Автор: Денис Аветисян
Исследователи разработали фреймворк Co2PO, позволяющий группам агентов эффективно координировать действия и избегать рисков в сложных средах.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал![Структура [latex]Co_2PO[/latex] представляет собой каркасную систему, демонстрирующую потенциал для создания материалов с уникальными свойствами.](https://arxiv.org/html/2602.02970v1/x1.png)
Предложен алгоритм Co2PO для обучения с подкреплением в многоагентных системах с акцентом на безопасное исследование и предсказание опасностей.
Обеспечение безопасности и эффективности в задачах обучения с подкреплением для многоагентных систем представляет собой сложную проблему, обусловленную необходимостью баланса между исследованием среды и соблюдением ограничений. В данной работе представлен новый подход, ‘Co2PO: Coordinated Constrained Policy Optimization for Multi-Agent RL’, который решает эту проблему посредством координации, основанной на прогнозировании потенциальных опасностей и селективном обмене информацией между агентами. Предложенная архитектура Co2PO, использующая общую «доску объявлений» и механизм адаптивного управления, позволяет агентам предвидеть и избегать коллективные риски, не снижая при этом общую производительность. Не смогут ли подобные методы координации стать основой для создания более безопасных и эффективных многоагентных систем в различных областях применения?
Безопасность Многоагентных Систем: Вызов и Необходимость
Внедрение многоагентных систем в реальные условия требует надежных гарантий безопасности, которые зачастую отсутствуют в стандартных подходах обучения с подкреплением. Это связано с тем, что традиционные алгоритмы оптимизируют поведение агентов для достижения максимальной награды, не учитывая при этом потенциальные риски и негативные последствия их действий. В результате, даже незначительные ошибки в обучении или непредвиденные обстоятельства в окружающей среде могут привести к нежелательному или даже опасному поведению системы. Поэтому, для успешного развертывания многоагентных систем в критически важных областях, таких как автономный транспорт или управление производственными процессами, необходимы новые методы, обеспечивающие строгий контроль над поведением агентов и гарантирующие соблюдение заданных ограничений безопасности на протяжении всего жизненного цикла системы.
Традиционные методы обучения с подкреплением часто сталкиваются с трудностями в сложных средах, где агенты должны одновременно максимизировать вознаграждение и соблюдать строгие ограничения по затратам. Это приводит к непредсказуемому поведению, поскольку алгоритмы, оптимизирующие только вознаграждение, могут игнорировать или недооценивать потенциальные негативные последствия своих действий. В результате, агенты могут выбирать стратегии, которые максимизируют краткосрочную выгоду, но приводят к значительным издержкам или даже к аварийным ситуациям в долгосрочной перспективе. Для решения этой проблемы требуется разработка новых алгоритмов, способных эффективно балансировать между стремлением к вознаграждению и соблюдением установленных ограничений, обеспечивая тем самым предсказуемость и безопасность поведения агентов в реальных условиях.
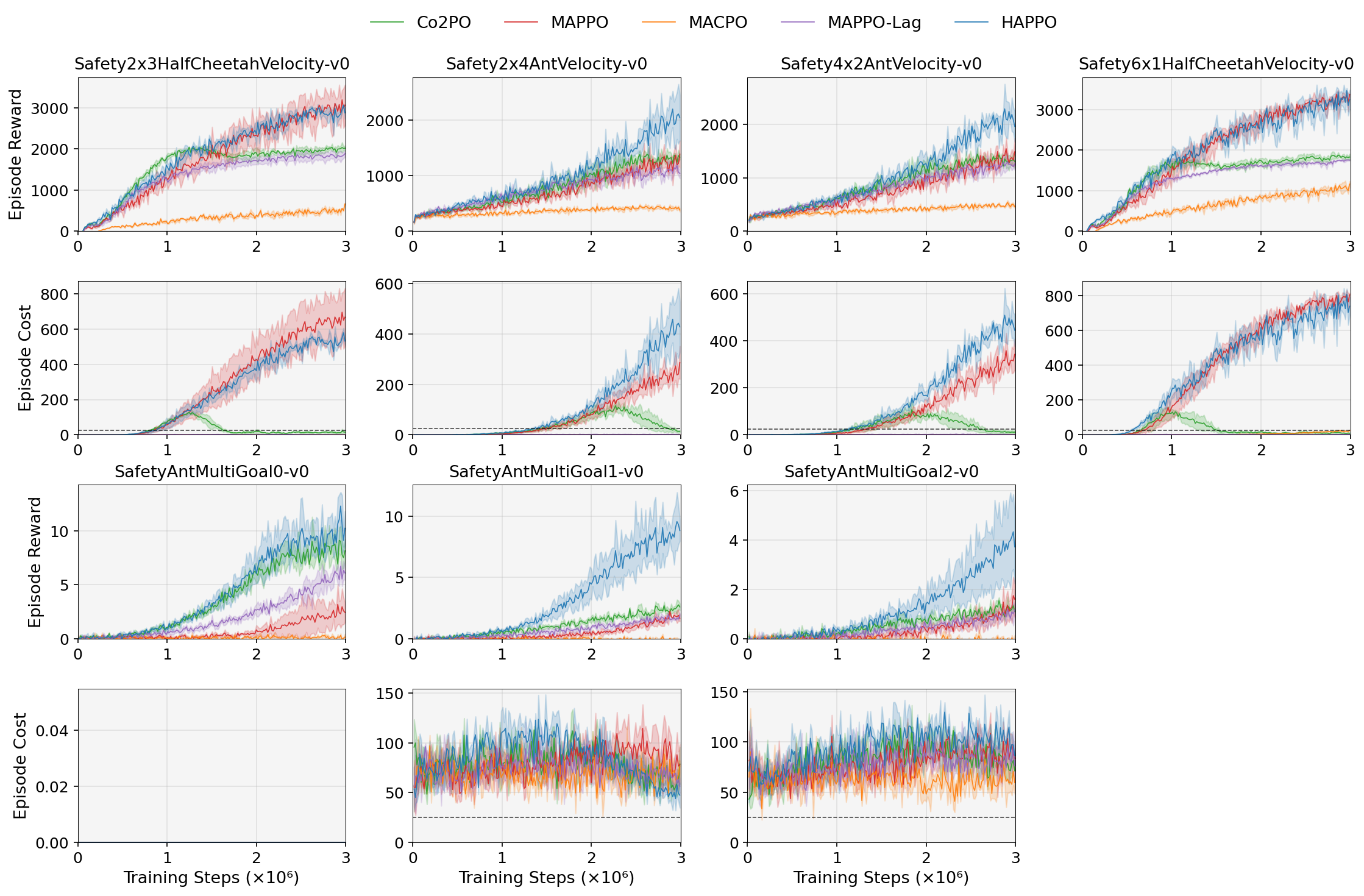
Семейства бенчмарков ‘Velocity Family’ и ‘MultiGoal Family’ представляют собой ключевой инструмент для оценки и развития алгоритмов, обеспечивающих безопасность многоагентных систем. Эти среды моделируют сложные сценарии, в которых агенты должны достигать поставленных целей, одновременно соблюдая строгие ограничения, например, поддерживая определенную скорость или избегая столкновений. Их разработка подчеркивает необходимость в алгоритмах, которые не просто максимизируют вознаграждение, но и активно учитывают потенциальные издержки и риски, связанные с действиями агентов, как в процессе обучения, так и при развертывании в реальных условиях. Эффективное решение задач, поставленных этими бенчмарками, требует от алгоритмов способности предвидеть и предотвращать опасные ситуации, что является критически важным для надежной и безопасной работы многоагентных систем в различных областях применения.
Ограниченное Многоагентное Обучение: Структура Безопасной Координации
Ограниченное многоагентное обучение с подкреплением (Constrained MARL) представляет собой структурированный подход к интеграции ограничений безопасности в процесс обучения. В отличие от традиционного обучения с подкреплением, которое фокусируется исключительно на максимизации суммарной награды, Constrained MARL явно учитывает ограничения на накапливаемую стоимость (cost) действий агентов. Это достигается путем формулирования задачи обучения, которая одновременно оптимизирует награду и гарантирует, что стоимость действий остается в пределах заданных границ. Такой подход позволяет создавать системы, в которых агенты координируют свои действия для достижения общей цели, избегая при этом потенциально опасных или нежелательных ситуаций, что особенно важно в критически важных приложениях, таких как робототехника и автономные системы.
Ограниченное многоагентное обучение с подкреплением (Constrained MARL) направлено на максимизацию суммарного вознаграждения агентов при одновременном соблюдении заданных ограничений по стоимости (cost). Данный подход подразумевает, что каждое действие агента оценивается не только с точки зрения получаемого вознаграждения, но и с точки зрения потенциальных затрат, связанных с нарушением установленных границ. В результате, целью обучения становится не просто достижение максимального суммарного вознаграждения, а обеспечение безопасного и контролируемого поведения агентов, исключающего выполнение действий, приводящих к превышению допустимых значений стоимости. Это особенно важно в критически важных приложениях, где несоблюдение ограничений может привести к нежелательным последствиям или даже к катастрофе.
В основе подхода к обучению с ограничениями в многоагентном обучении с подкреплением (Constrained MARL) лежит оптимизация не просто суммарной награды, а так называемой “Допустимой Награды” (Feasible Return). Данный показатель учитывает как получаемое агентами вознаграждение, так и затраты, связанные с их действиями. Вместо максимизации \sum_{t=0}^{T} R_t , алгоритмы стремятся максимизировать \sum_{t=0}^{T} R_t - \lambda \sum_{t=0}^{T} C_t , где R_t — награда на шаге t, C_t — затраты на шаге t, а λ — коэффициент, определяющий важность соблюдения ограничений по затратам. Таким образом, агенты обучаются находить стратегии, обеспечивающие максимальную награду при соблюдении заданных ограничений по стоимости действий, что критически важно для обеспечения безопасности и надежности в реальных приложениях.
Централизованное обучение с децентрализованным выполнением (CTDE) представляет собой эффективную стратегию обучения для обучения с подкреплением для нескольких агентов с ограничениями (Constrained MARL). В рамках CTDE агенты обучаются совместно, используя глобальную информацию о состоянии и действиях всех участников, что позволяет им координировать свою деятельность и избегать нарушения установленных ограничений по стоимости. Однако, в процессе выполнения, каждый агент действует независимо, основываясь только на локальном наблюдении, что обеспечивает масштабируемость и позволяет системе функционировать в реальном времени. Такой подход позволяет сочетать преимущества централизованного планирования для обеспечения безопасности и масштабируемости децентрализованного исполнения, что особенно важно для сложных многоагентных систем.
Co2PO: Координация с Учетом Рисков для Безопасности
В условиях обучения с подкреплением для нескольких агентов (MARL) с ограничениями, часто возникает необходимость в координации действий для обеспечения безопасности и избежания нежелательных состояний. Фреймворк Co2PO разработан для решения этой задачи, предоставляя механизм, позволяющий агентам учитывать риски при принятии решений. Он обеспечивает возможность координации не как постоянный процесс, а как реакцию на потенциальные угрозы, возникающие в динамичной среде. Это позволяет избежать избыточной координации, снижая вычислительные затраты и повышая эффективность обучения в ограниченных средах, где ресурсы могут быть ограничены.
В рамках Co2PO используется механизм ‘Предсказания Опасностей’ (Hazard Prediction) для заблаговременного выявления потенциальных столкновений или небезопасных состояний. Этот механизм позволяет агентам прогнозировать возникновение критических ситуаций на основе текущих наблюдений и динамики окружающей среды. Важно, что селективная координация между агентами активируется исключительно при обнаружении прогнозируемой опасности, что позволяет избежать избыточной коммуникации и вычислительных затрат в ситуациях, когда координация не требуется. Предсказание опасностей служит триггером для обмена информацией через ‘Общую Доску’ (Shared Blackboard) и последующей совместной корректировки действий агентов, направленной на предотвращение нежелательных исходов.
В рамках Co2PO, “Общая Доска Объявлений” (Shared Blackboard) функционирует как централизованный канал связи между агентами. Агенты используют эту доску для обмена информацией, критически важной для обеспечения безопасности, включая данные о прогнозируемых опасностях и намеченных действиях. Обмен информацией осуществляется в режиме реального времени, что позволяет агентам координировать свои действия и избегать потенциальных столкновений или опасных ситуаций. Формат обмена данными стандартизирован для обеспечения совместимости и эффективности коммуникации между агентами в сложной многоагентной среде. Использование общей доски позволяет агентам действовать более скоординированно, чем при использовании локальной информации или случайной координации.
В рамках Co2PO, для эффективной оптимизации задачи обучения с подкреплением с ограничениями, используется метод лагранжева расслабления. Этот подход позволяет сбалансировать максимизацию получаемой награды и минимизацию затрат, связанных с нарушением ограничений безопасности. В ходе экспериментов было показано, что применение лагранжева расслабления приводит к приблизительно 7%-ному увеличению суммарной достижимой прибыли (feasible return) по сравнению с базовыми алгоритмами обучения с подкреплением с ограничениями (constrained MARL). L(x, \lambda) = f(x) + \lambda^T g(x), где f(x) — целевая функция (награда), g(x) — функция ограничений, а λ — множители Лагранжа.
Влияние и Перспективы Развития
Исследование демонстрирует значительный потенциал подхода Co2PO в области обучения с подкреплением для нескольких агентов (MARL) с ограничениями, направленного на создание более безопасных и надежных систем. В ходе экспериментов в многоцелевых средах зафиксировано улучшение абсолютной достижимой прибыли на 2.91, что свидетельствует о существенном прогрессе в решении задач координации и безопасности. Данный результат подчеркивает эффективность использования ограничений при обучении агентов, позволяя им не только достигать поставленных целей, но и избегать нежелательных или опасных ситуаций, что критически важно для практического применения подобных систем в реальном мире.
Разработанная система Co2PO направлена на снижение рисков, связанных с непредсказуемым поведением многоагентных систем в реальных условиях эксплуатации. В отличие от традиционных подходов, она явно включает в себя ограничения безопасности на этапе обучения, что позволяет агентам избегать опасных ситуаций и действовать более надежно. Такой подход особенно важен при развертывании систем в критически важных областях, где непредвиденные действия могут привести к серьезным последствиям. Благодаря этому, Co2PO обеспечивает не только повышение эффективности, но и существенное улучшение безопасности и предсказуемости работы многоагентных систем, открывая возможности для их применения в более широком спектре задач.
В дальнейшем планируется расширение возможностей Co2PO для применения в более сложных, реалистичных сценариях, включая динамические среды с непредсказуемыми изменениями и увеличенным числом взаимодействующих агентов. Особое внимание будет уделено повышению эффективности алгоритмов прогнозирования опасностей и координации действий агентов, что позволит снизить вычислительные затраты и обеспечить более быстрое реагирование на потенциальные угрозы. Исследования направлены на разработку методов адаптации к новым условиям и оптимизацию стратегий поведения в условиях неопределенности, что критически важно для надежной работы многоагентных систем в реальном мире. Улучшение алгоритмов прогнозирования позволит агентам предвидеть риски на большем горизонте планирования, а более эффективная координация — избегать столкновений и оптимизировать совместную деятельность.
Исследования показали, что внедрение механизма “Предвидения Опасностей” — прогнозирования рисков на расширенном временном горизонте — последовательно улучшает эффективность многоагентных систем в задачах, связанных со скоростью и динамикой. В ходе экспериментов было установлено, что использование ненулевого горизонта предвидения (H > 0) оказывает положительное влияние на общую производительность, позволяя агентам более эффективно избегать столкновений и оптимизировать траектории движения. Данный подход позволяет не просто реагировать на неминуемые угрозы, но и проактивно планировать действия, снижая вероятность возникновения опасных ситуаций и повышая надежность функционирования системы в сложных и динамичных условиях. Полученные результаты подчеркивают важность долгосрочного планирования и предвидения рисков для создания безопасных и эффективных многоагентных систем.
Представленная работа демонстрирует стремление к упрощению сложных систем, что находит отклик в словах Роберта Тарьяна: «Структура побеждает хаос». Разработанный фреймворк Co2PO, ориентированный на согласованное обучение с ограничениями в многоагентных системах, подчеркивает важность предвидения опасностей и координации действий. Вместо усложнения модели, Co2PO использует общий информационный обмен (blackboard) для повышения безопасности и эффективности, что соответствует принципу достижения совершенства путем удаления избыточности. Акцент на безопасном исследовании и предсказании угроз является логичным шагом к созданию надежных и предсказуемых систем, где ясность алгоритма обеспечивает сострадание к конечному пользователю.
Куда же дальше?
Предложенная схема, Co2PO, словно аккуратный инструмент, позволяет решать задачу координации в многоагентных системах с оглядкой на безопасность. Однако, как и любой инструмент, она не всесильна. Истинная сложность не в самом алгоритме, а в определении границ дозволенного — что есть «опасность», и как её предвидеть, когда мир полон непредсказуемости? Полагаться лишь на предсказания — признак лени. Истинное решение требует не просто избежания опасностей, а понимания их природы.
Дальнейшее развитие неизбежно связано с отказом от упрощений. «Общая доска», хоть и элегантна, все же предполагает некий общий язык, общее понимание. Но что, если агенты говорят на разных языках, имеют разные представления о мире? Тогда координация становится не задачей оптимизации, а задачей перевода — и это, пожалуй, куда более интересная проблема. Система, требующая детальных инструкций для координации, уже проиграла.
Наконец, стоит задуматься о самом понятии «безопасности». Иногда, чтобы избежать небольшого риска, приходится отказываться от значительной выгоды. И тогда «безопасность» превращается в оковы. Понятность — это вежливость, но излишняя предосторожность — признак страха. Истинная цель — не устранить все риски, а научиться с ними жить.
Оригинал статьи: https://arxiv.org/pdf/2602.02970.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Рубль, ставка ЦБ и геополитика: Что ждет российский рынок в ближайшее время
- Стоит ли покупать фунты за йены сейчас или подождать?
- Российский рынок: Ожидание ставки, стабилизация рубля и рост прибылей компаний (20.03.2026 02:32)
- Аэрофлот акции прогноз. Цена AFLT
- Стоит ли покупать доллары за бразильские реалы сейчас или подождать?
- Аналитический обзор рынка (15.09.2025 02:32)
- Рынок в ожидании ставки: падение прибыли гигантов и переток инвесторов (20.03.2026 11:32)
- Нейросети, предсказывающие скачки цен: новый подход к высокочастотной торговле
- Аналитический обзор рынка (08.10.2025 12:32)
- О нет! Стратегический запас биткоинов сталкивается с крахом! 😱 (См. график №4)
2026-02-04 13:30