Автор: Денис Аветисян
Новое исследование предлагает эффективный подход к настройке скорости обучения при предварительном обучении больших языковых моделей, позволяющий значительно повысить эффективность и масштабируемость процесса.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал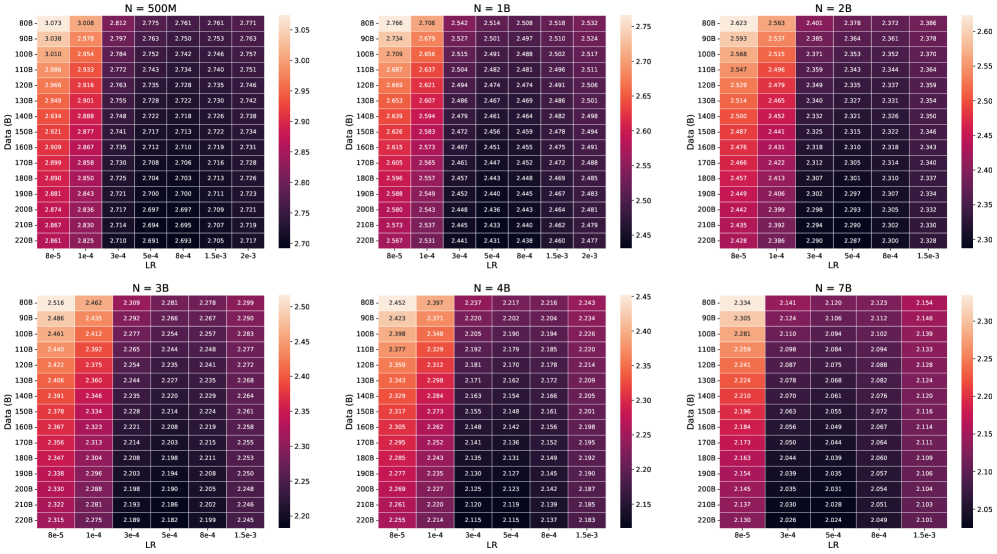
Работа исследует методы настройки скорости обучения, основанные на законах масштабирования и переносе знаний, и демонстрирует превосходство подхода, основанного на подгонке параметров.
Оптимальная настройка скорости обучения остается сложной задачей при масштабном предварительном обучении больших языковых моделей. В работе ‘How to Set the Learning Rate for Large-Scale Pre-training?’ предложен анализ двух подходов — Fitting и Transfer — к решению этой проблемы. Авторы демонстрируют, что использование масштабируемых законов в парадигме Fitting превосходит широко распространенный метод μTransfer по эффективности и масштабируемости. Какие новые стратегии оптимизации скорости обучения позволят еще больше ускорить предварительное обучение и улучшить производительность моделей в будущем?
Масштабирование Больших Языковых Моделей: Вызовы и Перспективы
Недавние достижения в области больших языковых моделей (БЯМ) демонстрируют впечатляющие возможности в генерации текста, переводе и понимании языка, однако эффективное масштабирование этих моделей остается серьезной проблемой. Увеличение количества параметров и обучающих данных, хотя и приводит к улучшению производительности, сопряжено с экспоненциальным ростом вычислительных затрат и требований к памяти. Это создает значительные препятствия для дальнейшего развития и широкого внедрения БЯМ, поскольку доступ к необходимым ресурсам ограничен, а обучение и развертывание моделей становятся все более дорогостоящими. Таким образом, несмотря на прогресс, остается необходимость в инновационных подходах к масштабированию, которые позволят преодолеть существующие ограничения и раскрыть весь потенциал больших языковых моделей.
Традиционные подходы к масштабированию больших языковых моделей, несмотря на первоначальный прогресс, всё чаще сталкиваются с законом убывающей отдачи. Увеличение размера модели и объёма данных для обучения требует экспоненциального роста вычислительных ресурсов и энергопотребления, что приводит к значительному увеличению стоимости и снижению практической применимости. Например, удвоение размера модели не всегда приводит к пропорциональному улучшению её производительности, а стоимость обучения может возрастать в разы. Эта тенденция ограничивает возможности широкого внедрения передовых моделей, особенно в условиях ограниченных ресурсов, и подталкивает исследователей к поиску более эффективных методов масштабирования, позволяющих добиться существенного улучшения производительности при разумных затратах.
Поиск более эффективных методов масштабирования имеет решающее значение для раскрытия полного потенциала больших языковых моделей и обеспечения возможности выполнения ими более сложных рассуждений. Традиционное увеличение размера моделей часто сталкивается с законом убывающей доходности и экспоненциальным ростом вычислительных затрат, что ограничивает их практическое применение. Разработка инновационных подходов, таких как разреженное обучение, квантование и архитектурные оптимизации, направлена на повышение эффективности использования ресурсов и снижение энергопотребления, что позволит создавать модели, способные решать задачи, требующие глубокого понимания и логического вывода. Эти усилия не только расширят спектр решаемых задач, но и сделают большие языковые модели более доступными для широкого круга исследователей и разработчиков, способствуя дальнейшему прогрессу в области искусственного интеллекта.
Новый Подход к Конфигурации Скорости Обучения
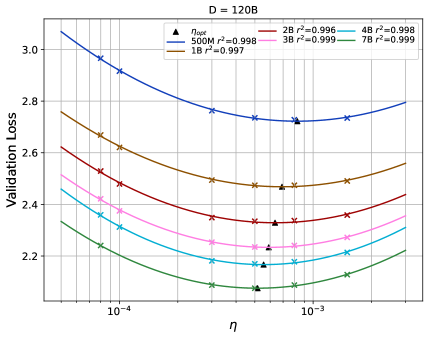
В настоящее время стратегии конфигурации скорости обучения доминируют в двух основных парадигмах: подходе, основанном на подгонке (fitting-based), и подходе, основанном на переносе знаний (transfer-based). Парадигма подгонки предполагает непосредственное моделирование зависимости между скоростью обучения и функцией потерь на валидационной выборке, что позволяет достичь высокой точности аппроксимации, превышающей 0.995. В свою очередь, парадигма переноса знаний использует информацию, полученную при обучении небольших «прокси»-моделей, для ускорения конфигурации параметров для более крупных целевых моделей. Каждый из подходов обладает своими преимуществами и подходит для решения различных задач оптимизации.
Подход, основанный на подгонке (fitting paradigm), представленный методом квадратичной полиномиальной подгонки (Quadratic Polynomial Fitting), напрямую моделирует зависимость между скоростью обучения и величиной валидационной ошибки. Этот метод демонстрирует высокую точность подгонки — более 99.5% — при аппроксимации кривой валидационной ошибки. Фактически, это позволяет построить аналитическую модель, описывающую оптимальную скорость обучения для минимизации валидационной ошибки, что исключает необходимость в дорогостоящем поиске по гиперпараметрам.
В отличие от методов, основанных на подгонке кривых, передаточный подход, например, μTransfer, использует знания, полученные на небольших моделях-прокси, для ускорения конфигурирования более крупных целевых моделей. Наша методика позволяет снизить вычислительную сложность поиска оптимальной конфигурации с 𝒪(n³) до 𝒪(n⋅CD⋅Cη), где n — размер целевой модели, CD — размерность пространства конфигураций, а Cη — коэффициент, отражающий эффективность переноса знаний из модели-прокси.
Оптимизация Архитектуры Mixture of Experts: Ключевые Методы
Архитектура Mixture of Experts (MoE), на примере Qwen3-MoE, представляет собой подход к масштабированию моделей машинного обучения, позволяющий значительно увеличить их емкость при сохранении вычислительной эффективности. В отличие от традиционных плотных моделей, MoE использует несколько “экспертов” — подсетей, каждая из которых специализируется на обработке определенной части входных данных. Механизм маршрутизации (routing) динамически направляет каждый входной токен к одному или нескольким наиболее подходящим экспертам. Это позволяет модели обрабатывать значительно больше параметров, чем в плотной модели аналогичного размера, поскольку не все параметры активируются для каждого входного токена, снижая вычислительные затраты и требования к памяти.
Эффективное обучение моделей типа Mixture of Experts (MoE) требует тщательной настройки параметров скорости обучения. Часто для этого применяется оптимизатор AdamW, который сочетает в себе преимущества Adam и весовой регуляризации. AdamW использует децентрализованный алгоритм адаптивной оценки скорости обучения для каждого параметра, что позволяет быстро сходиться и избегать локальных минимумов. Весовая регуляризация (L2-регуляризация) предотвращает переобучение модели, особенно при работе с большим количеством параметров, характерным для MoE-архитектур. Правильная конфигурация параметров AdamW, включая скорость обучения, коэффициенты бета-распада и вес регуляризации, критически важна для достижения стабильного обучения и оптимальной производительности модели.
Предварительное обучение моделей Mixture of Experts (MoE) с использованием графика Warmup-Stable-Decay (WSD), в сочетании со стандартной параметризацией, является критически важным для достижения оптимальной производительности и стабильности процесса обучения. Данный подход предусматривает начальный период прогрессивного увеличения скорости обучения (Warmup), за которым следует фаза поддержания стабильной скорости (Stable), и завершается этапом постепенного снижения (Decay). Эффективность данной стратегии подтверждена экспериментально на моделях размером до 12 миллиардов параметров, обученных на корпусе в 500 миллиардов токенов, что демонстрирует ее масштабируемость и надежность для задач предварительного обучения моделей MoE.
![Зависимость скорости обучения η, размера модели [latex] NN [/latex] и объема обучающих данных [latex] DD [/latex] демонстрирует, что для достижения оптимальной производительности необходимо учитывать взаимосвязь между этими параметрами.](https://arxiv.org/html/2601.05049v1/x28.png)
Результаты Валидации и Бенчмарки: Подтверждение Эффективности
Тщательная оценка предобученных моделей осуществлялась с использованием общепринятых бенчмарков, таких как MMLU и CMMLU, что позволило объективно измерить их способности к решению разнообразных задач. Для упрощения и стандартизации этого процесса применялась платформа OpenCompass, обеспечивающая воспроизводимость результатов и удобство сравнения с другими моделями. Использование этих бенчмарков и фреймворков гарантирует надежность оценки и позволяет исследователям и разработчикам ориентироваться в постоянно развивающейся области больших языковых моделей, определяя наиболее эффективные и перспективные решения.
Проведенные исследования демонстрируют значительное повышение эффективности модели благодаря оптимизированным конфигурациям скорости обучения. На стандартных бенчмарках, таких как MMLU и CMMLU, удалось добиться прироста точности в 1.28% и 2.23% соответственно, при использовании 4-х миллиардной модели с полной тренировкой WSD. Данный результат превосходит показатели μTransfer, подтверждая, что тщательно подобранные параметры обучения играют ключевую роль в достижении более высокой производительности и точности ответов модели.
Для упрощения развертывания и повышения доступности моделей, применяются специализированные фреймворки, такие как LMDeploy. Данные инструменты позволяют значительно ускорить загрузку моделей и оптимизировать процесс инференса, что особенно важно для приложений, требующих высокой производительности и минимальной задержки. Благодаря эффективной организации данных и оптимизации вычислений, LMDeploy обеспечивает более быструю обработку запросов и снижение потребления ресурсов, делая современные языковые модели более практичными и доступными для широкого круга пользователей и разработчиков. Это способствует более быстрому внедрению передовых технологий в различные сферы, от автоматизированной обработки текстов до создания интеллектуальных помощников.
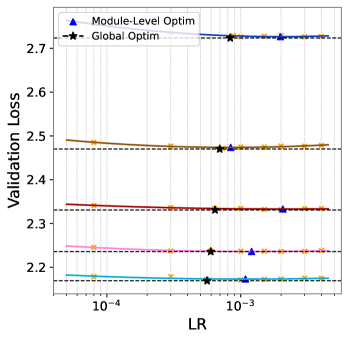
![Результаты обучения 4B модели на 120B токенах показывают, что оптимизация скорости обучения для каждого модуля не даёт существенного улучшения производительности по сравнению с глобально оптимальной скоростью обучения [latex]\Delta L \leq 0.01[/latex].](https://arxiv.org/html/2601.05049v1/x10.png)
Исследование, представленное в данной работе, подчеркивает важность тщательной настройки гиперпараметров, в частности, скорости обучения, при масштабировании предварительного обучения больших языковых моделей. Авторы демонстрируют, что подход, основанный на масштабировании законов, превосходит традиционные методы, такие как μTransfer, обеспечивая более эффективное использование вычислительных ресурсов и улучшенную масштабируемость. Это подтверждает мысль Дональда Кнута: «Прежде чем оптимизировать код, убедитесь, что вы оптимизируете правильный алгоритм». В контексте данной работы, это означает, что выбор подходящей стратегии обучения, основанной на фундаментальных принципах масштабирования, важнее, чем тонкая настройка отдельных параметров в неэффективной схеме. Элегантность в архитектуре обучения, как и в любой системе, заключается в простоте и ясности базовых принципов.
Куда Дальше?
Исследование, представленное в данной работе, выявляет закономерности в настройке скорости обучения для масштабного предварительного обучения больших языковых моделей. Однако, кажущаяся элегантность подхода, основанного на масштабируемых законах, не должна заслонять более глубокие вопросы. Устойчивость этой парадигмы требует дальнейшей проверки в условиях, существенно отличающихся от тех, что были рассмотрены — например, при работе с данными, значительно отличающимися по структуре и объему. Оптимизация скорости обучения, как и любая попытка упростить сложность, неизбежно сталкивается с границами своей применимости.
Очевидно, что стремление к универсальным решениям в области гиперпараметров — это своего рода иллюзия. Каждая архитектура, каждый набор данных, каждая задача — это уникальный организм, требующий индивидуального подхода. Попытки создать единую формулу, применимую ко всем случаям, обречены на неудачу. Более перспективным представляется развитие методов автоматической адаптации скорости обучения, учитывающих внутреннюю структуру модели и характеристики данных в реальном времени.
В конечном счете, вопрос заключается не только в поиске оптимальной скорости обучения, но и в понимании фундаментальных принципов, определяющих поведение больших языковых моделей. Необходимо углубить исследования в области теории обучения и статистической физики, чтобы разработать более надежные и устойчивые алгоритмы. Простота и ясность — вот что действительно важно, а не бесконечное усложнение и оптимизация отдельных параметров.
Оригинал статьи: https://arxiv.org/pdf/2601.05049.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Капитал Б&Т и его душа в AESI
- Почему акции Pool Corp могут стать привлекательным выбором этим летом
- Стоит ли покупать фунты за йены сейчас или подождать?
- Квантовые Химеры: Три Способа Не Потерять Рубль
- Два актива, которые взорвут финансовый Лас-Вегас к 2026
- МКБ акции прогноз. Цена CBOM
- Один потрясающий рост акций, упавший на 75%, чтобы купить во время падения в июле
- Будущее ONDO: прогноз цен на криптовалюту ONDO
- Делимобиль акции прогноз. Цена DELI
- Российский рынок: Рост на фоне Ближнего Востока и сырьевая уверенность на 100 лет (28.02.2026 10:32)
2026-01-10 07:29