Автор: Денис Аветисян
Исследователи предлагают метод постепенной тонкой настройки, позволяющий эффективно адаптировать предварительно обученные генеративные модели к новым данным без потери качества.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал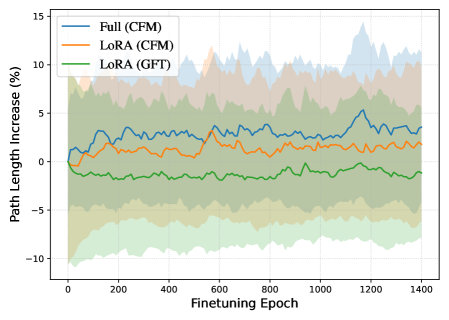
В статье представлена схема Gradual Fine-Tuning (GFT) для нелинейного обновления параметров и повышения эффективности обучения генеративных моделей на основе потокового соответствия.
Несмотря на успехи генеративных моделей, их адаптация к новым распределениям данных часто сопряжена с потерей эффективности и качества генерации. В работе ‘Gradual Fine-Tuning for Flow Matching Models’ предложен принципиально новый подход к тонкой настройке моделей потокового сопоставления, основанный на постепенном изменении целевой функции. Предложенный метод, Gradual Fine-Tuning (GFT), обеспечивает сходимость и позволяет использовать оптимальные транспортные сопряжения для адаптации модели, сохраняя при этом ее генеративные способности. Способствует ли GFT созданию более масштабируемых и эффективных генеративных моделей, способных адаптироваться к постоянно меняющимся данным?
Фундамент адаптации: от предварительного обучения к точной настройке
Современные большие языковые модели (LLM) опираются на мощь предварительно обученных моделей PretrainedModel, однако для успешной адаптации к новым задачам необходима тщательная донастройка, или FineTuning. Предварительное обучение позволяет модели усвоить общие закономерности языка, но для конкретных приложений, таких как анализ тональности, машинный перевод или ответы на вопросы, требуется дальнейшая специализация. Процесс донастройки заключается в обучении модели на небольшом, специализированном наборе данных, что позволяет ей адаптировать свои знания и навыки к конкретной задаче. Эффективность донастройки напрямую влияет на производительность модели в целевом приложении, поэтому выбор подходящей стратегии и параметров обучения имеет решающее значение.
Традиционный подход к тонкой настройке больших языковых моделей, известный как полная настройка (FullFineTuning), предполагает обновление всех параметров модели. Хотя этот метод может обеспечить высокую точность на целевой задаче, он сопряжен с существенными вычислительными затратами, особенно для моделей с миллиардами параметров. Поскольку каждое обновление требует пересчета и хранения огромного количества весов, процесс становится требовательным к ресурсам и времени. Более того, полная настройка подвержена переобучению, когда модель начинает запоминать обучающие данные вместо того, чтобы обобщать знания для новых, невиданных ранее примеров. Это особенно актуально при ограниченном объеме обучающих данных, когда модель может просто «запомнить» обучающий набор, теряя способность к эффективной работе с реальными данными.
Для эффективной адаптации больших языковых моделей (LLM) к новым задачам, методы, ориентированные на оптимизацию числа параметров, приобретают первостепенное значение. Полная перенастройка всех параметров модели, хоть и возможна, требует значительных вычислительных ресурсов и может приводить к переобучению. В этом контексте, LoRA (Low-Rank Adaptation) представляет собой элегантное решение, позволяющее адаптировать LLM, замораживая исходные веса и обучая лишь небольшое количество дополнительных, низкоранговых матриц. Такой подход существенно снижает вычислительную нагрузку и потребность в памяти, сохраняя при этом высокую производительность и обобщающую способность модели. LoRA позволяет быстро и эффективно настраивать LLM для конкретных задач, делая их более доступными и практичными для широкого круга приложений.
Поток адаптации: новый взгляд на обучение моделей
Метод FlowMatching представляет собой альтернативный подход к традиционной тонкой настройке (fine-tuning) в генеративном моделировании. Вместо прямого изменения весов модели, FlowMatching фокусируется на обучении непрерывного VectorField — векторного поля, которое определяет направление и величину изменений в пространстве параметров. Это векторное поле отображает распределение вероятностей из предобученного состояния в целевое, позволяя модели адаптироваться к новым данным без значительного изменения исходных весов. Обучение VectorField позволяет моделировать динамику адаптации как процесс непрерывной деформации пространства вероятностей, что обеспечивает более стабильное и эффективное обучение, особенно в задачах, где требуется быстрая адаптация к новым данным или условиям.
Метод Flow Matching основывается на обучении переносу вероятностной массы между распределениями, что позволяет моделировать динамику процесса адаптации. Вместо непосредственного изменения параметров модели, Flow Matching учится векторному полю \mathbf{v}(x,t) , которое непрерывно преобразует начальное распределение данных p(x) в целевое распределение q(x) . Этот процесс можно представить как решение дифференциального уравнения, где векторное поле определяет скорость и направление перемещения вероятностной массы. Обучение происходит путем минимизации расхождения между предсказанным и целевым потоками вероятности, что позволяет эффективно адаптировать модель к новым данным или задачам без необходимости прямой оптимизации параметров.
Обучение модели непрерывному потоку позволяет плавно осуществить переход от предварительно обученного состояния к желаемому целевому распределению. Этот процесс основан на моделировании динамики адаптации, где VectorField описывает векторное поле, направляющее перемещение вероятностной массы. Вместо дискретных шагов, характерных для тонкой настройки, Flow Matching обеспечивает постепенное преобразование, минимизируя разрыв между исходным и целевым состояниями модели. Такой подход позволяет избежать резких изменений в параметрах и обеспечивает более стабильный и контролируемый процесс адаптации к новым данным или задачам.
Условные потоки и постепенная адаптация: тонкости настройки
Метод ConditionalFlowMatching расширяет возможности FlowMatching за счет введения механизма обуславливания на основе пар SourceTargetCoupling. Это позволяет адаптировать модель к конкретным задачам, используя информацию о связи между исходными и целевыми данными. В отличие от стандартного FlowMatching, ConditionalFlowMatching позволяет учитывать специфические особенности целевой задачи при обучении, что повышает эффективность генерации данных, соответствующих этим задачам. Обуславливание осуществляется путем включения SourceTargetCoupling в процесс обучения, что позволяет модели учитывать взаимосвязь между исходным и целевым распределениями данных.
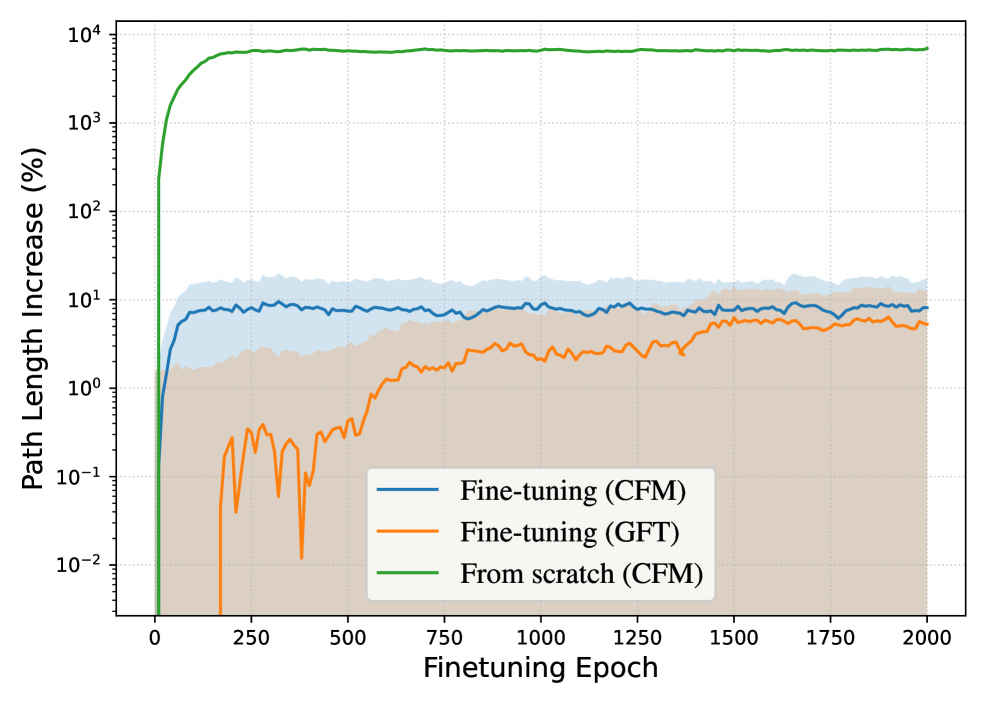
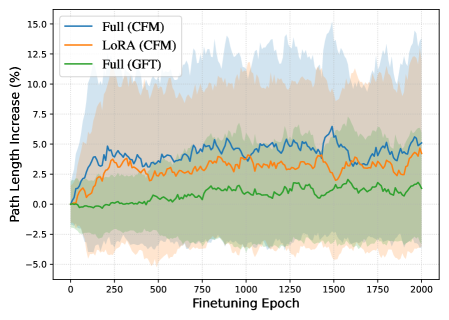
Метод `GradualFineTuning` совершенствует процесс адаптации, используя параметр TemperatureParameter для плавного интерполирования между предобученными и целевыми динамиками. Этот параметр позволяет регулировать степень влияния предобученных знаний на процесс генерации, обеспечивая постепенный переход к целевой задаче. В ходе обучения, значение TemperatureParameter изменяется, что позволяет модели сохранять общие знания, полученные в процессе предобучения, и одновременно адаптироваться к специфике целевого распределения данных. Такой подход способствует более стабильному и эффективному обучению, особенно в условиях ограниченного количества данных для целевой задачи.
Эксперименты на наборах данных Camelyon17, RxRx1 и FMoW показали, что плавная интерполяция между предобученными и целевыми динамиками, реализованная посредством TemperatureParameter, обеспечивает сопоставимые или улучшенные результаты, оцениваемые метрикой FID. При этом наблюдается снижение средней длины траекторий (Average Path Length), что свидетельствует о повышении эффективности процесса генерации и, как следствие, о более быстрой сходимости к желаемому результату.
Обучение с подкреплением и сопряжённое соответствие: новый горизонт адаптации
Метод AdjointMatching представляет собой инновационный подход к тонкой настройке моделей, который формулирует процесс обучения как задачу стохастического оптимального управления. В основе этого метода лежит концепция функции вознаграждения (RewardFunction), которая определяет желаемое поведение модели и служит ориентиром в процессе адаптации. Вместо традиционных методов градиентного спуска, AdjointMatching использует принципы оптимального управления для поиска параметров модели, максимизирующих накопленное вознаграждение. Это позволяет модели не просто имитировать обучающие данные, но и активно стремиться к достижению поставленной цели, определяемой функцией вознаграждения, что открывает новые возможности для управления и оптимизации поведения моделей в различных задачах.
Данный подход позволяет модели обучаться на основе обратной связи, оптимизируя свое поведение для достижения желаемой цели. Вместо традиционного обучения с учителем, где модель пассивно подстраивается под предопределенные метки, здесь используется механизм, имитирующий процесс обучения с подкреплением. Модель активно исследует различные стратегии, получая “награду” за действия, приближающие её к заданной цели, и корректируя свое поведение на основе этой награды. Такой процесс позволяет модели не просто воспроизводить заданные шаблоны, но и адаптироваться к новым ситуациям, находить оптимальные решения и демонстрировать более гибкое и интеллектуальное поведение. RewardFunction играет ключевую роль в этом процессе, определяя, какие действия считаются полезными, а какие — нет, и направляя процесс обучения в нужном направлении.
Продемонстрированная стабильная сходимость метода, характеризующаяся низкой мгновенной дисперсией и выраженной отрицательной корреляцией между метрикой FID и количеством эпох обучения, ярко свидетельствует об его эффективности. Такая устойчивость указывает на то, что модель последовательно улучшает качество генерируемых изображений в процессе адаптации, минимизируя расхождения с целевым распределением данных. Низкая дисперсия означает предсказуемость процесса обучения и снижение риска неконтролируемых отклонений, а сильная отрицательная корреляция между FID и эпохами подтверждает, что с увеличением времени обучения качество генерируемых образцов стабильно возрастает, что делает данный подход особенно привлекательным для задач генеративного моделирования.

Исследование демонстрирует, что адаптация предобученных генеративных моделей к новым данным — процесс, требующий тонкого баланса между сохранением качества генерации и эффективностью обучения. Предложенный подход, Gradual Fine-Tuning (GFT), акцентирует внимание на постепенном обновлении параметров, что позволяет избежать резких изменений в модели и сохранить её способность к генерации разнообразных и реалистичных данных. Как однажды заметил Алан Тьюринг: «Я думаю, что ничто не может быть более захватывающим, чем поиск истины». Это высказывание отражает суть данной работы — стремление к более эффективному и принципиальному подходу к адаптации моделей, что в конечном итоге способствует более качественной генерации данных и расширению возможностей применения генеративных моделей.
Куда же дальше?
Предложенный подход к постепенной настройке моделей потокового соответствия — не столько решение, сколько признание неизбежности энтропии. Любая система, даже та, что изящно переносит распределения данных, подвержена старению. Версионирование, как форма памяти, позволяет отследить деградацию, но не предотвращает её. Работа демонстрирует возможность смягчить этот процесс, однако вопрос о долговечности адаптации остается открытым. Нелинейные обновления параметров — это не панацея, а лишь способ задержать неизбежное.
Очевидным направлением дальнейших исследований представляется разработка метрик, способных оценивать не только качество генерации, но и “здоровье” модели во времени. Необходимо понять, какие признаки указывают на приближающуюся необходимость рефакторинга, как предсказать моменты, когда накопленные изменения в данных потребуют более радикальной перестройки. Стрела времени всегда указывает на необходимость рефакторинга, но умение предвидеть этот момент — признак зрелости подхода.
В конечном итоге, успех в этой области зависит не от создания идеальной модели, а от умения признать её конечность. Задача состоит не в том, чтобы остановить энтропию, а в том, чтобы научиться с ней жить, извлекая максимум пользы из каждого момента существования системы.
Оригинал статьи: https://arxiv.org/pdf/2601.22495.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Рубль, ставка ЦБ и геополитика: Что ждет российский рынок в ближайшее время
- Стоит ли покупать фунты за йены сейчас или подождать?
- Российский рынок: Ожидание ставки, стабилизация рубля и рост прибылей компаний (20.03.2026 02:32)
- Крипто-шторм: Взлом Resolv, увольнения и налоговые паузы – что ждет рынок? (22.03.2026 15:15)
- Аэрофлот акции прогноз. Цена AFLT
- Аналитический обзор рынка (15.09.2025 02:32)
- Аналитический обзор рынка (08.10.2025 12:32)
- Нейросети, предсказывающие скачки цен: новый подход к высокочастотной торговле
- Рынок в ожидании ставки: падение прибыли гигантов и переток инвесторов (20.03.2026 11:32)
- Стоит ли покупать доллары за бразильские реалы сейчас или подождать?
2026-02-03 03:50