Автор: Денис Аветисян
Новый подход позволяет значительно повысить эффективность сложных рассуждений, используя возможности многоагентного обучения с подкреплением.
Представлен фреймворк SCMA, совместно оптимизирующий агентов рассуждения, сегментации и оценки для сжатия процесса мышления и повышения точности.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
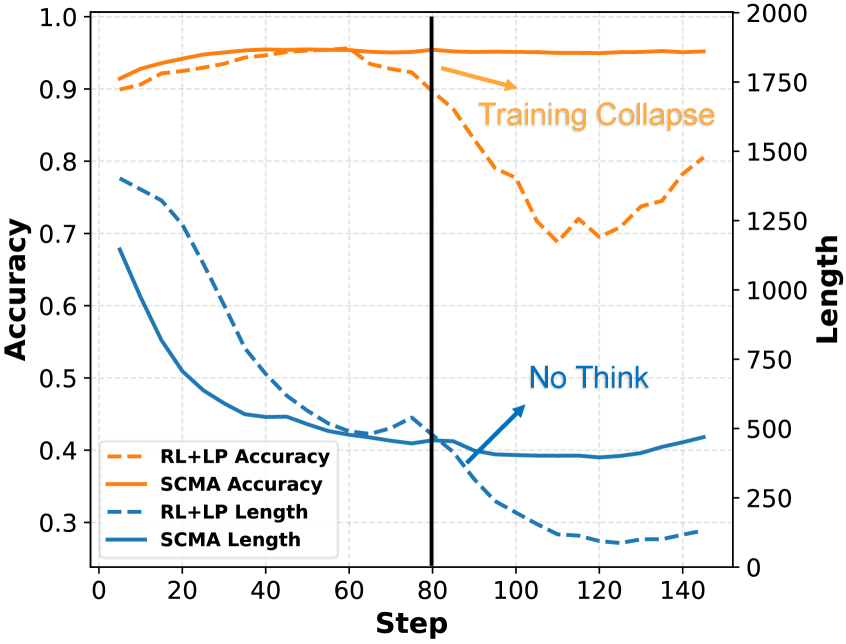
Бесплатный Телеграм каналИзбыточность рассуждений в больших языковых моделях снижает эффективность взаимодействия и ограничивает их применение на практике. В данной работе, посвященной теме ‘Self-Compression of Chain-of-Thought via Multi-Agent Reinforcement Learning’, предложен новый подход к оптимизации процесса рассуждений, основанный на многоагентном обучении с подкреплением. Разработанный фреймворк SCMA позволяет избирательно снижать вес избыточных фрагментов рассуждений, сохраняя при этом ключевую логику, что приводит к сокращению длины ответа на 11.1%-39.0% и повышению точности на 4.33%-10.02%. Возможно ли дальнейшее повышение эффективности и надежности больших языковых моделей за счет более тонкой оптимизации взаимодействия между различными агентами?
Пределы масштаба: Узкое место логического мышления
Современные большие языковые модели, несмотря на впечатляющую способность генерировать текст и выполнять разнообразные задачи, сталкиваются с существенными трудностями при решении сложных, многоступенчатых проблем, демонстрируя так называемый “барьер глубины”. Это проявляется в том, что при увеличении количества шагов в логической цепочке, точность ответов резко падает. Модели, обученные на огромных объемах данных, часто оказываются неспособны эффективно отслеживать и интегрировать информацию, необходимую для последовательного решения задачи, что приводит к ошибкам на более поздних этапах рассуждений. Данное ограничение указывает на фундаментальную проблему в архитектуре существующих моделей и требует разработки новых подходов к организации и представлению знаний для обеспечения более глубокого и надежного рассуждения.
Попытки улучшить способность больших языковых моделей к рассуждению путём простого увеличения их размера наталкиваются на закономерную проблему убывающей отдачи. Несмотря на значительные инвестиции в вычислительные ресурсы и объёмы данных, дальнейшее масштабирование моделей приводит к всё менее заметным улучшениям в решении сложных задач. Это связано с тем, что экспоненциальный рост параметров не компенсирует фундаментальные ограничения в архитектуре и алгоритмах, а также требует непомерно высоких затрат на обучение и эксплуатацию. В результате, дальнейшее увеличение размера моделей становится экономически нецелесообразным и практически неосуществимым, что заставляет исследователей искать альтернативные подходы к решению проблемы эффективного рассуждения.
Суть проблемы заключается в том, что процесс рассуждений, осуществляемый современными языковыми моделями, зачастую некомпактен и содержит избыточность. Вместо эффективного использования накопленных знаний, модели склонны к повторению одних и тех же шагов или рассмотрению несущественных деталей, что значительно замедляет решение сложных задач. Этот неоптимизированный процесс требует огромных вычислительных ресурсов и препятствует дальнейшему улучшению производительности, даже при увеличении размера модели. По сути, модели тратят большую часть своих ресурсов не на поиск ответа, а на организацию и переработку информации, что является серьезным ограничением для их масштабируемости и эффективности.
SCMA: Сжатие мысли с помощью многоагентного управления
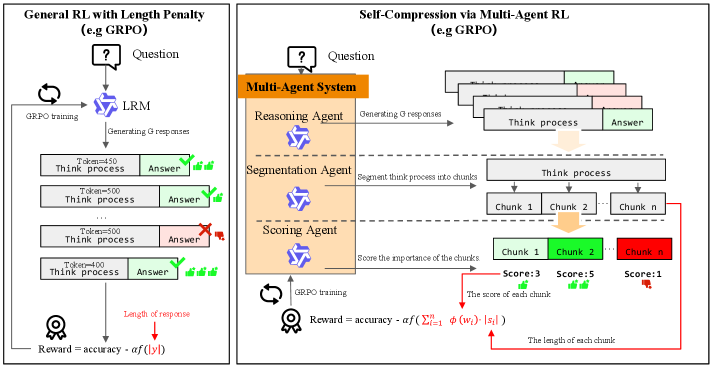
SCMA (Self-Compression via Multi-Agent Reinforcement Learning) представляет собой новый подход к сжатию процесса рассуждений в больших языковых моделях. В отличие от традиционных методов, SCMA обеспечивает не общее сокращение текста, а точечное сжатие именно этапа рассуждений, сохраняя при этом точность и логическую последовательность. Этот фреймворк позволяет динамически идентифицировать и исключать избыточную информацию на этапе формирования цепочки рассуждений, что приводит к более эффективному использованию вычислительных ресурсов и снижению задержек при обработке сложных запросов. Принципиальным отличием является возможность гранулярного контроля над процессом сжатия, позволяющего адаптировать стратегию сжатия к конкретным задачам и данным.
SCMA использует многоагентный подход, основанный на обучении с подкреплением, для оптимизации путей рассуждений. Управление процессом разделено между тремя специализированными агентами: ReasoningAgent, отвечающим за генерацию шагов рассуждений; SegmentationAgent, выполняющим динамическое разделение рассуждений на дискретные фрагменты; и ScoringAgent, оценивающим значимость каждого фрагмента. Взаимодействие между этими агентами позволяет системе адаптировать стратегию рассуждений, концентрируясь на наиболее важных аспектах задачи и эффективно управляя вычислительными ресурсами. Этот распределенный подход обеспечивает гибкость и масштабируемость, позволяя SCMA динамически регулировать сложность и длину цепочки рассуждений в зависимости от конкретного запроса.
Метод SCMA обеспечивает целенаправленное сжатие процесса рассуждений за счет динамического разбиения его на дискретные сегменты. Такой подход позволяет выделить и сохранить только существенную информацию, минимизируя избыточность и, как следствие, уменьшая общую длину цепочки рассуждений. Экспериментальные результаты на различных эталонных наборах данных демонстрируют сокращение длины рассуждений в диапазоне от 11.1% до 39.0%, что подтверждает эффективность данного метода в оптимизации вычислительных ресурсов и повышении эффективности больших языковых моделей.
Модульная архитектура SCMA позволяет значительно снизить вычислительную нагрузку за счет возможности параллельной обработки. В отличие от монолитных подходов к рассуждениям, где каждый шаг зависит от предыдущего, SCMA распределяет процесс между специализированными агентами, которые могут функционировать независимо и параллельно. Это достигается благодаря разделению процесса рассуждения на дискретные блоки, которые обрабатываются различными агентами одновременно. Такая организация позволяет эффективно использовать многоядерные процессоры и графические ускорители, сокращая общее время вычислений и энергопотребление, особенно при работе с большими объемами данных и сложными задачами рассуждения.
Динамическая приоритизация: Направление сжатия с помощью значимости
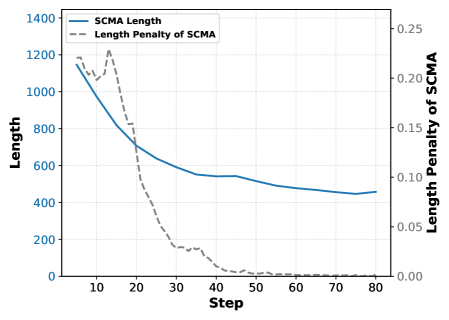
В архитектуре SCMA используется штраф за длину последовательности рассуждений — `ImportanceWeightedLengthPenalty`. Данный штраф не является фиксированным, а масштабируется в зависимости от важности сегмента, определяемой его оценкой значимости. Это означает, что более важные сегменты подвергаются меньшему штрафу за длину, что позволяет модели сохранять ключевую информацию, даже если для этого требуется более длинная последовательность токенов. Таким образом, `ImportanceWeightedLengthPenalty` динамически регулирует компромисс между длиной и информативностью, направляя процесс сжатия на сохранение наиболее релевантных частей рассуждений.
В основе механизма динамической приоритизации лежит функция WeightedCost, которая назначает различный вес токенам и сегментам входной последовательности. Ключевые элементы, определяемые `ScoringAgent` как наиболее важные для логической цепочки рассуждений, получают пониженный вес при расчете стоимости сжатия. Это позволяет алгоритму SCMA сохранять критическую информацию во время сжатия, минимизируя потери, которые могут повлиять на точность вывода. Фактически, WeightedCost направляет процесс сжатия, обеспечивая приоритетное сохранение токенов и сегментов, несущих наибольшую смысловую нагрузку.
Динамический штраф (DynamicPenalty) в процессе обучения модели SCMA корректирует масштаб штрафа на основе текущего поведения модели. Эта адаптация позволяет стабилизировать процесс обучения, предотвращая расхождение и обеспечивая более быструю сходимость. Корректировка масштаба штрафа осуществляется в реальном времени, отслеживая динамику потерь и градиентов, что позволяет избежать ситуаций, когда модель застревает в локальных минимумах или демонстрирует неустойчивое поведение. Применение DynamicPenalty способствует более эффективному обучению и повышению стабильности модели при сжатии данных.
Целенаправленная компрессия, управляемая оценкой значимости логических выводов, осуществляемой агентом ScoringAgent, демонстрирует улучшение точности рассуждений в диапазоне от 4,33% до 10,02% на различных эталонных наборах данных. Данное улучшение обусловлено тем, что механизм фокусируется на сохранении наиболее важных токенов и сегментов, определяемых агентом ScoringAgent на основе их вклада в процесс логического вывода. Экспериментальные результаты показывают, что данный подход позволяет более эффективно сжимать последовательности рассуждений без существенной потери точности, что особенно важно для задач, требующих обработки больших объемов информации.

За пределами эффективности: Последствия и будущие направления
Система сжатия и управления вниманием (SCMA) значительно расширяет возможности устоявшихся парадигм рассуждений, таких как «Цепочка мыслей» (Chain of Thought), предоставляя механизм для эффективного и контролируемого сжатия информации. В отличие от традиционных подходов, которые часто приводят к потере важных деталей при уменьшении объема данных, SCMA позволяет выборочно сохранять ключевые аспекты рассуждений, обеспечивая сохранение точности при одновременном снижении вычислительных затрат. Этот подход особенно важен при работе со сложными задачами, требующими многоступенчатого анализа, поскольку он позволяет моделировать более длинные цепочки рассуждений без экспоненциального увеличения необходимых ресурсов. Фактически, SCMA выступает в роли интеллектуального фильтра, выделяя наиболее релевантную информацию и отбрасывая избыточность, что делает процесс рассуждения более эффективным и масштабируемым.
Механизм сжатия и масштабирования SCMA позволяет преодолеть традиционные ограничения, связанные с ресурсоемкостью сложных моделей рассуждений. В отличие от подходов, требующих экспоненциального увеличения вычислительных мощностей при усложнении задачи, SCMA обеспечивает эффективное сжатие информации, что открывает возможность развертывания передовых моделей даже на устройствах с ограниченными ресурсами, таких как мобильные телефоны или встроенные системы. Это существенно расширяет сферу применения искусственного интеллекта, делая сложные алгоритмы рассуждений доступными не только в центрах обработки данных, но и в повседневной жизни, а также в областях, где вычислительные ресурсы ограничены или недоступны.
Архитектура данной системы построена по модульному принципу, что значительно упрощает ее интеграцию с другими передовыми методами рассуждений. Такая гибкость позволяет объединять преимущества SCMA с возможностями, например, алгоритмов поиска решений или техник генерации гипотез, создавая более мощные и эффективные системы искусственного интеллекта. Более того, модульность открывает широкие перспективы для разработки и внедрения новых стратегий сжатия данных, позволяя исследователям экспериментировать с различными подходами и оптимизировать производительность системы в зависимости от конкретных задач и доступных ресурсов. Это способствует непрерывному совершенствованию технологии и адаптации к растущим требованиям в области искусственного интеллекта и машинного обучения.
В ходе тестирования, разработанный метод сжатия знаний, известный как SCMA, продемонстрировал впечатляющую точность в 89.20% при решении задач из набора данных MATH500, используя языковую модель Qwen3. Этот результат свидетельствует о значительном потенциале SCMA в области сложных математических рассуждений и указывает на возможность создания более компактных и эффективных моделей, способных решать задачи, требующие глубокого анализа и логического мышления. Такая высокая точность, достигнутая при сжатии знаний, открывает перспективы для применения SCMA в различных областях, где требуется обработка сложных числовых и логических задач, включая научные исследования, финансовый анализ и разработку интеллектуальных систем.
Исследование демонстрирует, что сложные системы могут оптимизироваться не только сверху вниз, но и через взаимодействие множества независимых агентов. Это напоминает подход к декомпозиции задач, где каждый агент отвечает за свой фрагмент решения, а затем эти фрагменты собираются воедино. Тим Бернерс-Ли однажды заметил: «Веб — это не просто набор страниц, связанных гиперссылками, а сложная система, в которой каждый элемент влияет на все остальные». И подобно тому, как веб требует постоянной оптимизации и адаптации, так и представленный метод SCMA стремится к самооптимизации процесса рассуждений, сжимая его и повышая эффективность за счет совместной работы агентов, отвечающих за различные этапы — рассуждение, сегментацию и оценку. В конечном итоге, подобный подход открывает путь к созданию более интеллектуальных и экономичных систем.
Куда Ведет Этот Лабиринт?
Представленный подход, позволяющий модели самопроизвольно сжимать цепочку рассуждений, обнажает более глубокую проблему: не эффективность как таковая, а природу самого процесса мышления. Если алгоритм способен оптимизировать и отбросить избыточность в собственных рассуждениях, то возникает вопрос — насколько вообще «мысль» является последовательным, линейным построением, и насколько — хаотичным поиском в пространстве возможностей? Очевидно, что текущая архитектура, оптимизируемая через обучение с подкреплением, — лишь одна из множества возможных конфигураций.
Следующим шагом видится не просто повышение скорости или точности, а создание систем, способных к «нелинейному» мышлению, к одновременной оценке множества гипотез, к признанию и использованию противоречий. Ограничением остается, конечно, интерпретируемость: сжатая цепочка рассуждений может быть эффективной, но оставаться непрозрачной даже для создателей. Ирония в том, что, стремясь к более «умным» машинам, можно столкнуться с машинами, чью логику невозможно понять.
Будущие исследования, вероятно, будут направлены на интеграцию принципов самоорганизации и эволюционных алгоритмов. Вместо жесткого программирования «правильных» шагов, можно позволить системе самостоятельно исследовать пространство стратегий, отбрасывая неэффективные и усиливая удачные. Это, конечно, потребует разработки новых метрик и методов оценки, поскольку привычные критерии точности могут оказаться недостаточными для оценки «креативности» или «интуиции» машины.
Оригинал статьи: https://arxiv.org/pdf/2601.21919.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Рубль, ставка ЦБ и геополитика: Что ждет российский рынок в ближайшее время
- Стоит ли покупать фунты за йены сейчас или подождать?
- Газовый кризис и валютные риски: что ждет российский рынок? (14.03.2026 18:32)
- Bitcoin vs. Gold: Разрыв в корреляции и новые горизонты AI. Что ждет инвесторов? (20.03.2026 03:15)
- Будущее WLD: прогноз цен на криптовалюту WLD
- О нет! Стратегический запас биткоинов сталкивается с крахом! 😱 (См. график №4)
- Аэрофлот акции прогноз. Цена AFLT
- Российский рынок: Ожидание ставки, стабилизация рубля и рост прибылей компаний (20.03.2026 02:32)
- Будущее BNB: прогноз цен на криптовалюту BNB
- Тесла: Полет в Бездну или Искупление?
2026-02-02 05:59