Автор: Денис Аветисян
Новый подход позволяет извлекать структурированную информацию о рисках из финансовых отчетов, используя возможности больших языковых моделей.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал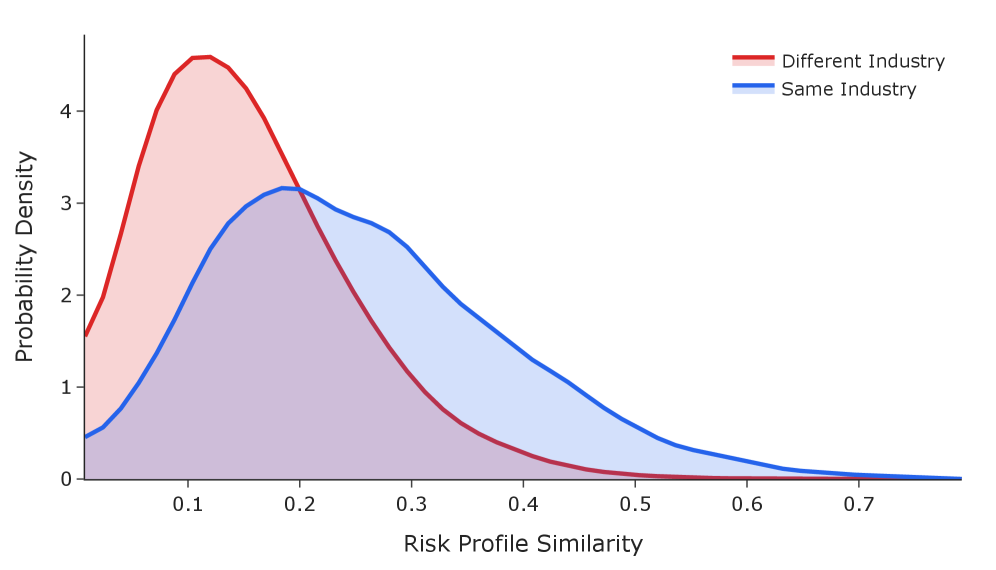
Методика, основанная на таксономическом выравнивании, семантических представлениях и самообучении моделей, обеспечивает высокую точность и возможность непрерывного улучшения таксономии рисков.
Несмотря на возрастающий объем неструктурированной информации в корпоративной отчетности, извлечение и систематизация факторов риска остается сложной задачей. В работе ‘Taxonomy-Aligned Risk Extraction from 10-K Filings with Autonomous Improvement Using LLMs’ предложен метод структурированного извлечения факторов риска из отчетов 10-K, основанный на гибридном подходе, сочетающем большие языковые модели, семантические встраивания и валидацию с использованием LLM в роли эксперта. Достигнута высокая точность извлечения и продемонстрирована возможность автоматического улучшения таксономии рисков, что подтверждается увеличением разделения вложений на 104.7% и статистически значимым повышением сходства профилей рисков для компаний из одной отрасли. Может ли данная методология стать основой для создания самообучающихся систем анализа рисков, способных адаптироваться к меняющимся условиям и обеспечивать более глубокое понимание корпоративных рисков?
Разоблачение Рисков: Вызов Корпоративной Прозрачности
Современные корпорации генерируют огромные объемы текстовой информации в своих отчетах, таких как 10-K, однако выявление значимых факторов риска, скрытых в этом массиве данных, представляет собой серьезную задачу. Несмотря на кажущуюся прозрачность, объем и сложность корпоративной отчетности затрудняют ручной анализ и своевременное выявление потенциальных угроз. Вычленение действительно важных рисков из общего потока информации требует значительных временных и ресурсных затрат, а также экспертной оценки, что делает процесс трудоемким и подверженным человеческим ошибкам. Подобный объем неструктурированных данных требует разработки автоматизированных систем, способных эффективно обрабатывать и анализировать информацию для обеспечения более точной оценки корпоративных рисков.
Традиционные методы анализа корпоративных отчетов, такие как ручной просмотр и ограниченные поисковые запросы, сталкиваются с серьезными трудностями при обработке огромных объемов неструктурированных данных. Компании ежегодно генерируют колоссальное количество текстовой информации в своих отчетах, включая 10-K, но извлечение значимых факторов риска из этого потока данных требует значительных временных и трудовых затрат. Неспособность эффективно категоризировать и анализировать эту информацию препятствует проведению своевременной и точной оценки рисков, что может привести к упущению критически важных сигналов и неверным инвестиционным решениям. Ограниченность существующих подходов подчеркивает необходимость в автоматизированных решениях, способных оперативно выявлять и классифицировать риски на основе анализа текстовых данных.
Огромный объем и сложность раскрытия корпоративных рисков обуславливают необходимость автоматизированных решений для своевременного и точного анализа. Исследования показали, что разработанная система демонстрирует на 63% более высокую схожесть профилей риска у компаний, работающих в одной отрасли, по сравнению с компаниями из разных секторов. Это указывает на способность системы эффективно выявлять общие риски внутри конкретной индустрии, что позволяет инвесторам и аналитикам более точно оценивать потенциальные угрозы и принимать обоснованные решения. Такой подход к анализу информации, основанный на автоматизации, существенно превосходит традиционные методы, требующие значительных временных и трудовых затрат, и обеспечивает более оперативную и надежную оценку рисков.
Автоматическое Извлечение Рисков: LLM и Семантическое Отображение
Для автоматической идентификации и извлечения факторов риска из финансовых документов используется подход, основанный на больших языковых моделях (LLM Extraction). В ходе обработки отчетов 10-K компаний, входящих в индекс S&P 500 за 2024 год, было извлечено и верифицировано 10 688 факторов риска. Данный процесс позволяет автоматизировать анализ больших объемов текстовой информации, выявляя ключевые риски, указанные в официальной отчетности компаний.
Извлеченная информация о факторах риска подвергается сопоставлению с предопределенной Трехуровневой Таксономией Рисков, что обеспечивает стандартизированную категоризацию и последующий анализ. Эта таксономия структурирована иерархически, позволяя детализировать риски по уровням значимости и типу, что упрощает агрегацию данных и выявление общих тенденций. Стандартизация категорий рисков повышает сопоставимость данных между различными компаниями и периодами, что необходимо для сравнительного анализа и формирования комплексных отчетов о рисках. Применение единой таксономии также облегчает автоматизацию процессов управления рисками и обеспечивает возможность количественной оценки влияния различных факторов на финансовые показатели.
В основе сопоставления извлеченных рисков с соответствующими категориями Трехуровневой Таксономии используется метод семантического сопоставления на основе векторных представлений (Embedding-Based Mapping). Данный подход предполагает преобразование как извлеченных текстовых описаний рисков, так и названий категорий таксономии в многомерные векторные представления, отражающие их семантическое значение. Сопоставление осуществляется путем вычисления степени близости этих векторов, используя такие метрики, как косинусное расстояние. Наиболее близкая категория таксономии назначается извлеченному риску, обеспечивая автоматизированную и стандартизированную классификацию.
Обеспечение Точности: Валидация Согласованности Рисков с LLM
Для обеспечения качества сопоставления рисков используется валидация с помощью больших языковых моделей (LLM), которая оценивает семантическое соответствие между извлеченными рисками и категориями таксономии. Процесс валидации заключается в количественной оценке степени смысловой близости между описанием риска и соответствующей категорией, что позволяет определить, насколько точно извлеченный риск классифицирован. Получаемые оценки используются для выявления неточностей в сопоставлении рисков и последующей корректировки процесса извлечения или таксономии, обеспечивая более надежное и точное картирование рисков.
Процесс валидации сопоставления рисков с таксономией опирается на набор оценочных метрик, обеспечивающих количественную оценку производительности системы и выявление областей для улучшения. Эти метрики позволяют измерить степень соответствия извлеченных рисков категориям таксономии, что необходимо для обеспечения точности и надежности процесса картирования рисков. Количественные показатели, такие как точность, полнота и F1-мера, используются для оценки эффективности системы, а статистические тесты, например, Cohen’s d, подтверждают значимость наблюдаемых улучшений в кластеризации отраслей, в частности, продемонстрировано увеличение разделения эмбеддингов на 104.7% для категории одобрения фармацевтических препаратов (p<0.001).
Система использует семантическое сходство, основанное на моделях эмбеддингов, для оценки соответствия извлеченных рисков категориям таксономии. В рамках анализа категории фармацевтических одобрений, автономная оптимизация таксономии привела к увеличению разделения эмбеддингов на 104.7%. Статистическая значимость индустриального кластеризования подтверждена коэффициентом Коэна d = 1.06 (p < 0.001), что указывает на высокую достоверность полученных результатов и эффективность применяемого подхода к автоматической классификации рисков.
От Индивидуальных Рисков к Отраслевым Тенденциям
Анализ обширного массива финансовых отчетов позволяет выявлять и группировать компании по схожим профилям риска, формируя отраслевые кластеры. Данный подход выходит за рамки индивидуальной оценки рисков, предоставляя возможность увидеть общие тенденции и уязвимости внутри целых отраслей. Автоматизированная система, обрабатывая данные из различных источников, определяет ключевые факторы риска, характерные для каждой группы компаний, что позволяет инвесторам, регуляторам и самим компаниям более эффективно оценивать и управлять потенциальными угрозами. Выделение отраслевых кластеров на основе общих рисков способствует более точному сравнению компаний внутри одной отрасли и выявлению лидеров в области управления рисками.
Для упрощения анализа финансовых документов и повышения скорости получения актуальных данных, система обеспечивает бесшовную интеграцию с внешними источниками, в частности, платформой Massive.com. Этот подход позволяет автоматически извлекать необходимые сведения непосредственно из первоисточников, исключая трудоемкий ручной ввод и минимизируя вероятность ошибок. Благодаря использованию API, система способна оперативно адаптироваться к изменениям в структуре данных и поддерживать актуальность информации, что критически важно для выявления и оценки финансовых рисков в режиме реального времени. Такая интеграция не только оптимизирует рабочий процесс, но и позволяет аналитикам сосредоточиться на более сложных задачах, требующих экспертной оценки.
Система спроектирована с возможностью автономной адаптации таксономии рисков, что позволяет ей учитывать появляющиеся угрозы и изменять классификацию в режиме реального времени. Этот процесс самообучения позволяет выявлять все более тонкие взаимосвязи между компаниями и их профилями риска. Исследования показали, что благодаря данной функции, схожесть профилей риска у предприятий, относящихся к одной отрасли, возрастает на 63% по сравнению с компаниями из разных секторов, что существенно повышает точность кластеризации и позволяет более эффективно оценивать и управлять отраслевыми рисками.
Исследование демонстрирует, как современные инструменты, вроде больших языковых моделей, пытаются систематизировать хаос корпоративной отчетности. Авторы предлагают подход, сочетающий извлечение информации и самооценку модели — своеобразный «LLM-as-a-Judge». Впрочем, эта попытка упорядочить риски напоминает наведение порядка в бардаке перед новой порцией беспорядка. Как говорил Пауль Эрдеш: «Математика — это искусство находить закономерности в хаосе». В данном случае, закономерности находятся, но гарантий, что завтрашний отчет не потребует полной перестройки «таксономии», нет. Система стабильно падает — значит, она хотя бы последовательна. В конце концов, мы не пишем код — мы просто оставляем комментарии будущим археологам.
Что дальше?
Представленная методология, безусловно, элегантна в своей попытке систематизировать хаос корпоративных отчётов. Однако, стоит помнить: любое «структурирование» — это всегда упрощение, а любое упрощение — потеря информации. Нынешние LLM, как и все инструменты, склонны к галлюцинациям и подвержены влиянию предвзятости, заложенной в обучающих данных. Поэтому, самообучающаяся таксономия, хотя и перспективна, не избавит от необходимости ручной проверки, особенно когда речь идёт о рисках, которые ещё не проявились в практике.
Более того, возникает вопрос масштабируемости. То, что работает на относительно небольшом корпусе 10-K отчётов, может оказаться неприменимым к потоку данных, генерируемому тысячами компаний. Идея «LLM как судьи» выглядит привлекательно, но требует значительных вычислительных ресурсов и, вероятно, столкнётся с проблемами, когда разнообразие рисков превысит возможности модели к обобщению. Вполне вероятно, что в погоне за автоматизацией, мы просто создадим новый уровень сложности, где «ложные срабатывания» станут обычным делом.
В конечном итоге, задача извлечения рисков — это не только техническая, но и смысловая проблема. Корпоративные отчёты пишутся людьми, которые заинтересованы в определённом представлении информации. И никакая, даже самая продвинутая модель, не сможет полностью обойти этот фактор. Иногда, простая таблица, составленная опытным аналитиком, окажется полезнее, чем сто микросервисов, каждый из которых пытается «умно» интерпретировать текст.
Оригинал статьи: https://arxiv.org/pdf/2601.15247.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Нефть, Геополитика и Рубль: Что ждет инвесторов в ближайшую неделю
- Metaplanet расширяет Bitcoin-империю: что ждет рынок и инвесторов (12.03.2026 22:45)
- Газпром акции прогноз. Цена GAZP
- Российская экономика: Бюджетное давление, геополитика и новые экспортные возможности (11.03.2026 21:32)
- Театр энергетики: акции, которые обещают вечность
- Стоит ли покупать евро за канадские доллары сейчас или подождать?
- Будущее STETH: прогноз цен на криптовалюту STETH
- Будущее OP: прогноз цен на криптовалюту OP
- Локхид Мартин: На всю жизнь?
2026-01-22 19:14