Автор: Денис Аветисян
Исследователи предлагают принципиально новый метод эффективного использования вычислительных ресурсов при работе с большими языковыми моделями, позволяющий значительно улучшить качество рассуждений.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал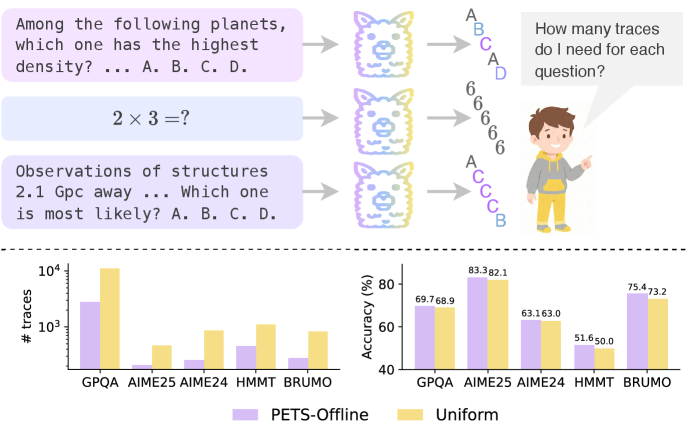
Предложенная схема PETS оптимизирует распределение вычислительного бюджета для достижения высокой самосогласованности и точности результатов при минимальных затратах.
Несмотря на эффективность методов масштабирования во время инференса для улучшения производительности моделей, оптимизация распределения ограниченных вычислительных ресурсов остается сложной задачей. В настоящей работе, озаглавленной ‘PETS: A Principled Framework Towards Optimal Trajectory Allocation for Efficient Test-Time Self-Consistency’, предложен принципиально новый подход к достижению эффективной самосогласованности при ограниченном бюджете, основанный на оптимизационной формулировке и введении метрики — коэффициента самосогласованности. Данный подход позволяет значительно сократить необходимое количество сэмплов, сохраняя при этом высокую точность, и находит аналоги в задачах краудсорсинга. Возможно ли дальнейшее расширение теоретической базы и адаптация предложенного метода для еще более сложных сценариев и моделей?
Неустойчивость Рассуждений: Вызов для Больших Языковых Моделей
Несмотря на впечатляющие возможности, большие языковые модели (БЯМ) часто демонстрируют непостоянство и ненадежность в процессах рассуждения, что приводит к непредсказуемым результатам. Модели могут генерировать правдоподобные, но логически ошибочные ответы, особенно в сложных задачах, требующих многоступенчатых умозаключений. Эта проблема проявляется в неспособности последовательно применять правила логики, игнорировании ключевых деталей в исходных данных или склонности к галлюцинациям — генерации информации, не основанной на фактах. В результате, предсказать точность ответа БЯМ становится затруднительным, что ограничивает их применение в критически важных областях, где требуется абсолютная достоверность и надежность, например, в медицине или юриспруденции.
Несмотря на впечатляющие возможности, современные большие языковые модели (LLM) демонстрируют ограниченную надежность в процессе рассуждений, что приводит к непредсказуемым результатам. Традиционные подходы к увеличению масштаба моделей, такие как увеличение объема обучающих данных и количества параметров, постепенно теряют эффективность в решении этой проблемы. Все больше исследований указывают на необходимость разработки принципиально новых методов, направленных на повышение точности и надежности логических выводов, осуществляемых LLM. Эти методы должны выходить за рамки простого увеличения вычислительных ресурсов и фокусироваться на улучшении архитектуры моделей и алгоритмов обучения, чтобы обеспечить более последовательные и достоверные результаты рассуждений.
PETS: Принципиальный Подход к Самосогласованности
Метод PETS представляет собой новый подход к масштабированию на этапе тестирования, который стратегически распределяет вычислительные ресурсы (последовательности рассуждений) с целью максимизации “Коэффициента Самосогласованности” (Self-Consistency Rate). Этот коэффициент измеряет степень согласованности между различными путями рассуждений, полученными для одного и того же запроса. В отличие от традиционных методов, PETS динамически выделяет больше ресурсов тем запросам, где наблюдается низкий уровень согласованности между различными рассуждениями, что позволяет повысить надежность и точность принимаемых решений. Эффективность метода заключается в адаптивном распределении ресурсов, направленном на достижение максимального уровня согласованности ответов.
Метод PETS использует концепцию самосогласованности (Self-Consistency) путем генерации нескольких путей рассуждений для каждого запроса. Этот подход позволяет повысить устойчивость модели к случайным ошибкам и повысить надежность ответов. Вместо того, чтобы полагаться на единственный вывод, PETS генерирует множество возможных решений, оценивает их согласованность и выбирает наиболее часто встречающийся ответ. Это снижает вероятность получения неверного результата из-за случайных флуктуаций в процессе генерации и обеспечивает более стабильные и точные предсказания, особенно в задачах, требующих сложных рассуждений.
Фреймворк PETS обеспечивает эффективную работу как в режиме пакетной обработки (‘Offline Batch Setting’), когда все входные данные доступны заранее, так и в режиме потоковой обработки (‘Online Streaming Setting’), когда данные поступают последовательно. В пакетном режиме PETS может оптимально распределять ресурсы для повышения согласованности ответов на весь набор запросов. В режиме потоковой обработки, PETS динамически адаптирует количество используемых вычислительных ресурсов в зависимости от сложности каждого отдельного запроса, обеспечивая масштабируемость и возможность работы в реальном времени. Эта адаптивность позволяет использовать PETS в различных сценариях, включая обработку больших объемов данных и интерактивные приложения.
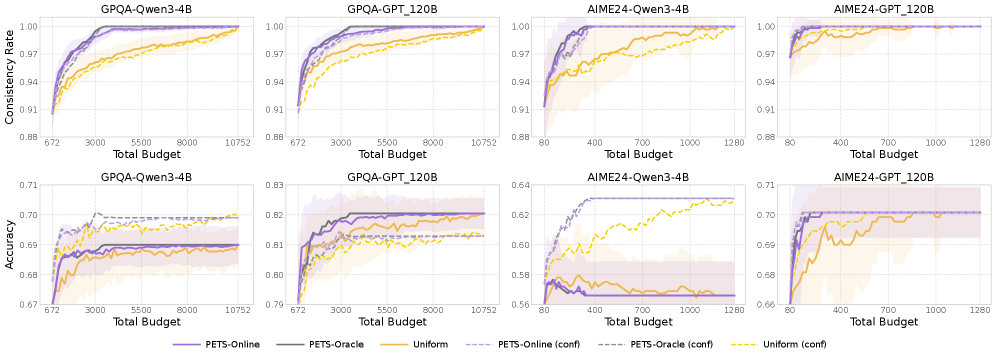
Адаптивное Распределение Траекторий для Оптимальных Рассуждений
Метод PETS использует ‘Байесовское адаптивное распределение траекторий’ (Bayesian Adaptive Trajectory Allocation) для динамической корректировки количества траекторий рассуждений в зависимости от сложности вопроса. Более сложные вопросы получают большее количество траекторий для обеспечения более надежного и точного ответа. Данный подход основан на оценке вероятности правильного ответа, что позволяет системе выделять больше вычислительных ресурсов на вопросы, требующие более глубокого анализа и, следовательно, более высокой вероятности ошибки при использовании небольшого числа траекторий. Алгоритм оценивает сложность вопроса на основе предварительного анализа и соответствующим образом регулирует количество генерируемых траекторий рассуждений.
Адаптивное распределение вычислительных ресурсов в PETS направлено на оптимизацию баланса между вычислительными затратами и точностью рассуждений. Вместо фиксированного количества прогонов логических цепочек (traces), система динамически регулирует их число в зависимости от сложности вопроса. Это позволяет снизить общие вычислительные издержки, особенно для простых вопросов, не требующих большого количества итераций для достижения консистентности. За счет фокусировки ресурсов на более сложных задачах, адаптивный подход повышает эффективность использования вычислительных мощностей и позволяет достичь требуемого уровня точности с минимальными затратами.
Тестирование метода на различных больших языковых моделях, включая Qwen3-30B-A3B-Thinking, gpt-oss-120b и QwenLong-L1.5-30B-A3B, показало значительное улучшение показателей самосогласованности на эталонных наборах данных, таких как GPQA-Diamond, AIME 25 и Brumo 25. В частности, адаптивное распределение траекторий позволило снизить необходимое количество траекторий для достижения полной самосогласованности до 75% по сравнению с равномерным распределением. Это указывает на эффективность подхода в оптимизации баланса между вычислительными затратами и точностью рассуждений.
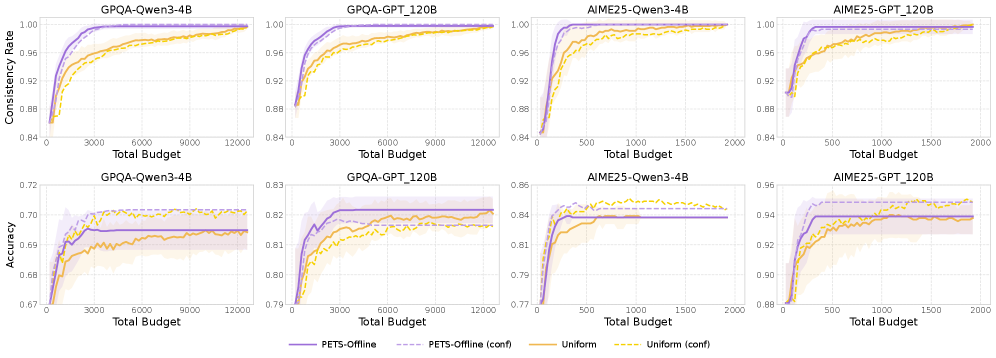
Повышение Надёжности Выводов с Взвешенным Мажоритарным Голосованием
В основе функционирования PETS лежит механизм взвешенного мажоритарного голосования, позволяющий учитывать надежность каждого этапа рассуждений. Вместо простого подсчета голосов, система присваивает каждому варианту ответа вес, определяемый так называемым «Уровнем Доверия» (Confidence Score) соответствующего логического пути. Таким образом, более обоснованные и последовательные рассуждения оказывают большее влияние на конечный результат, в то время как менее надежные цепочки аргументов, напротив, оказывают меньшее. Этот подход позволяет значительно повысить устойчивость и точность получаемых ответов, особенно в условиях, когда отдельные этапы рассуждений могут быть подвержены ошибкам или неточностям.
В основе повышения надежности результатов лежит механизм, смягчающий влияние не самых достоверных цепочек рассуждений. Вместо того, чтобы слепо полагаться на каждую последовательность логических шагов, система оценивает вероятность правильности каждого пути. Менее надежные цепочки, содержащие потенциальные ошибки или неточности, получают меньший вес при формировании окончательного ответа. Это позволяет эффективно фильтровать шум и концентрироваться на наиболее вероятных и обоснованных выводах, что, в свою очередь, приводит к более точным и стабильным результатам, даже если отдельные этапы рассуждений не являются безупречными. Такой подход позволяет добиться значительного улучшения общей производительности системы, обеспечивая высокую степень доверия к полученным ответам.
Система PETS выходит за рамки традиционных оценок точности, стремясь к более надежному и заслуживающему доверия процессу рассуждений. Оптимизация на основе самосогласованности и использование взвесованного голосования, учитывающего уверенность каждого этапа рассуждений, позволяет PETS демонстрировать стабильные результаты даже при использовании относительно небольших моделей, таких как ‘Qwen3-4B-Thinking’ и ‘gpt-oss-20b’. Важно отметить, что результаты, полученные в режиме реального времени (PETS-Online), практически не отличаются от результатов, полученных с использованием идеальной информации (PETS-Oracle), что подтверждает эффективность процедуры оценки уверенности и надежность всей системы.
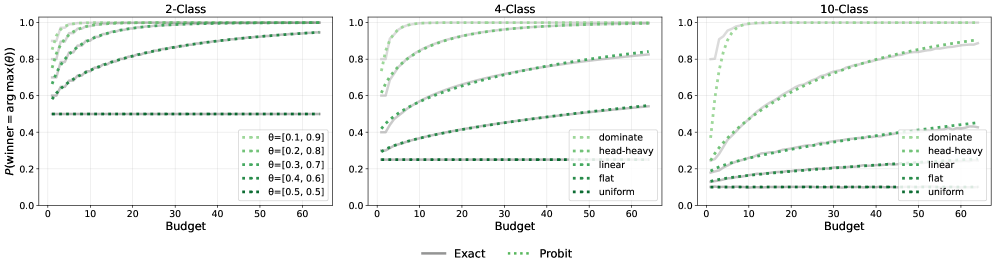
Представленная работа демонстрирует стремление к оптимизации вычислительных ресурсов при работе с большими языковыми моделями. Авторы предлагают framework PETS, позволяющий эффективно распределять бюджет выделенных ресурсов для достижения оптимального уровня согласованности результатов. Этот подход особенно важен в контексте ограниченных вычислительных мощностей, где каждый сбой может сигнализировать о необходимости рефакторинга стратегии распределения ресурсов. Как однажды заметил Дональд Дэвис: «Все системы стареют — вопрос лишь в том, делают ли они это достойно». Данное исследование, направленное на повышение эффективности и согласованности, является ярким примером достойного старения систем искусственного интеллекта, адаптирующихся к изменяющимся требованиям и ограничениям.
Что впереди?
Представленный подход к распределению вычислительных ресурсов, несомненно, увеличивает эффективность логических построений больших языковых моделей в моменте. Однако, иллюзия оптимизации неизбежно столкнется с энтропией. Любое улучшение, каким бы принципиальным оно ни было, стареет быстрее, чем предполагается. Зафиксированное увеличение производительности, вероятно, станет лишь отправной точкой для нового этапа гонки вооружений — требования к сложности задач будут расти экспоненциально, а вычислительные бюджеты останутся ограниченными.
Особый интерес представляет вопрос о динамической оценке сложности задачи. Текущие метрики, вероятно, недостаточно чувствительны к тонким нюансам, определяющим истинную когнитивную нагрузку. Откат — это путешествие назад по стрелке времени, и неспособность адекватно оценить сложность может привести к неэффективному распределению ресурсов и, как следствие, к регрессии в производительности. Необходимо разработать более гибкие и адаптивные механизмы оценки, способные предвидеть будущие потребности в вычислительных ресурсах.
В конечном итоге, вся эта оптимизация — лишь локальная победа над неумолимым течением времени. Вместо погони за абсолютной эффективностью, возможно, стоит сосредоточиться на создании систем, способных достойно стареть — систем, которые могут адаптироваться к изменяющимся условиям и сохранять свою функциональность даже при ограниченных ресурсах.
Оригинал статьи: https://arxiv.org/pdf/2602.16745.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- ЕвроТранс акции прогноз. Цена EUTR
- Серебро прогноз
- Российский рынок: Нефть, дивиденды и геополитика. Что ждет инвесторов? (23.03.2026 18:32)
- Альтернативные Крипты в Фокусе: Институциональный Спрос, Обновления Ethereum и Восстановление XRP (11.04.2026 16:45)
- Разделение акций: История одного триумфа и ожидания другого
- Стоит ли покупать евро за австралийские доллары сейчас или подождать?
- ЭсЭфАй акции прогноз. Цена SFIN
- РУСАЛ акции прогноз. Цена RUAL
- Прогноз нефти
2026-02-21 23:04