Автор: Денис Аветисян
Исследователи предлагают усовершенствованные алгоритмы оптимизации, позволяющие ускорить и повысить качество обучения крупных языковых моделей.
Представлены алгоритмы NAMO и NAMO-D, сочетающие ортогонализированный импульс и адаптивное управление шумом для повышения скорости сходимости и улучшения результатов обучения.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм каналЭффективная стохастическая оптимизация требует баланса между стабильностью в детерминированном режиме и адаптацией к случайным возмущениям. В статье ‘Adam Improves Muon: Adaptive Moment Estimation with Orthogonalized Momentum’ предложены новые алгоритмы NAMO и NAMO-D, сочетающие ортогонализированный импульс с адаптивным контролем шума, что позволяет улучшить производительность при обучении больших языковых моделей. Эти алгоритмы, использующие единый адаптивный шаг и диагональное расширение, демонстрируют оптимальные скорости сходимости и адаптируются к уровню шума в стохастических градиентах. Смогут ли предложенные методы NAMO и NAMO-D стать новым стандартом для оптимизации в задачах глубокого обучения и открыть путь к созданию еще более мощных языковых моделей?
Сложность Стохастической Оптимизации
Обучение современных моделей глубокого обучения практически всегда опирается на стохастический градиентный спуск, метод, в котором для аппроксимации истинного градиента используется лишь небольшая случайная выборка данных. Такой подход, хотя и позволяет значительно ускорить процесс обучения по сравнению с использованием всего набора данных, неизбежно вносит значительную дисперсию в оценки градиента. Эта дисперсия, в свою очередь, может приводить к колебаниям в процессе оптимизации, затрудняя сходимость алгоритма к оптимальному решению и требуя более тщательной настройки гиперпараметров, таких как скорость обучения. По сути, стохастичность процесса обучения является компромиссом между скоростью и точностью, и эффективное управление этой стохастичностью является ключевой задачей при обучении сложных нейронных сетей.
В процессе обучения сложных нейронных сетей, традиционные алгоритмы оптимизации зачастую сталкиваются с серьезными трудностями на так называемых «плохо обусловленных» поверхностях потерь. Эти поверхности характеризуются резкими изменениями кривизны, где градиент может быть очень большим в одном направлении и очень маленьким в другом. В результате, алгоритм может совершать «зигзагообразные» движения, требуя значительно больше итераций для достижения сходимости, либо демонстрировать нестабильное поведение, приводящее к расхождению. Такая проблема особенно актуальна для глубоких сетей с большим количеством параметров, где поверхность потерь становится чрезвычайно сложной и многомерной, требуя более продвинутых методов оптимизации для эффективного обучения и достижения оптимальной производительности.
Преодоление трудностей, связанных со стохастической оптимизацией, является ключевым фактором для дальнейшего масштабирования моделей глубокого обучения и достижения оптимальных результатов в решении сложных задач. По мере увеличения размеров моделей и сложности решаемых ими проблем, традиционные методы оптимизации демонстрируют ограниченную эффективность, сталкиваясь с нестабильностью и замедлением сходимости. Успешное решение этих проблем позволит не только обучать более крупные и мощные нейронные сети, но и существенно повысить точность и надежность систем искусственного интеллекта, применяемых в различных областях, от обработки естественного языка до компьютерного зрения и робототехники. Разработка и внедрение инновационных алгоритмов оптимизации, способных эффективно справляться с «зашумленными» градиентами и сложными ландшафтами функций потерь, открывает новые горизонты для развития искусственного интеллекта и расширения спектра его возможностей.
NAMO и NAMO-D: Адаптивная Оптимизация
Алгоритм NAMO объединяет ортогонализированный импульс (orthogonalized momentum) с адаптивным управлением шумом для динамической корректировки скорости обучения и стабилизации процесса тренировки. Ортогонализация импульса направлена на уменьшение корреляции между обновлениями параметров, предотвращая осцилляции и ускоряя сходимость. Адаптивное управление шумом в NAMO вносит контролируемые случайные возмущения в градиент, что позволяет алгоритму «выскакивать» из локальных минимумов и исследовать пространство параметров более эффективно. Динамическая корректировка скорости обучения, основанная на анализе градиентов и их дисперсии, обеспечивает оптимальный шаг обучения на каждой итерации, предотвращая как чрезмерно медленную, так и нестабильную сходимость. \nabla\theta = \nabla\theta + v где v — импульс, корректируемый ортогонализацией и адаптивным шумом.
Алгоритм NAMO-D развивает подход, используемый в NAMO, за счет внедрения адаптивного размера шага, применяемого по столбцам матрицы весов. Это позволяет осуществлять более точную настройку шума для каждого параметра модели, что особенно важно для задач с высокой размерностью. В отличие от глобального адаптивного размера шага, применяемого в NAMO, NAMO-D позволяет учитывать индивидуальные характеристики градиентов для каждого столбца, тем самым снижая дисперсию и ускоряя сходимость процесса обучения. Экспериментальные результаты демонстрируют, что такая гранулярная адаптация шага приводит к улучшению производительности по сравнению с традиционными методами оптимизации и базовым алгоритмом NAMO.
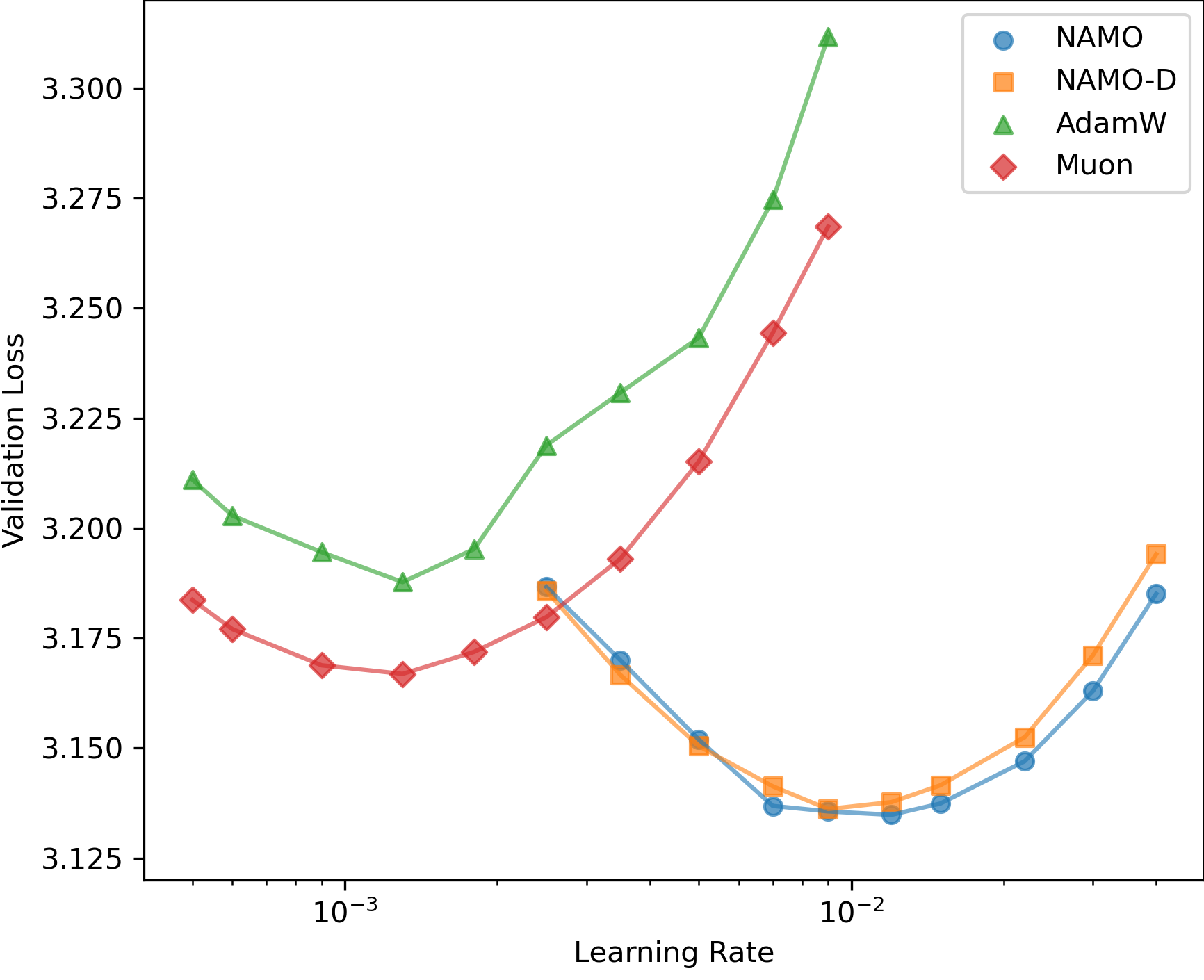
Оба алгоритма, NAMO и NAMO-D, используют адаптивный размер шага обучения, что позволяет динамически регулировать скорость сходимости в процессе оптимизации. Ключевым аспектом является учет взаимосвязи между размером шага и дисперсией градиента. Высокая дисперсия градиента указывает на нестабильность обучения, и в этом случае алгоритмы уменьшают размер шага для стабилизации процесса. И наоборот, при низкой дисперсии градиента размер шага может быть увеличен для ускорения сходимости. Такой подход позволяет эффективно адаптироваться к различным характеристикам функции потерь и улучшить общую производительность алгоритма, избегая как чрезмерно медленного, так и нестабильного обучения. \sigma^2 — дисперсия градиента.
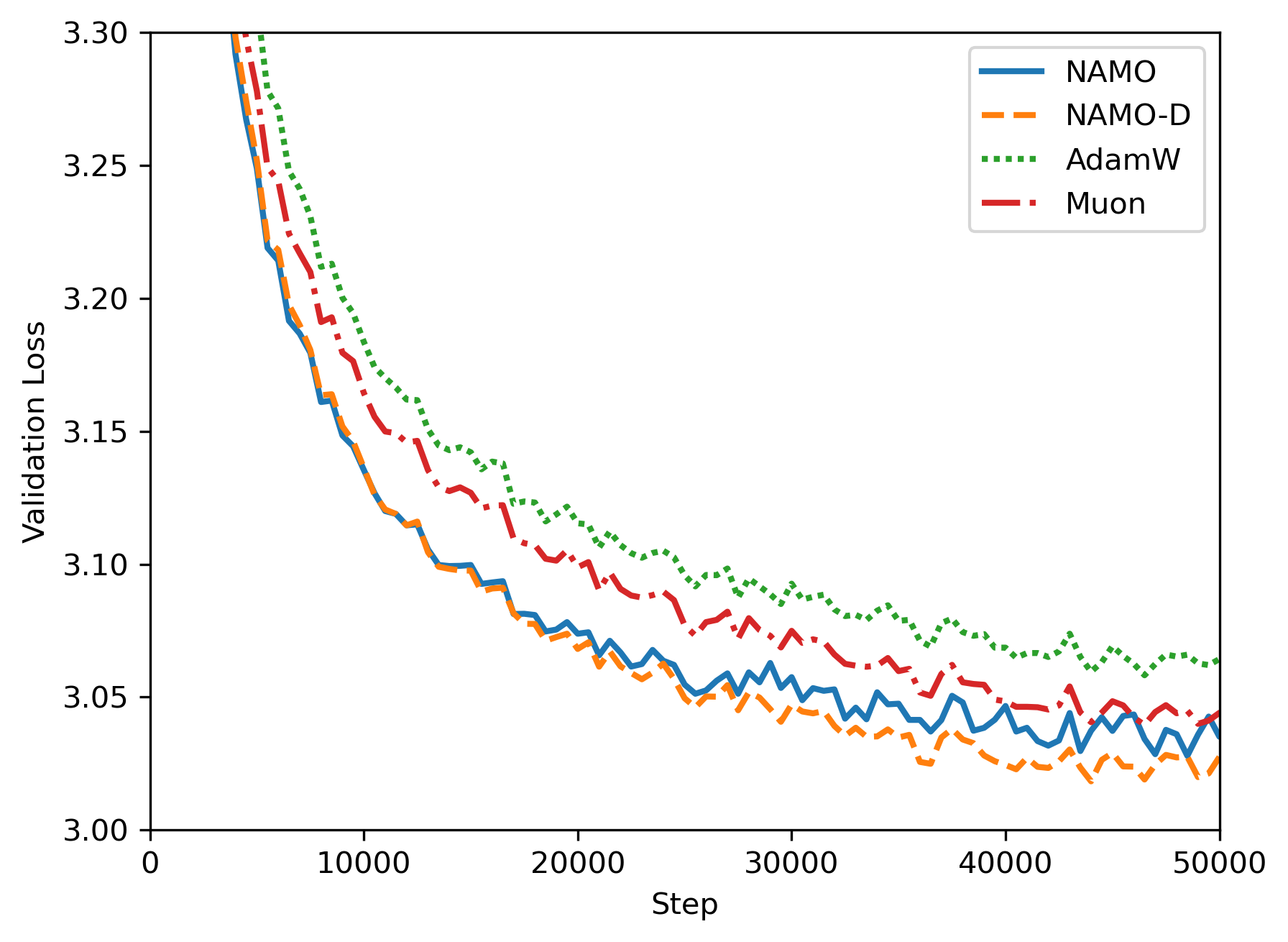
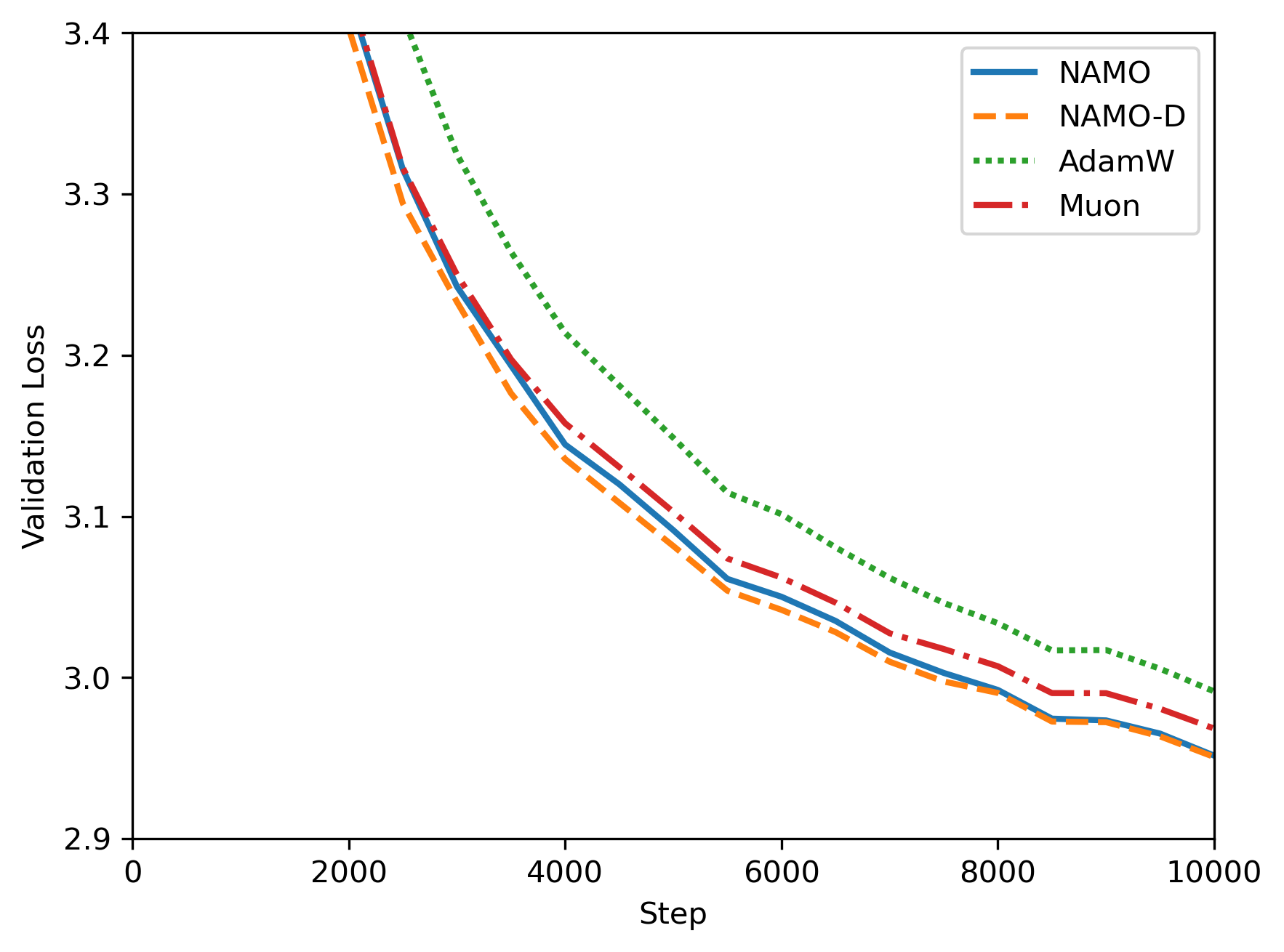
Подтверждение Эффективности на Предобучении GPT-2
Для оценки эффективности алгоритмов NAMO и NAMO-D была проведена серия экспериментов с задачей предварительного обучения на модели GPT-2. Данная задача является общепринятым стандартом (бенчмарком) для оценки и сравнения различных методов оптимизации, применяемых при обучении больших языковых моделей. Использование GPT-2 в качестве тестовой платформы позволяет объективно сопоставить производительность NAMO и NAMO-D с существующими алгоритмами, такими как AdamW и Muon, в условиях, воспроизводимых другими исследователями.
В ходе оценки алгоритмов NAMO и NAMO-D на задаче предварительного обучения GPT-2, было установлено, что они демонстрируют стабильное превосходство над базовыми алгоритмами оптимизации, такими как AdamW и Muon. Экспериментальные данные показали следующую иерархию производительности: NAMO-D > NAMO > Muon > AdamW. Данный порядок указывает на то, что NAMO-D обеспечивает наилучшие результаты, за ним следует NAMO, далее Muon и, наконец, AdamW, что подтверждается количественными метриками, полученными в ходе обучения языковой модели.
Алгоритм NAMO-D демонстрирует существенное улучшение производительности благодаря усовершенствованной стратегии адаптации шума и использованию диагональной матрицы для адаптивного масштабирования. В отличие от традиционных методов, NAMO-D динамически регулирует масштаб обновления параметров для каждого элемента градиента, используя диагональную матрицу, что позволяет более эффективно справляться с проблемой затухания или взрыва градиентов. Уточненная стратегия адаптации шума позволяет алгоритму более гибко реагировать на изменения в распределении градиентов во время обучения, что способствует более стабильной и быстрой сходимости. Данный подход особенно эффективен в задачах предварительного обучения языковых моделей, таких как GPT-2, где размерность пространства параметров высока и градиенты могут быть нестабильными.
В алгоритме NAMO-D параметр обрезки (clamping) играет ключевую роль в обеспечении баланса между хорошо обусловленными обновлениями и адаптацией к шуму. Этот параметр ограничивает величину изменений параметров во время обучения, предотвращая чрезмерно большие шаги, которые могут возникать из-за шума в градиентах. Ограничение величины обновления позволяет алгоритму сохранять стабильность и избегать расхождения, особенно на этапах обучения с высокой степенью неопределенности. При этом, обрезка не препятствует эффективной адаптации к шуму, поскольку позволяет сохранить чувствительность к полезным сигналам в градиентах, что способствует более быстрой сходимости и улучшению обобщающей способности модели. Эффективное управление этим параметром позволяет NAMO-D достигать лучших результатов по сравнению с другими оптимизаторами, такими как AdamW и Muon.
Значение и Перспективы Развития
Достижение оптимальных скоростей сходимости алгоритмами NAMO и NAMO-D открывает значительные перспективы для ускорения процесса обучения и повышения обобщающей способности моделей глубокого обучения. Более быстрая сходимость не только сокращает время, необходимое для тренировки сложных нейронных сетей, но и позволяет исследовать более широкий спектр гиперпараметров и архитектур, что, в свою очередь, может привести к созданию моделей с повышенной точностью и устойчивостью к переобучению. В частности, это особенно важно для задач, требующих обработки больших объемов данных, таких как компьютерное зрение и обработка естественного языка, где время обучения часто является критическим фактором. Повышение обобщающей способности, в свою очередь, означает, что обученная модель сможет более эффективно работать с новыми, ранее не встречавшимися данными, что является ключевым требованием для успешного применения в реальных условиях.
Механизм адаптивного контроля шума представляет собой эффективный подход к решению проблемы зашумленных градиентов, часто возникающей в распределенном обучении и обучении с подкреплением. В процессе обучения глубоких нейронных сетей, особенно в сложных, распределенных системах, градиенты, используемые для обновления весов, могут быть подвержены значительным колебаниям из-за различных факторов, таких как стохастичность мини-пакетов или несогласованность данных между узлами. Данный механизм динамически регулирует уровень добавляемого шума, стремясь компенсировать эти нежелательные колебания и стабилизировать процесс обучения. По сути, он позволяет моделям более эффективно ориентироваться в зашумленном пространстве параметров, ускоряя сходимость и повышая общую производительность, особенно в сценариях, где точные градиенты недоступны или слишком дороги для вычисления. Эффективность подхода заключается в его способности адаптироваться к изменяющимся условиям обучения, обеспечивая устойчивость и надежность в широком спектре задач машинного обучения.
Предстоящие исследования направлены на расширение сферы применения разработанных алгоритмов — NAMO и NAMO-D — на более сложные архитектуры нейронных сетей и масштабные наборы данных. Особое внимание будет уделено изучению их эффективности в задачах, связанных с обработкой изображений высокого разрешения и анализом больших объемов текстовой информации. Помимо практической реализации, планируется углубленное теоретическое исследование, направленное на разработку расширений, способных эффективно решать задачи невыпуклой оптимизации, что позволит значительно улучшить сходимость и обобщающую способность моделей машинного обучения в реальных условиях. Исследователи также намерены изучить возможности адаптации алгоритмов для работы в условиях ограниченных вычислительных ресурсов и при наличии шумов в данных, что расширит область их применения в различных областях науки и техники.
Представленная работа демонстрирует, что оптимизация сложных систем требует не просто увеличения вычислительной мощности, но и глубокого понимания внутренней структуры и взаимосвязей. Алгоритмы NAMO и NAMO-D, предложенные в статье, наглядно показывают, как адаптивный контроль шума и ортогонализованный импульс могут значительно улучшить сходимость при обучении больших языковых моделей. Как отмечал Джон фон Нейманн: «В науке не бывает абсолютно точных ответов, только лучшие приближения». Этот принцип особенно актуален в контексте стохастической оптимизации, где алгоритмы стремятся к наилучшему решению, учитывая неизбежный шум и неопределенность данных. Устойчивость и эффективность этих алгоритмов напрямую зависят от четкого определения границ и структуры, что подтверждает тезис о том, что структура определяет поведение системы.
Куда же дальше?
Представленные алгоритмы, NAMO и NAMO-D, демонстрируют улучшение сходимости в задаче обучения больших языковых моделей. Однако, если система кажется сложной, она, вероятно, хрупка. Успех в оптимизации часто сводится к умению скрыть сложность, а не устранить её. Вопрос не в том, чтобы найти «лучший» алгоритм, а в том, чтобы понять, какие компромиссы неизбежны. Архитектура — это искусство выбора того, чем пожертвовать.
Очевидным направлением дальнейших исследований представляется адаптация этих методов к задачам, выходящим за рамки обучения языковых моделей. Устойчивость к шуму и адаптивность шага обучения могут быть полезны в задачах обучения с подкреплением или в оптимизации нейронных сетей для компьютерного зрения. Однако, следует помнить, что универсального решения не существует — каждый класс задач требует индивидуального подхода.
В конечном счете, истинный прогресс в области оптимизации потребует не только разработки новых алгоритмов, но и углубленного понимания теоретических основ сходимости. Необходимо исследовать, как свойства пространства параметров влияют на эффективность различных методов оптимизации, и как можно использовать эти знания для создания более надежных и эффективных алгоритмов. Иначе говоря, необходимо стремиться к элегантности и простоте, помня, что хорошая система — это живой организм, а не просто набор правил.
Оригинал статьи: https://arxiv.org/pdf/2602.17080.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- ЕвроТранс акции прогноз. Цена EUTR
- Серебро прогноз
- РУСАЛ акции прогноз. Цена RUAL
- Российский рынок: Нефть, дивиденды и геополитика. Что ждет инвесторов? (23.03.2026 18:32)
- Хэдхантер акции прогноз. Цена HEAD
- Прогноз нефти
- АЛРОСА акции прогноз. Цена ALRS
- Как два ETF играют в одни ворота, но с разными мячами
- Palantir: К удивлению в 2026-м?
2026-02-22 22:34