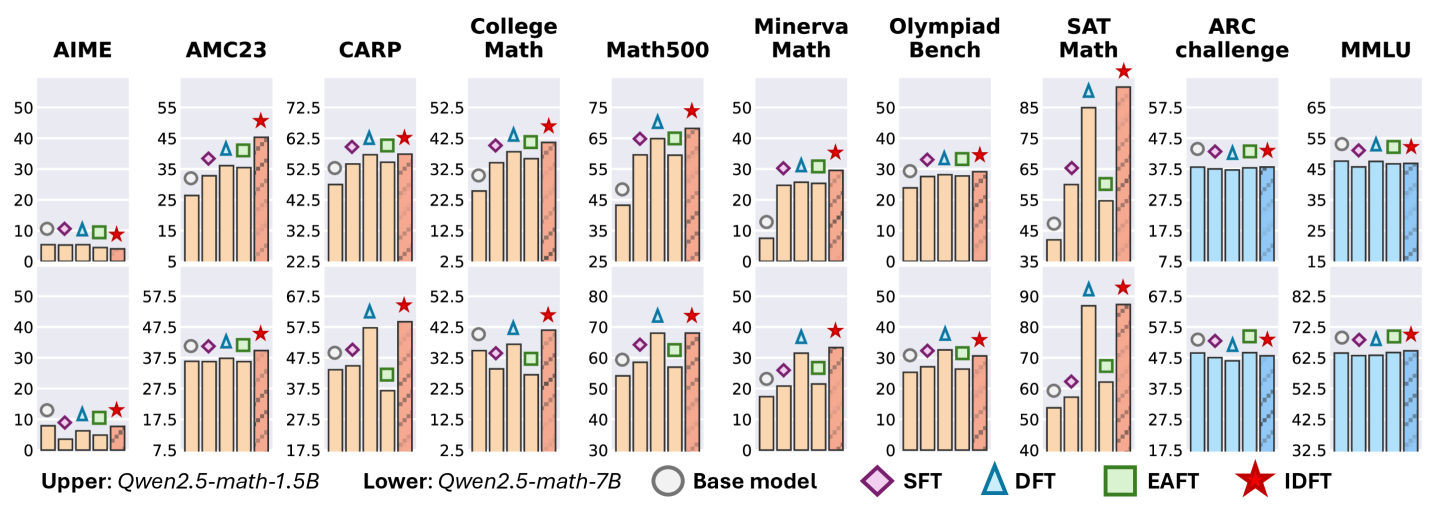
Метод тонкой настройки в распределении (In-Distribution Fine-Tuning, IDFT) представляет собой альтернативу традиционной тонкой настройке с подкреплением (Supervised Fine-Tuning, SFT), фокусируясь на использовании данных, соответствующих существующему распределению модели. В отличие от SFT, который может включать данные из различных источников и, как следствие, приводить к переобучению или усилению предвзятости, IDFT намеренно отдает приоритет данным, которые уже хорошо представлены в исходном наборе данных модели. Такой подход позволяет повысить стабильность обучения, снизить потребность в больших объемах размеченных данных и улучшить обобщающую способность модели, поскольку она учится оптимизировать свою производительность на данных, которые наиболее близки к тем, с которыми она столкнется в реальных условиях.
Метод адаптации IDFT (In-Distribution Fine-Tuning) использует технологию DDT (Distributional Data Tracking) для выявления и приоритезации данных, соответствующих текущему распределению, на котором обучалась модель. Это позволяет снизить риски переобучения и усиления предвзятости, возникающие при использовании данных, значительно отличающихся от исходного распределения. DDT анализирует входящие данные и оценивает их соответствие текущему распределению модели, что позволяет отфильтровать выбросы и аномалии, а также усилить влияние наиболее релевантных примеров. Такой подход обеспечивает более стабильное и надежное обучение, особенно в условиях ограниченного объема данных или при наличии смещенных выборок.
Обучение с подкреплением вне сети (Offline RL) эффективно интегрируется в стратегию точной настройки на данных, соответствующих распределению (IDFT), для дальнейшей оптимизации поведения модели. В рамках IDFT, Offline RL позволяет использовать накопленные данные, не требуя взаимодействия с окружающей средой в процессе обучения. Алгоритмы Offline RL применяются для определения оптимальных действий на основе статистических характеристик данных, соответствующих исходному распределению, что позволяет избежать отклонений от желаемого поведения и усиления существующих смещений. Такой подход позволяет уточнить политику модели, максимизируя вознаграждение, основанное на критериях, соответствующих исходному распределению данных, и обеспечивает более стабильное и предсказуемое поведение модели в процессе эксплуатации.
Подход, основанный на тонкой настройке с использованием данных, соответствующих исходному распределению (In-Distribution Fine-Tuning, IDFT), демонстрирует конкурентоспособные результаты в задачах достижения высокой точности и обобщающей способности, при этом сохраняя эффективность использования данных. В ходе практического применения, команда из Африки выиграла 11 матчей, что подтверждает эффективность данной стратегии, основанной на оптимизированном выравнивании данных и процессе обучения. Достигнутые результаты указывают на способность IDFT эффективно адаптировать модели к целевым задачам, используя ограниченный набор данных и минимизируя риски переобучения.
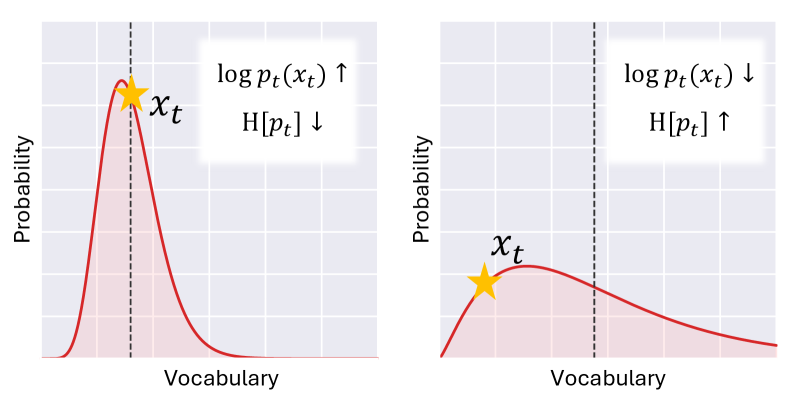
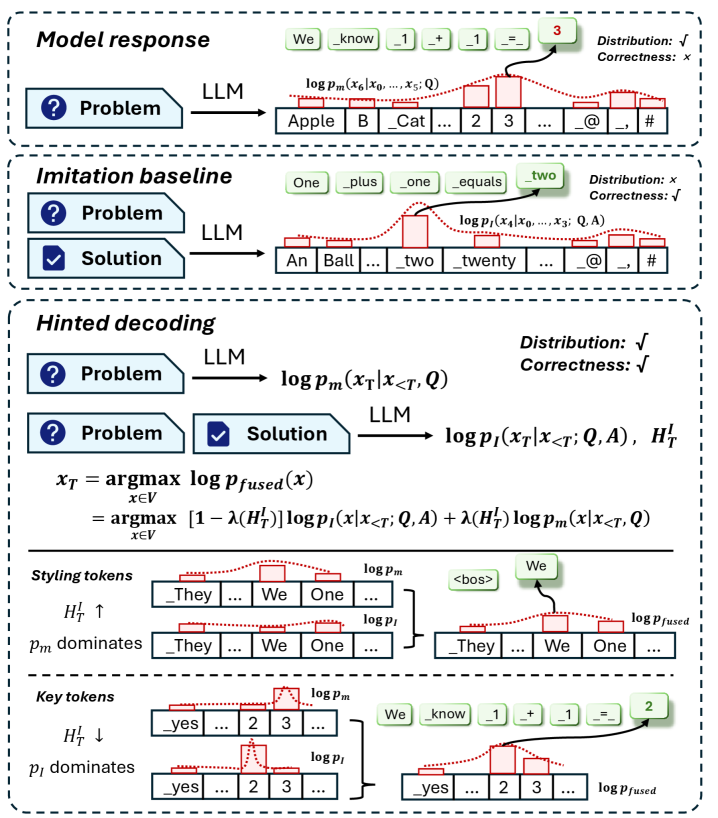
Направление Выходных Данных: Подсказанное Декодирование для Согласованности
Алгоритм “Hinted Decoding” представляет собой метод декодирования, разработанный для согласования генерируемых ответов с базовым распределением вероятностей, заложенным в языковую модель. В отличие от традиционных методов, которые часто фокусируются исключительно на максимизации вероятности следующего токена, “Hinted Decoding” стремится к тому, чтобы выходные данные не только были вероятными, но и отражали более широкое понимание распределения знаний, присущее модели. Это достигается путем интеграции информации о распределении в процесс декодирования, что позволяет избежать генерации ответов, которые, хотя и грамматически верны, могут быть нетипичными или отклоняться от ожидаемого поведения модели. Таким образом, “Hinted Decoding” способствует повышению согласованности и надежности генерируемого текста, делая его более предсказуемым и соответствующим внутренним представлениям модели.
Метод Hinted Decoding направлен на повышение стабильности и предсказуемости ответов языковых моделей. В отличие от традиционных методов декодирования, Hinted Decoding учитывает вероятностное распределение, присущее самой модели, и интегрирует эту информацию в процесс генерации текста. Это позволяет модели не просто выбирать наиболее вероятное слово на каждом шаге, но и учитывать, насколько данный выбор соответствует общему распределению вероятностей, сформированному в процессе обучения. В результате, генерируемые тексты становятся более согласованными, менее подвержены случайным отклонениям и демонстрируют большую надежность, что особенно важно для приложений, требующих высокой точности и предсказуемости.
Взаимодействие алгоритма Hinted Decoding с методом IDFT (In-Distribution Fine-Tuning) позволяет добиться синергетического эффекта, значительно снижая риски, связанные с изменением распределения данных. Данный подход предполагает, что IDFT, настраивая модель на более узкое, стабильное распределение входных данных, создает оптимальную основу для Hinted Decoding. В свою очередь, Hinted Decoding, используя информацию о вероятностном распределении, генерируемом моделью, стабилизирует выходные данные и предотвращает отклонения от желаемого стиля и содержания. Такое комбинированное применение позволяет не только повысить надежность и предсказуемость больших языковых моделей, но и смягчить проблемы, возникающие при работе с данными, отличающимися от тех, на которых модель изначально обучалась, обеспечивая более устойчивые и согласованные результаты.
В основе метода Hinted Decoding лежит использование расхождения Кульбака-Лейблера KL в качестве ключевой метрики для повышения контролируемости и надёжности больших языковых моделей. Этот подход позволяет оценивать разницу между распределением вероятностей, генерируемым моделью, и её исходным, обучающим распределением. Минимизируя KL-дивергенцию в процессе декодирования, Hinted Decoding направляет генерацию ответов ближе к ожидаемым результатам, снижая вероятность отклонений и обеспечивая большую согласованность. Такое количественное измерение отклонений позволяет не только улучшить предсказуемость ответов, но и предоставляет инструменты для тонкой настройки моделей, делая их более устойчивыми к изменениям входных данных и повышая доверие к генерируемому контенту.
Исследование, представленное в статье, демонстрирует стремление к математической строгости в области обучения больших языковых моделей. Авторы предлагают теоретическую основу для оценки и согласования распределений, что находит отклик в словах Ады Лавлейс: «Я верю, что машинами можно управлять для выполнения любых операций, если эти операции могут быть сведены к логическим операциям». Подобно тому, как Лавлейс предвидела возможности вычислительных машин, данная работа стремится к четкому определению принципов, управляющих обучением моделей, и разработке методов, позволяющих достичь оптимальной производительности и избежать катастрофического забывания. Акцент на распределении и дискриминации подчеркивает стремление к созданию алгоритмов, которые не просто ‘работают’, но и имеют доказуемую логическую основу.
Куда Ведут Дальнейшие Исследования?
Представленная работа, хотя и предлагает формальный аппарат для оценки и согласования распределений языковых моделей, оставляет ряд вопросов нерешенными. Особую озабоченность вызывает зависимость предложенных метрик от конкретного выбора логарифмического преобразования. Поиск инвариантных к преобразованиям характеристик распределений представляется задачей, требующей дальнейшей теоретической проработки. Необходимо помнить: элегантность алгоритма не в количестве строк кода, а в его способности к масштабированию и асимптотической устойчивости.
Практическое применение теории дискриминации распределений сталкивается с трудностями, связанными с оценкой истинного распределения данных. Предположение о доступности репрезентативной выборки, пусть и необходимое для формализации, часто не соответствует действительности. Разработка робастных методов оценки, устойчивых к шумам и смещениям в данных, представляется критически важной. Необходимо избегать соблазна упрощать задачу, полагаясь на эмпирические тесты вместо доказательств.
В перспективе, представляется плодотворным исследование связей между теорией дискриминации распределений и другими направлениями, такими как теория обнаружения сигналов и информационная теория. Понимание фундаментальных ограничений, накладываемых природой данных, позволит разработать более эффективные и надежные методы обучения языковых моделей, способные не только генерировать текст, но и понимать его смысл. Истинная задача не в создании иллюзии интеллекта, а в приближении к математической точности.
Оригинал статьи: https://arxiv.org/pdf/2602.12222.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Недвижимость и авиа: что ждет потребителей в России? Анализ рынка и новые маршруты (28.03.2026 19:32)
- Будущее FET: прогноз цен на криптовалюту FET
- Супернус: Продажа Акций и Нервные Тики
- Инвестиционный обзор и ключевые инвестиционные идеи воскресенье, 22 марта 2026 9:26
- Управление рисками в условиях неопределенности: современные подходы
- АЛРОСА акции прогноз. Цена ALRS
- ЛУКОЙЛ акции прогноз. Цена LKOH
- СириусXM: Пыль дорог и звон монет
- Будущее KAS: прогноз цен на криптовалюту KAS
2026-02-14 17:34