Автор: Денис Аветисян
Новый подход к обучению агентов в сложных играх с долгосрочной перспективой позволяет им учитывать стратегический контекст и прогнозировать поведение оппонентов.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал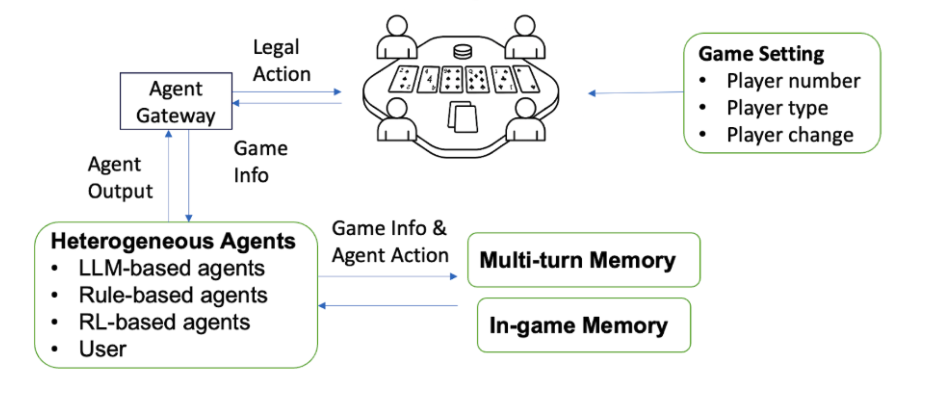
Предложена новая схема обучения, основанная на неявной стратегической оптимизации и прогнозировании будущих стратегических выгод в состязательных средах.
В задачах обучения с подкреплением в долгосрочных состязательных играх традиционные подходы, ориентированные на мгновенную награду, часто оказываются неэффективными из-за скрытых стратегических взаимосвязей. В данной работе, ‘Implicit Strategic Optimization: Rethinking Long-Horizon Decision-Making in Adversarial Poker Environments’, предложен новый фреймворк, неявно оптимизирующий стратегические последствия действий, посредством прогнозирования контекста и обновления политики в реальном времени. Предложенный метод, сочетающий стратегическую модель вознаграждения и алгоритм iso-grpo, демонстрирует сублинейную зависимость сожаления и сходимость к равновесию, при этом скорость обучения определяется точностью прогнозирования контекста. Сможет ли предложенный подход обеспечить устойчивое улучшение результатов в сложных состязательных средах и открыть новые возможности для разработки интеллектуальных агентов?
Глубина Стратегии: Вызов для Искусственного Интеллекта
Многие состязательные игры, такие как профессиональные сражения в Pokémon или покер Техасский Холдем без лимита, представляют собой задачи с горизонтом планирования, простирающимся далеко за пределы немедленных результатов. В этих играх не существует быстрых наград за каждое действие; успех определяется долгосрочными последствиями, которые могут проявиться лишь спустя много ходов. Игроку необходимо оценивать не только текущую ситуацию, но и вероятные действия оппонента, предвидя, как каждое решение повлияет на исход игры в будущем. Эта сложность делает такие игры особенно трудными для традиционных алгоритмов искусственного интеллекта, которые часто оптимизированы для получения немедленной выгоды, а не для стратегического планирования на длительный срок.
Традиционные алгоритмы искусственного интеллекта, предназначенные для игровых сценариев, часто сталкиваются с серьезными трудностями в ситуациях, требующих долгосрочного планирования. Так называемое “проклятие размерности” заключается в экспоненциальном росте вычислительной сложности по мере увеличения числа возможных состояний игры и глубины поиска. Это означает, что даже при умеренной сложности игры, перебор всех возможных вариантов становится практически невозможным. Кроме того, точно предсказать действия противника и их последствия на длительной временной перспективе — задача чрезвычайно сложная. Неопределенность и случайность, присущие многим играм, значительно усложняют прогнозирование, приводя к неточным оценкам и, как следствие, к неоптимальным решениям со стороны искусственного интеллекта. Таким образом, стандартные подходы к игровому ИИ зачастую не способны эффективно функционировать в сложных, долгосрочных сценариях, где важны стратегическое планирование и адаптация к изменяющимся обстоятельствам.
Для успешной навигации в сложных игровых ситуациях, характеризующихся долгосрочным планированием и неопределенностью, необходим агент, способный не только предвидеть стратегии противника, но и гибко адаптироваться к неожиданным поворотам событий. Такой агент должен уметь строить вероятностные модели поведения оппонента, учитывая различные уровни мастерства и потенциальные реакции на собственные действия. Важно, чтобы система не ограничивалась заранее запрограммированными шаблонами, а обладала способностью к обучению и корректировке стратегии в реальном времени, анализируя поступающую информацию и выявляя закономерности. Эффективная адаптация к непредсказуемым обстоятельствам требует от агента способности оценивать риски и возможности, а также быстро принимать решения в условиях ограниченной информации, что существенно повышает его шансы на достижение долгосрочного успеха.

LLM Агент: Понимание Контекста как Ключ к Победе
Предлагаемый нами фреймворк LLM Agent использует большие языковые модели (LLM) для представления и рассуждений о стратегических контекстах в сложных играх. В основе лежит идея кодирования игровых ситуаций в векторном пространстве, что позволяет LLM понимать взаимосвязи между различными элементами игры — позициями, ресурсами, действиями противника. Данный подход позволяет агенту не просто реагировать на текущую ситуацию, но и анализировать её с точки зрения долгосрочной стратегии, прогнозировать развитие событий и выбирать оптимальные действия, основанные на понимании контекста. LLM выступает в роли центрального планировщика, способного учитывать множество факторов и адаптировать свою тактику в зависимости от изменяющихся обстоятельств.
В основе предложенного фреймворка лежит алгоритм ISO-GRPO — оптимистическое правило обучения, обусловленное контекстом, использующее Group Relative Policy Optimization (GRPO). ISO-GRPO позволяет агенту эффективно исследовать и использовать пространство состояний игры, адаптируя политику в зависимости от текущего контекста. GRPO способствует более стабильному и быстрому обучению за счет относительной оптимизации политики по группам действий, что позволяет агенту избегать чрезмерной эксплуатации и поддерживать необходимое разнообразие в исследовании.
Агент использует Предсказание Контекста для прогнозирования будущих игровых ситуаций и адаптации своей стратегии в соответствии с ними. Этот процесс включает в себя анализ текущего состояния игры и использование модели языка для оценки вероятных будущих состояний. Основываясь на этих прогнозах, агент корректирует свою политику принятия решений, чтобы максимизировать ожидаемую награду. Предсказание контекста позволяет агенту не только реагировать на текущую ситуацию, но и проактивно планировать свои действия, повышая эффективность и способность к принятию обоснованных решений в динамичной игровой среде. Это достигается за счет учета не только непосредственных последствий действий, но и долгосрочных перспектив, что критически важно для успешной игры в сложных стратегических задачах.
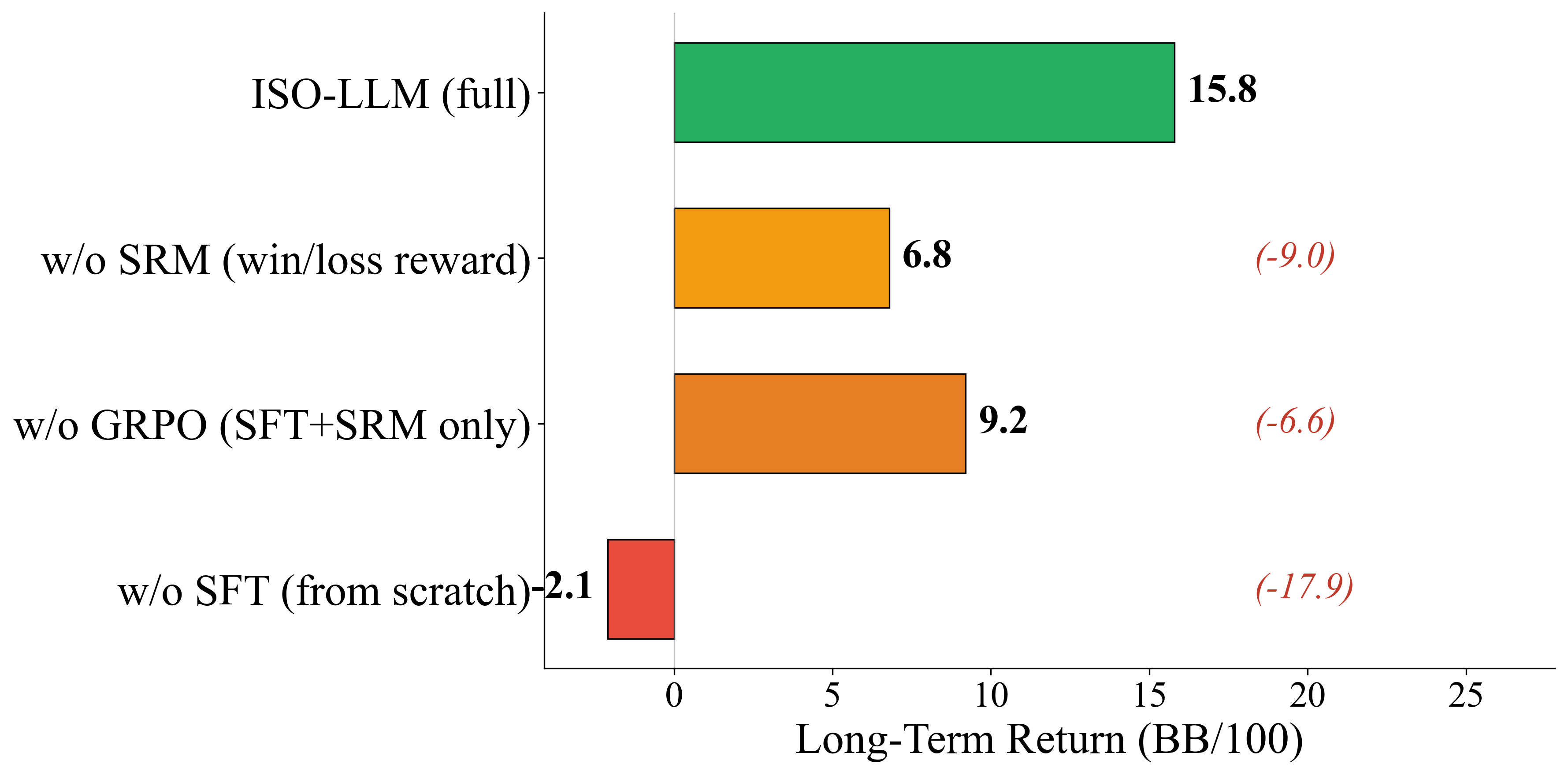
Минимизация Сожаления и Обеспечение Стабильности: Основа Долгосрочного Превосходства
Обучение агента направляется показателем Контекстуального Сожаления (Contextual Regret), разработанным специально для обучения с учетом предсказаний. В отличие от традиционных алгоритмов, которые оценивают сожаление на основе действий, данный показатель измеряет сожаление относительно точности предсказаний контекста игровой ситуации. Это означает, что агент стремится минимизировать расхождения между предсказанным распределением действий оппонентов и их фактическими действиями. Вычисление Контекстуального Сожаления основывается на вероятностях, присвоенных различным контекстам, и позволяет агенту адаптировать свою стратегию к изменяющейся динамике игры, основываясь на корректности его прогнозов о поведении оппонентов.
Оптимистическое обучение, в сочетании с алгоритмом ISO-GRPO (Incremental Single Opponent — Generalized Regret Potential Optimization), значительно повышает точность прогнозирования действий оппонентов в динамичной среде. ISO-GRPO позволяет агенту итеративно обновлять свою стратегию, фокусируясь на наиболее релевантных оппонентах и учитывая их текущие профили игры. Оптимистическое обучение, в свою очередь, стимулирует исследование альтернативных стратегий, предполагая, что оппоненты могут отклоняться от наблюдаемых моделей, что позволяет агенту быстрее адаптироваться к изменяющимся условиям и поддерживать конкурентоспособность. Такой подход обеспечивает проактивное реагирование на новые игровые ситуации, в отличие от реактивных стратегий, и позволяет агенту поддерживать оптимальную производительность даже при изменении поведения оппонентов.
Применение принципов динамики сожаления (Regret-Based Dynamics) и концепций грубого коррелированного равновесия (Coarse Correlated Equilibrium) обеспечивает сходимость агента к стабильным и устойчивым стратегиям в условиях игры в 6-макс No-Limit Texas Hold’em. В ходе обучения агент корректирует свою стратегию на основе накопленного сожаления о неиспользованных альтернативных действиях, что позволяет ему адаптироваться к изменяющимся игровым условиям и противодействовать эксплуатации. Достигнутый долгосрочный возврат составляет +15.8 BB/100, подтверждая эффективность данного подхода к построению игровых стратегий, основанных на минимизации сожалений и обеспечении устойчивости в сложных многопользовательских сценариях.
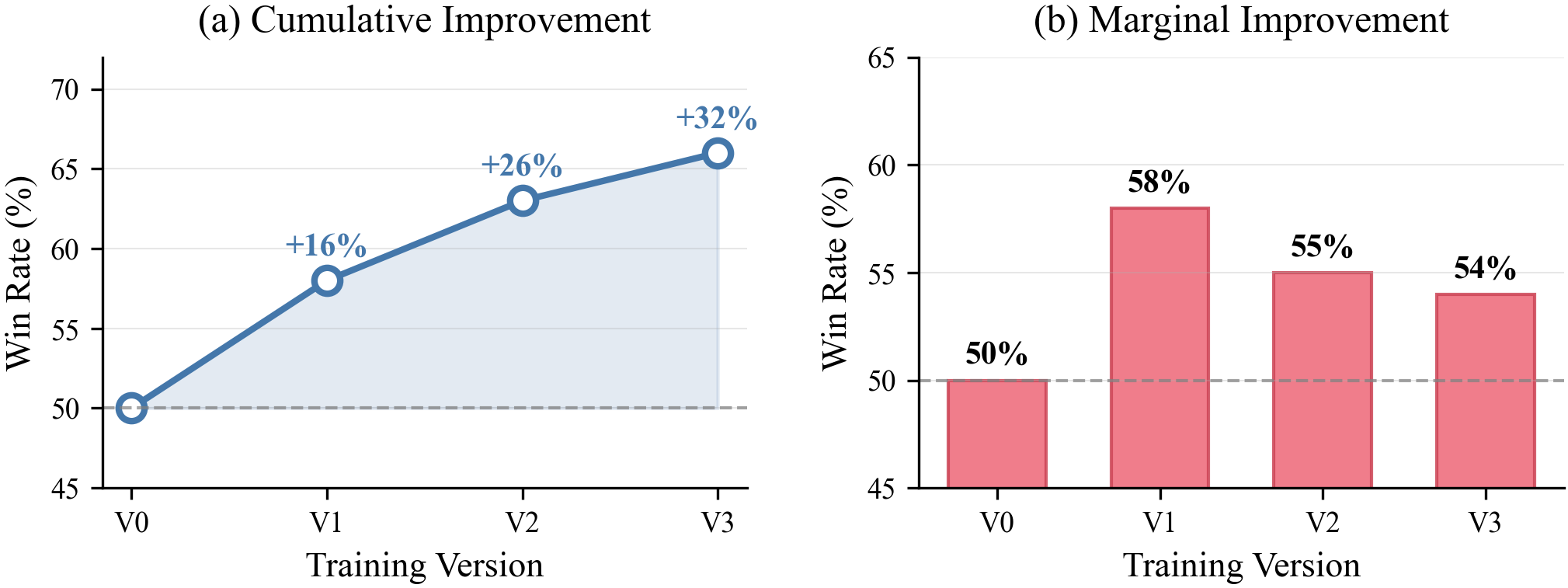
Учет Скрытых Динамик и Стратегической Сложности: Превосходство в Непредсказуемости
Подход, разработанный исследователями, успешно решает проблему скрытых стратегических внешних факторов — неочевидных элементов, оказывающих влияние на исход игры — посредством явного моделирования контекста и его воздействия на выплаты агентов. Вместо игнорирования этих неявных факторов, система активно учитывает их, интегрируя информацию об окружающей среде и действиях других игроков в процесс принятия решений. Это позволяет агенту не просто реагировать на текущую ситуацию, но и прогнозировать, как изменения в контексте могут повлиять на долгосрочные результаты, что существенно повышает его адаптивность и конкурентоспособность в сложных игровых сценариях. Моделирование контекста позволяет учитывать такие параметры, как психологическое состояние оппонентов, изменение правил игры или даже внешние события, что приводит к более реалистичной и эффективной стратегии.
Агент, учитывая изменение полезности во времени, способен более точно оценивать риски и выгоды, связанные с различными действиями. Вместо статической оценки, система анализирует, как ценность конкретного исхода может меняться в зависимости от текущей ситуации и прогнозируемого развития событий. Это позволяет не только оптимизировать краткосрочные решения, но и учитывать долгосрочные последствия, адаптируя стратегию к динамически изменяющимся условиям. В результате, агент способен принимать более взвешенные решения, избегая чрезмерного риска и максимизируя потенциальную выгоду, что особенно важно в сложных стратегических играх, где успех зависит от способности предвидеть и адаптироваться к действиям оппонентов.
Разработанный агент на основе больших языковых моделей демонстрирует превосходство над традиционными подходами искусственного интеллекта в сложных стратегических играх, таких как No-Limit Texas Hold’em и Competitive Pokémon. В ходе тестирования зафиксирован впечатляющий показатель побед в 68%, а в Competitive Pokémon агент достиг рейтинга Elo в 1750 пунктов. Особо примечательно, что агент демонстрирует стратегическую готовность к жертвам — с частотой 15.2% — что свидетельствует о способности к планированию на длительный горизонт и принятию решений, направленных на достижение долгосрочных целей, а не только на немедленную выгоду.
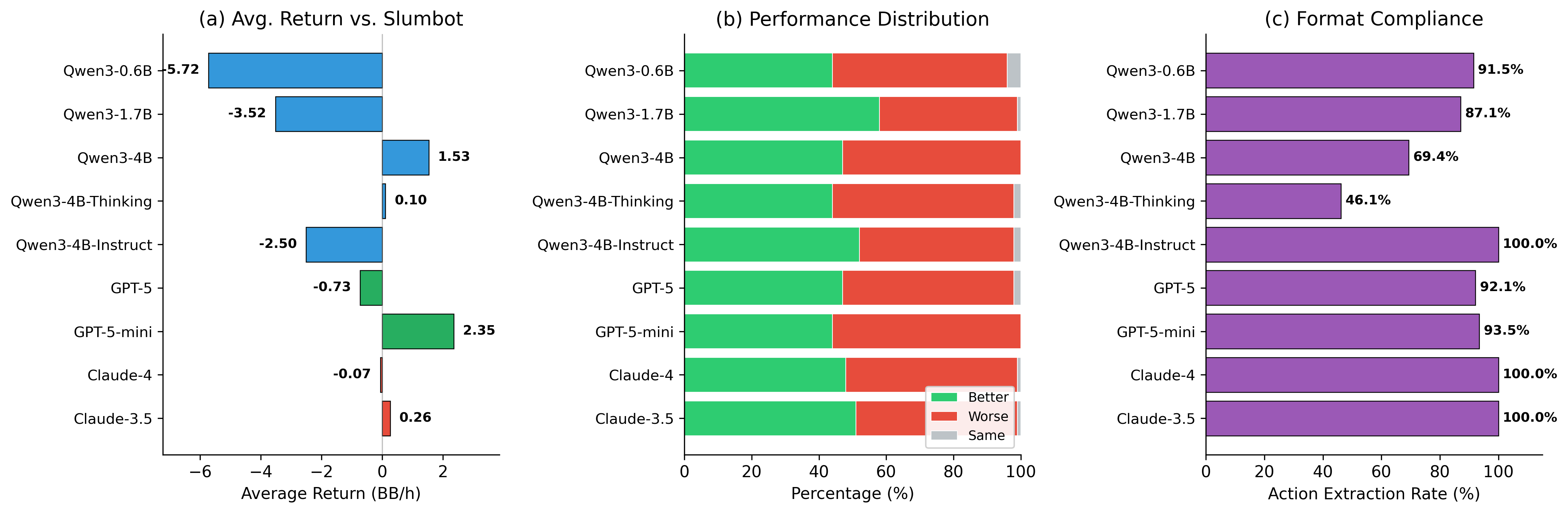
Исследование демонстрирует, что способность агента предсказывать будущие стратегические выгоды является ключевым фактором в долгосрочном принятии решений. Этот подход к обучению, явно моделирующий предвидение стратегической отдачи, позволяет агентам более эффективно адаптироваться к меняющейся обстановке и сходиться к равновесию. Как отмечал Эдсгер Дейкстра: «Программирование — это не столько о захвате мира, сколько о создании вселенной, в которой можно жить.» В данном контексте, создание этой “вселенной” — это построение модели предсказания, позволяющей агенту “жить” и преуспевать в сложной игре, где понимание стратегического контекста играет решающую роль. Этот метод открывает путь к разработке более интеллектуальных и адаптивных систем в долгосрочных состязательных средах.
Куда Ведет Игра?
Представленная работа, по сути, лишь намекает на глубину кроличьей норы. Явное моделирование предвидения стратегической выгоды — это, конечно, шаг вперед, но истинный вызов заключается не в оптимизации текущей стратегии, а в создании агентов, способных к самомодификации стратегии, основанной на прогнозировании не только действий оппонента, но и эволюции самой игры. Необходимо выйти за рамки поиска равновесия; нужно научиться его взламывать, переопределять правила прямо в процессе взаимодействия.
Ограничения текущего подхода очевидны: зависимость от точности прогнозов и вычислительная сложность моделирования долгосрочных последствий. Следующий этап — исследование методов приближения, возможно, с использованием иерархических моделей или обучения с подкреплением, ориентированного на мета-обучение. Истинный прогресс потребует отказа от идеи «оптимальной» стратегии в пользу адаптивной, способной к нелинейному обучению в условиях неопределенности.
В конечном счете, данная работа — это не столько решение проблемы долгосрочного планирования, сколько демонстрация того, что традиционные методы нуждаются в пересмотре. Необходимо признать, что “игра” — это не статичная задача, а динамичная система, и только понимание этой динамики позволит создать агентов, способных к истинному стратегическому превосходству. Попытка формализовать интуицию — всегда рискованное предприятие, но именно в этом риске и заключается суть научного поиска.
Оригинал статьи: https://arxiv.org/pdf/2602.08041.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Серебро прогноз
- Мечел акции прогноз. Цена MTLR
- Группа Аренадата акции прогноз. Цена DATA
- АЛРОСА акции прогноз. Цена ALRS
- Крипто-археология: Стратегии накопления в эпоху волатильности и хакерских угроз (06.04.2026 16:45)
- Российский рынок: между нефтью, рублем и геополитикой: обзор ключевых трендов и перспектив (04.04.2026 01:32)
- Будущее CRV: прогноз цен на криптовалюту CRV
- XLP против VDC: Более низкие комиссии или более широкое покрытие?
- Разделение акций: История одного триумфа и ожидания другого
2026-02-11 03:45