Автор: Денис Аветисян
Новый подход NeuroPareto позволяет эффективно находить наилучшие варианты в задачах с множеством критериев и огромным пространством параметров.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал
Предлагается фреймворк, сочетающий откалиброванное предсказание неопределенности, глубокое суррогатное моделирование и обучение на основе истории для повышения эффективности многоцелевой оптимизации.
Поиск оптимальных компромиссов в многомерных пространствах параметров при ограниченных вычислительных ресурсах представляет собой сложную задачу современной многоцелевой оптимизации. В данной работе представлена архитектура ‘NeuroPareto: Calibrated Acquisition for Costly Many-Goal Search in Vast Parameter Spaces’, объединяющая откалиброванную оценку неопределенности, выразительные глубокие суррогатные модели и обучение на основе истории для эффективного поиска в сложных целевых ландшафтах. Предложенный подход позволяет существенно повысить качество получаемых решений и снизить стоимость вычислений за счет учета как предсказуемой, так и непредсказуемой неопределенности. Возможно ли дальнейшее расширение принципов калиброванной оценки неопределенности для решения еще более сложных задач оптимизации в реальных приложениях?
Вызов Многокритериальной Оптимизации: Между Теоретической Элегантностью и Практической Реальностью
Многие практические задачи, возникающие в различных областях — от проектирования инженерных систем и управления финансами до разработки лекарств и планирования логистики — требуют одновременной оптимизации нескольких, зачастую противоречивых целей. Например, при разработке автомобиля необходимо одновременно максимизировать безопасность, минимизировать расход топлива и снизить стоимость производства. Подобные задачи, известные как многокритериальные или многоцелевые, отличаются от традиционных задач оптимизации, где существует лишь одна целевая функция. Вместо поиска единственного оптимального решения, необходимо выявить целый набор компромиссных вариантов, каждый из которых представляет собой баланс между различными целями, позволяя выбирать наиболее подходящий вариант в зависимости от конкретных приоритетов и ограничений. Сложность заключается в том, что улучшение по одной цели часто приводит к ухудшению по другой, что требует разработки специальных методов и алгоритмов для эффективного поиска оптимальных компромиссов.
Традиционные методы оптимизации сталкиваются с серьезными трудностями при решении задач в многомерных пространствах, что известно как “проклятие размерности”. Суть проблемы заключается в том, что с увеличением числа переменных, необходимых для описания задачи, объем пространства поиска растет экспоненциально. Это приводит к тому, что алгоритмы, эффективно работающие в низкоразмерных пространствах, становятся непрактичными из-за огромных вычислительных затрат и необходимости в чрезмерно больших объемах данных для адекватного исследования. Даже простое равномерное покрытие пространства становится невозможным, а локальные методы оптимизации легко застревают в неоптимальных точках, не находя глобального решения. В результате, эффективность традиционных подходов резко снижается, требуя разработки новых стратегий, способных эффективно преодолевать эти ограничения.
В задачах многокритериальной оптимизации, особенно в пространствах высокой размерности, достижение баланса между исследованием (exploration) и использованием (exploitation) представляется сложной задачей. Эффективное исследование необходимо для обнаружения перспективных областей решений, в то время как использование позволяет углубить поиск в уже найденных областях. Однако, с ростом числа оптимизируемых параметров, объём поискового пространства экспоненциально увеличивается, что значительно затрудняет полное и эффективное исследование. В результате, алгоритмы часто застревают в локальных оптимумах, не находя глобально оптимальных решений. Увеличение вычислительных затрат, связанных с оценкой функции при большом числе параметров, также усугубляет проблему, делая поиск оптимальных решений практически невозможным в разумные сроки. Таким образом, разработка методов, способных эффективно преодолевать «проклятие размерности» и обеспечивать разумный компромисс между исследованием и использованием, является ключевой задачей современной оптимизации.
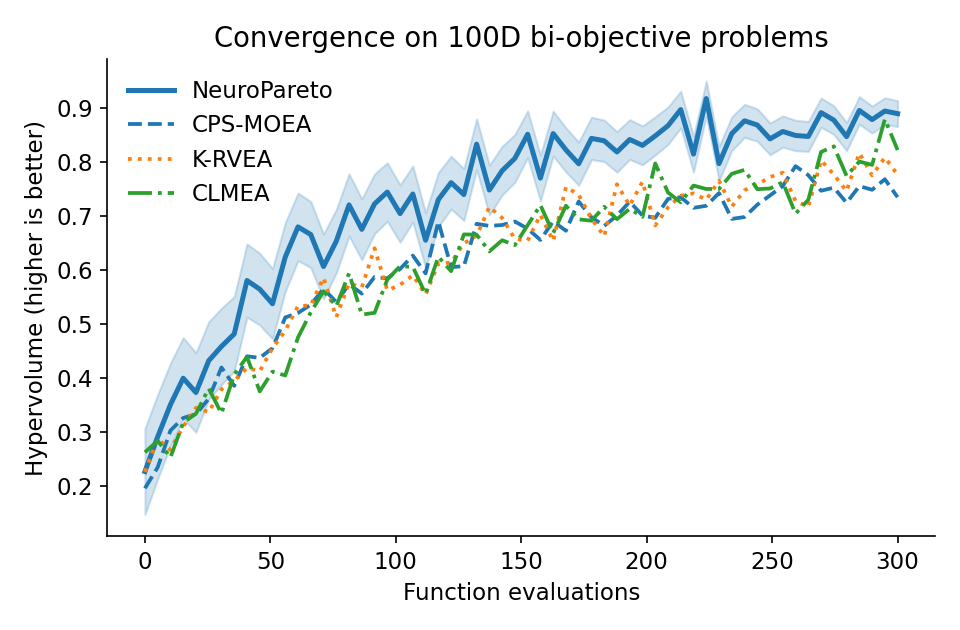
NeuroPareto: Интеллектуальная Оптимизация, Объединяющая Теорию и Практику
NeuroPareto представляет собой комплексную структуру, объединяющую откалиброванное предсказание ранга, декомпозицию глубокой неопределенности и обучение на основе истории приобретения данных. Данный подход интегрирует эти три компонента для эффективной оптимизации, позволяя моделировать сложные целевые функции и находить решения, близкие к паретовскому фронту. Откалиброванное предсказание ранга позволяет оценить перспективность кандидатов на основе их положения относительно других решений, декомпозиция глубокой неопределенности помогает оценить надежность прогнозов, а обучение на основе истории приобретения данных динамически адаптирует стратегию поиска, максимизируя эффективность процесса оптимизации и превосходя базовые методы.
В основе NeuroPareto лежит модель суррогата на базе глубокого гауссовского процесса (Deep Gaussian Process Surrogate), предназначенная для эффективного моделирования целевых функций. В отличие от традиционных суррогатных моделей, данная модель способна оценивать не только предсказанное значение целевой функции для заданного решения, но и связанную с этим предсказанием неопределенность. Оценка неопределенности, выражаемая в виде дисперсии, критически важна для принятия решений о дальнейшей оптимизации, позволяя алгоритму эффективно исследовать пространство решений и избегать локальных оптимумов. Использование глубоких нейронных сетей позволяет модели масштабироваться для работы с высокоразмерными пространствами и сложными целевыми функциями, сохраняя при этом преимущества гауссовских процессов в плане предоставления количественной оценки неопределенности. \sigma^2 — дисперсия является ключевым параметром, определяющим стратегию исследования.
Байесовский классификатор в NeuroPareto предсказывает ранг не доминируемости (non-domination rank) для каждого кандидатного решения. Этот ранг определяет позицию решения относительно других в пространстве целей, где более низкий ранг указывает на более предпочтительное решение, ближе к оптимальному множеству Парето. Классификатор использует вероятностную модель для оценки вероятности того, что данное решение доминирует над другими, позволяя системе эффективно отфильтровывать неперспективные варианты и направлять поиск в область Парето-фронта. Точность предсказания ранга напрямую влияет на скорость сходимости алгоритма к оптимальному множеству решений, минимизируя необходимость оценки неэффективных кандидатов.
Механизм обучения на основе истории (History-Aware Acquisition Learner) динамически корректирует баланс между исследованием (exploration) и использованием (exploitation) в процессе оптимизации. Он анализирует историю предыдущих итераций, оценивая эффективность различных стратегий поиска и адаптируя функцию приобретения (acquisition function) для повышения вероятности обнаружения оптимальных решений. В ходе тестирования данный подход демонстрирует стабильное превосходство над базовыми методами, включая случайный выбор и верхнюю доверительную границу (Upper Confidence Bound), за счет более эффективного использования информации о ранее оцененных кандидатах и адаптации к особенностям целевой функции.
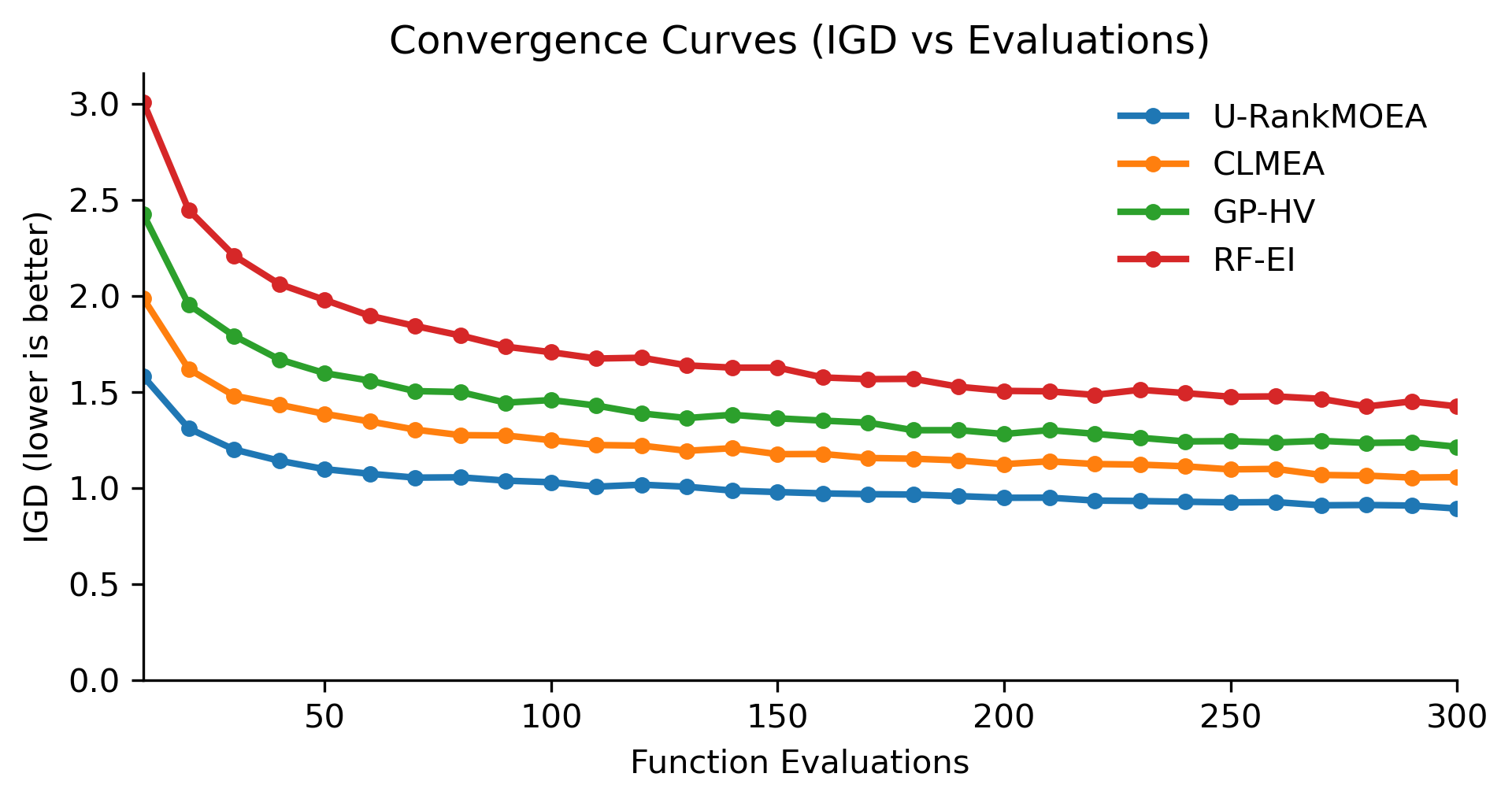
Декомпозиция и Количественная Оценка Неопределенности: От Теории к Практической Реализации
Глубокий Гауссовский Суррогат (Deep Gaussian Process Surrogate) использует метод Монте-Карло Дропаута (Monte Carlo Dropout) для оценки как алеаторной (случайной), так и эпистемической (когнитивной) неопределенности. Применение дропаута во время предсказания позволяет получить несколько реализаций выходных данных, дисперсия которых служит мерой неопределенности. Алеаторная неопределенность отражает присущий шум в целевой функции и может быть смоделирована дисперсией выходных данных. Эпистемическая неопределенность, в свою очередь, представляет собой недостаток знаний о истинной функции и оценивается дисперсией предсказаний, полученных из разных дропаут-реализаций. Таким образом, Монте-Карло Дропаут обеспечивает эффективный способ количественной оценки обоих типов неопределенности без необходимости явного моделирования распределения вероятностей.
Алеаторная неопределенность, или шум в целевой функции, отражает присущие данные случайные вариации, которые невозможно уменьшить даже при увеличении объема данных. В отличие от нее, эпистемическая неопределенность обусловлена недостатком информации о самой функции, то есть модель не уверена в своей предсказательной способности из-за ограниченного обучающего набора. Таким образом, алеаторная неопределенность связана с данными, а эпистемическая — с моделью и ее знаниями о функции f(x). Оценка обоих типов неопределенности критически важна для надежных предсказаний и принятия обоснованных решений, особенно в задачах, где цена ошибки высока.
Для масштабирования Deep Gaussian Process Surrogate к задачам высокой размерности используются методы разреженного вариационного вывода (Sparse Variational Inference) и случайных преобразований признаков (Randomized Feature Transforms). Разреженный вариационный вывод позволяет аппроксимировать апостериорное распределение, используя лишь подмножество наиболее информативных признаков, что существенно снижает вычислительную сложность. Случайные преобразования признаков, такие как случайные признаки Фурье, применяются для аппроксимации ядра k(x, x') в бесконечномерном пространстве, сводя задачу к работе с конечномерными признаками и, таким образом, уменьшая вычислительные затраты и требования к памяти. Комбинация этих методов позволяет эффективно обрабатывать данные высокой размерности, сохраняя при этом точность модели.
Для снижения вычислительных затрат в Deep Gaussian Process Surrogate используется аппроксимация ядра посредством Random Fourier Features. Данный метод заключается в замене вычисления ядра k(x, x') на признаковое отображение \phi(x), где \phi(x) = \frac{1}{\sqrt{d}} \sum_{j=1}^{d} \cos(\omega_j x + \phi_j). Здесь \omega_j и \phi_j — случайные частоты и фазы, а d — размерность признакового пространства. Использование Random Fourier Features позволяет заменить операции, требующие O(n^2) времени (где n — количество данных), на операции с линейной сложностью O(nd), существенно ускоряя обучение и предсказание модели, особенно при работе с большими объемами данных.
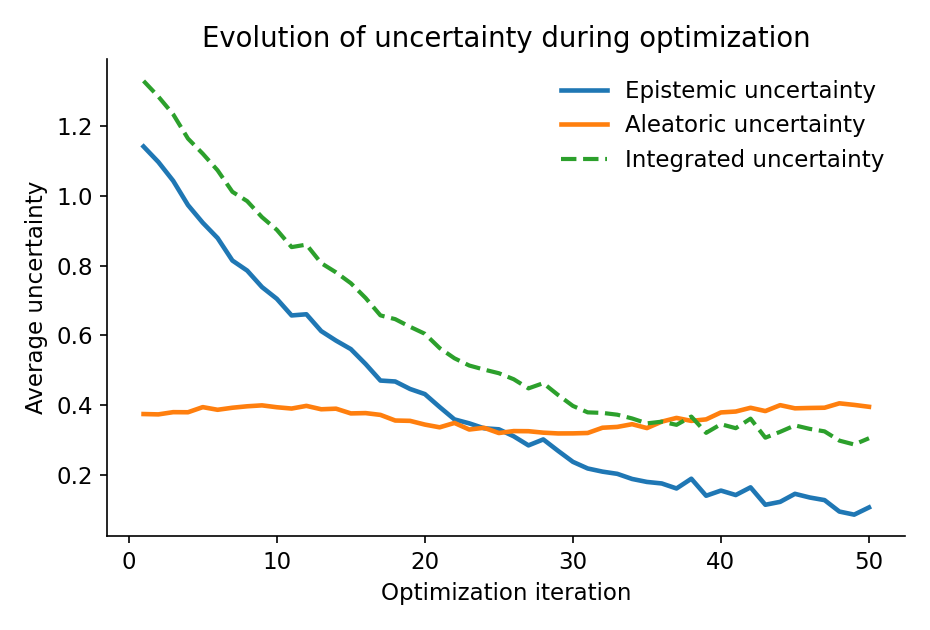
Повышение Эффективности и Разнообразия с Помощью Продвинутых Техник: От Теории к Практическому Применению
Метод NeuroPareto использует двухэтапную оценку кандидатов, что позволяет значительно снизить вычислительные затраты. Вместо того чтобы сразу оценивать все потенциальные решения с использованием дорогостоящих вычислений, система сначала проводит быструю, предварительную оценку. Только те кандидаты, которые успешно проходят этот первый этап отбора, подвергаются более сложной и ресурсоемкой оценке. Такой подход позволяет отсеять неперспективные решения на ранней стадии, существенно ускоряя процесс оптимизации и делая его более эффективным, особенно при работе со сложными задачами, требующими больших вычислительных мощностей.
Для обеспечения разнообразия полученных Парето-оптимальных решений используется метрика дистанции скопления (Crowding Distance). Данный показатель оценивает плотность решений вокруг каждой точки в пространстве целей, позволяя алгоритму отдавать предпочтение решениям, находящимся в менее населенных областях. Это способствует формированию хорошо распределенного архива, представляющего широкий спектр компромиссов между различными целями. В результате, исследователи и разработчики получают не просто одно оптимальное решение, а целый набор альтернатив, позволяющих выбрать наиболее подходящий вариант в соответствии с конкретными требованиями и приоритетами. Использование дистанции скопления значительно повышает практическую ценность многоцелевой оптимизации, обеспечивая более гибкие и адаптивные решения.
В процессе оптимизации, применение статистики скользящего окна предоставляет ценные сведения о динамике поиска, позволяя алгоритму адаптироваться к изменяющимся условиям. Этот подход заключается в непрерывном анализе показателей эффективности на ограниченном временном интервале, что позволяет выявлять тренды и закономерности, незаметные при статическом анализе. Например, отслеживание среднего значения и дисперсии целевой функции в скользящем окне позволяет оценить скорость сходимости и стабильность процесса оптимизации. В случае обнаружения замедления или колебаний, алгоритм может динамически корректировать свои параметры, такие как размер шага или стратегия выбора кандидатов, для ускорения поиска и повышения надежности. Такой адаптивный механизм обучения способствует более эффективному исследованию пространства решений и позволяет находить оптимальные решения в сложных и изменчивых средах.
Внедрение функции потерь Хабера значительно повысило устойчивость алгоритма History-Aware Acquisition Learner, что привело к заметному ускорению процесса оптимизации. Исследования показали, что данная функция обеспечивает более надежную работу алгоритма в различных условиях, минимизируя влияние выбросов и обеспечивая стабильное схождение к оптимальному решению. В результате, скорость работы алгоритма History-Aware Acquisition Learner превзошла показатель самого быстрого не-U метода (K-RVEA) на 1.31-1.35, что демонстрирует значительный прогресс в эффективности многоцелевой оптимизации и открывает новые возможности для решения сложных задач в различных областях науки и техники.
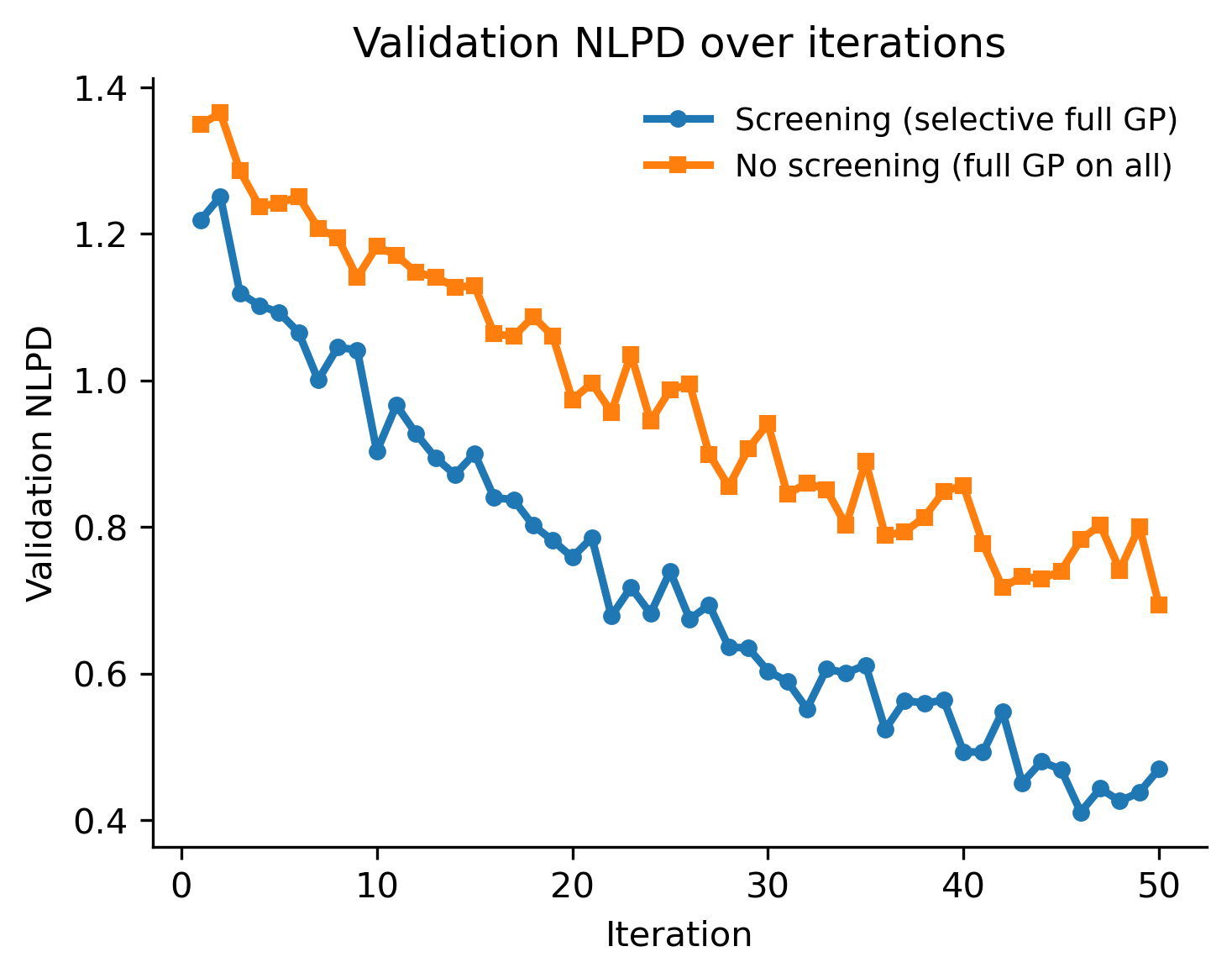
В этой работе, как и во многих других, элегантная теория суррогатного моделирования сталкивается с суровой реальностью многоцелевой оптимизации в пространствах высоких размерностей. NeuroPareto пытается приручить эту сложность, используя калибровку неопределенности и историю обучения функции приобретения. Но, как известно, каждая «революционная» технология завтра станет техдолгом. Попытки оптимизировать сразу несколько целей неизбежно приводят к экспоненциальному росту вычислительных затрат. Как точно заметил Алан Тьюринг: «Мы можем только делать то, что можем делать». И в данном случае, NeuroPareto — это очередная попытка отсрочить неизбежное, хоть и весьма изящная.
Что дальше?
Предложенный фреймворк NeuroPareto, безусловно, добавляет ещё один уровень сложности в и без того насыщенный инструментарий многокритериальной оптимизации. Калибровка неопределённости и использование глубоких суррогатных моделей — это, конечно, красиво. Но история учит, что каждая новая «инновация» неизбежно превращается в технический долг, требующий всё больше ресурсов для поддержания. Особенно учитывая, что «бесконечная масштабируемость» уже звучала как мантра в 2012-м, только под другим соусом.
Неизбежным вопросом остаётся устойчивость предложенного подхода к реальным, шумным данным. Если тесты показывают идеальную картину — это, скорее всего, говорит о том, что они ничего не проверяют. Следующим шагом, вероятно, станет разработка более надёжных метрик оценки, способных выявить скрытые недостатки и предсказать поведение системы в условиях, далёких от идеальных. И, конечно, интеграция с существующими промышленными стандартами, а не создание ещё одной проприетарной «экосистемы».
В конечном итоге, NeuroPareto — это ещё один шаг на пути к автоматизации процесса оптимизации. Но стоит помнить, что даже самая сложная модель — это лишь упрощение реальности. И рано или поздно, в продакшене всегда найдётся способ сломать даже самую элегантную теорию. Так что, возможно, стоит сосредоточиться на разработке более гибких и отказоустойчивых систем, а не на погоне за «идеальной» оптимизацией.
Оригинал статьи: https://arxiv.org/pdf/2602.03901.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Недвижимость и авиа: что ждет потребителей в России? Анализ рынка и новые маршруты (28.03.2026 19:32)
- АЛРОСА акции прогноз. Цена ALRS
- Супернус: Продажа Акций и Нервные Тики
- Будущее FET: прогноз цен на криптовалюту FET
- Будущее KAS: прогноз цен на криптовалюту KAS
- Управление рисками в условиях неопределенности: современные подходы
- СириусXM: Пыль дорог и звон монет
- Южнокорейский Крипто-Консолидация: Захват Доли и Риски для Инвесторов (03.04.2026 06:15)
- МТС акции прогноз. Цена MTSS
2026-02-05 18:23