Автор: Денис Аветисян
Новый метод позволяет эффективно объединять большие языковые модели, даже если они построены на разных архитектурах, расширяя возможности для малоресурсных языков.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал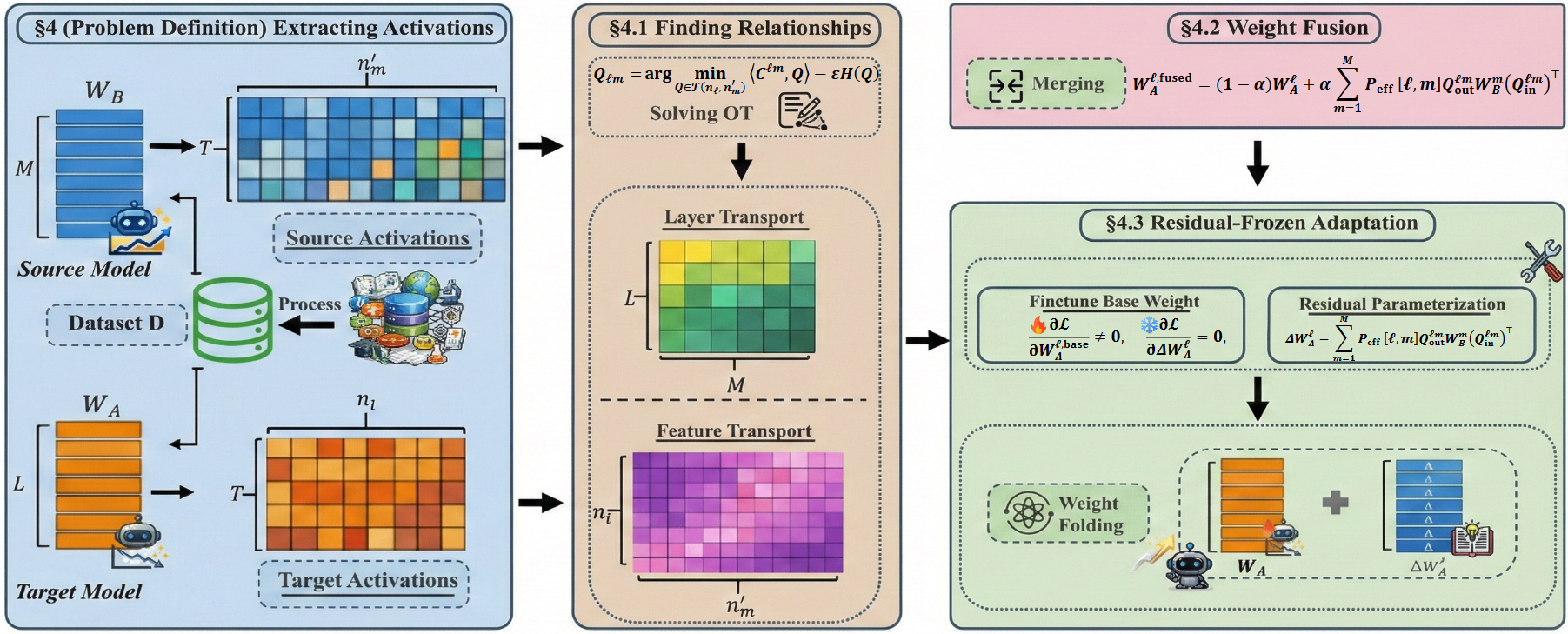
Предложен подход, использующий оптимальный транспорт для выравнивания внутренних представлений моделей и осуществления эффективного переноса параметров.
Несмотря на впечатляющие возможности больших языковых моделей (LLM), их применение в условиях ограниченных ресурсов часто требует адаптации меньших, менее производительных моделей. В работе ‘Transport and Merge: Cross-Architecture Merging for Large Language Models’ предложен новый подход к передаче знаний, позволяющий объединять LLM с различной архитектурой. В основе метода лежит выравнивание внутренних представлений моделей с использованием оптимального транспорта, что обеспечивает эффективное перенесение знаний от высокоресурсных моделей к моделям, обученным на ограниченных данных. Открывает ли этот подход новые перспективы для создания более эффективных и доступных LLM в различных областях, особенно для языков с небольшим количеством ресурсов?
Преодолевая Разрыв: Вызов Малоресурсных Языков
Несмотря на значительный прогресс в области обработки естественного языка, производительность систем заметно снижается при работе с языками, для которых доступно ограниченное количество обучающих данных. Эта проблема создает цифровой разрыв, лишая носителей малоресурсных языков доступа к технологиям, которые становятся все более распространенными в современном мире. В то время как передовые модели демонстрируют впечатляющие результаты на английском и других широко распространенных языках, их эффективность резко падает при применении к языкам с небольшим объемом оцифрованного контента, что затрудняет разработку инструментов для автоматического перевода, анализа текста и других полезных приложений. Таким образом, преодоление этой проблемы является ключевым шагом к обеспечению равного доступа к информационным технологиям для всех языковых сообществ.
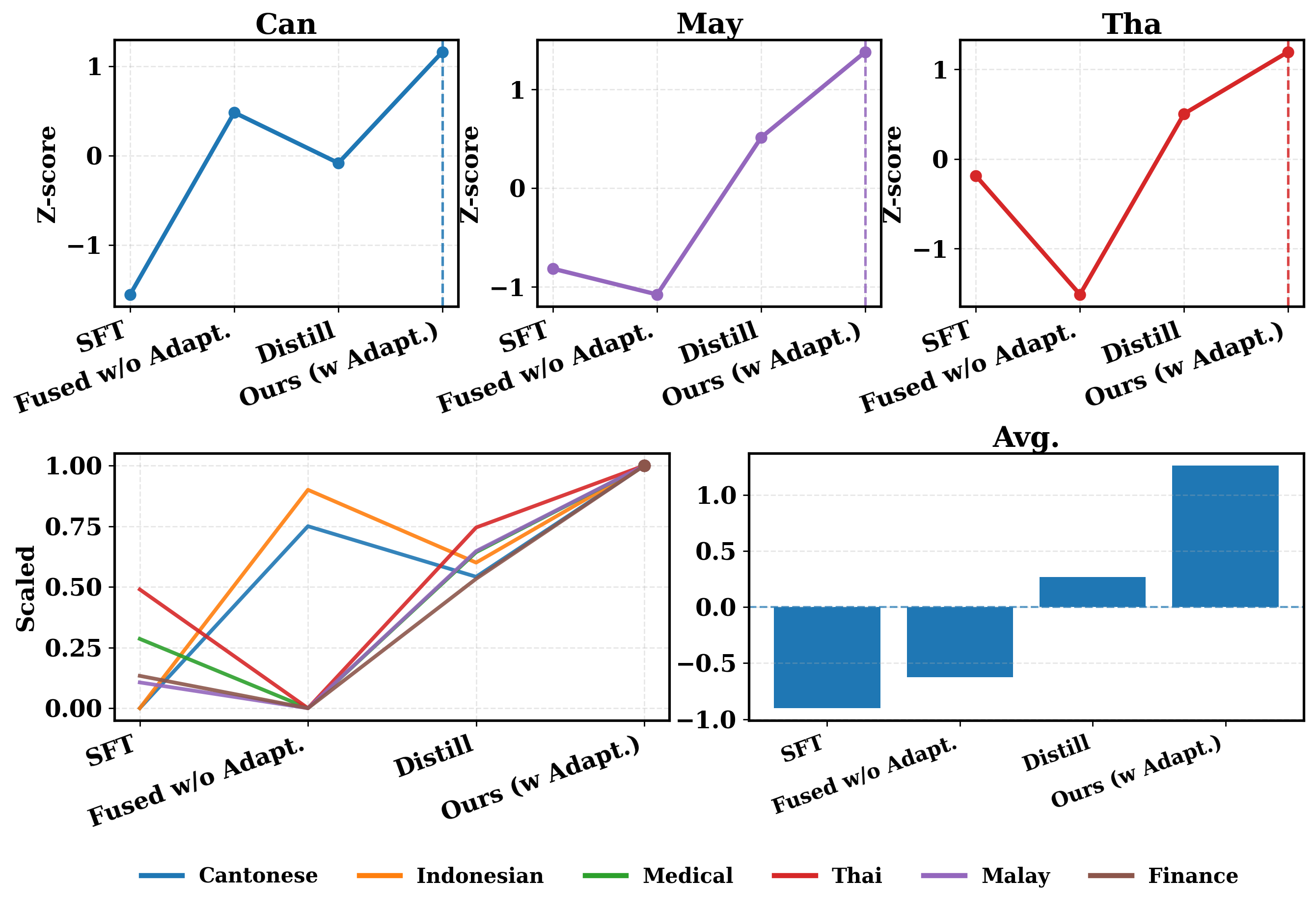
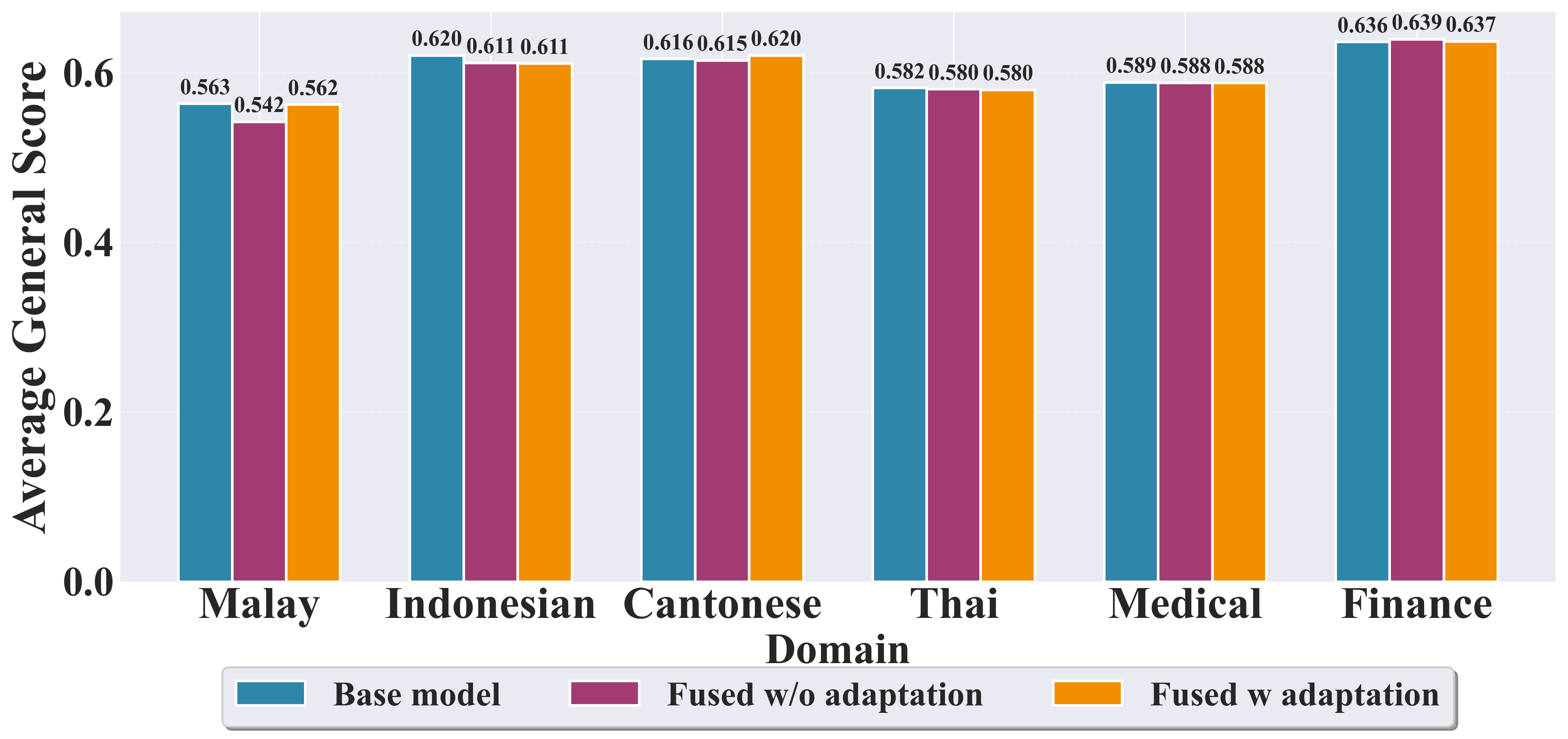
Традиционные методы переноса обучения, направленные на адаптацию моделей, разработанных для языков с большим количеством данных, к языкам с ограниченными ресурсами, часто сталкиваются с проблемой несоответствия архитектур. Это означает, что структура и организация модели, хорошо работающей на богатом языке, может не оптимально функционировать при применении к языку с меньшим объемом данных, что приводит к снижению эффективности передачи знаний. В частности, различия в количестве слоев, типах используемых нейронных сетей или даже в способах представления данных могут существенно ухудшить производительность. В результате, наблюдается более низкая средняя нормализованная эффективность по сравнению с предложенным подходом, что наглядно демонстрируется на рисунке 1, где визуализируется превосходство новой методики в преодолении этих архитектурных ограничений и обеспечении более эффективного переноса знаний.
Оптимальный Транспорт для Слияния Архитектур
Метод Cross-Architecture Fusion представляет собой подход к переносу знаний между языковыми моделями, различающимися по своей архитектуре, посредством использования оптимального транспорта. Данный метод позволяет адаптировать внутренние представления одной модели к другой, даже если их структуры существенно отличаются. В основе лежит идея минимизации «стоимости» преобразования представлений, определяемой как расстояние между параметрами моделей в пространстве активаций. В отличие от традиционных методов переноса знаний, Cross-Architecture Fusion не ограничивается перебором слоёв, а рассматривает оптимизацию соответствия между внутренними представлениями моделей как задачу оптимального транспорта, что позволяет более эффективно использовать знания, накопленные в исходной модели, при обучении новой модели с иной архитектурой.
Оптимальный транспорт (Optimal Transport) используется для выравнивания внутренних представлений языковых моделей, в частности, активационных признаков (Activation Features), посредством поиска наиболее эффективного отображения между параметрами моделей. Этот процесс подразумевает нахождение такой трансформации, которая минимизирует “стоимость” перемещения распределения активаций одной модели в распределение другой. Математически, это выражается как решение задачи оптимальной транспортировки, где “стоимость” определяется метрикой, отражающей различие между активационными признаками. Решение этой задачи позволяет сопоставить параметры моделей таким образом, чтобы максимизировать сходство их внутренних представлений, что способствует более эффективному переносу знаний между архитектурами. C = \sum_{i,j} w_{ij} d(x_i, y_j), где C — стоимость транспортировки, w_{ij} — вес транспортировки между точками x_i и y_j, а d(x_i, y_j) — расстояние между этими точками.
Предлагаемый подход к передаче знаний между моделями отличается от простого переноса слоев (layer-wise transfer) за счет использования двух уровней транспортировки. Транспортировка на уровне признаков (Feature-Level Transport) обеспечивает точное выравнивание внутренних представлений, работая с отдельными активационными векторами для достижения гранулярной адаптации. В то же время, транспортировка на уровне слоев (Layer-Level Transport) позволяет адаптировать более общую структуру модели, учитывая взаимосвязи между слоями и обеспечивая более масштабную структурную адаптацию. Комбинация этих двух подходов позволяет эффективно переносить знания, учитывая как детальные особенности представлений, так и общую архитектуру моделей.
Стабилизация и Эффективность с Регуляризацией
Для обеспечения устойчивости и надёжности передачи знаний мы используем энтропийную регуляризацию в рамках фреймворка оптимального транспорта. Этот подход предполагает добавление к целевой функции штрафа, пропорционального энтропии транспортного плана. \mathcal{L} = \mathcal{L}_{OT} + \lambda \sum_{i,j} T_{i,j} \log T_{i,j} , где \mathcal{L}_{OT} — функция потерь оптимального транспорта, T_{i,j} — элементы транспортного плана, а λ — коэффициент регуляризации. Использование энтропийной регуляризации способствует сглаживанию транспортного плана, предотвращая переобучение и повышая обобщающую способность модели при переносе знаний. Это особенно важно при работе с неструктурированными данными и сложными архитектурами нейронных сетей.
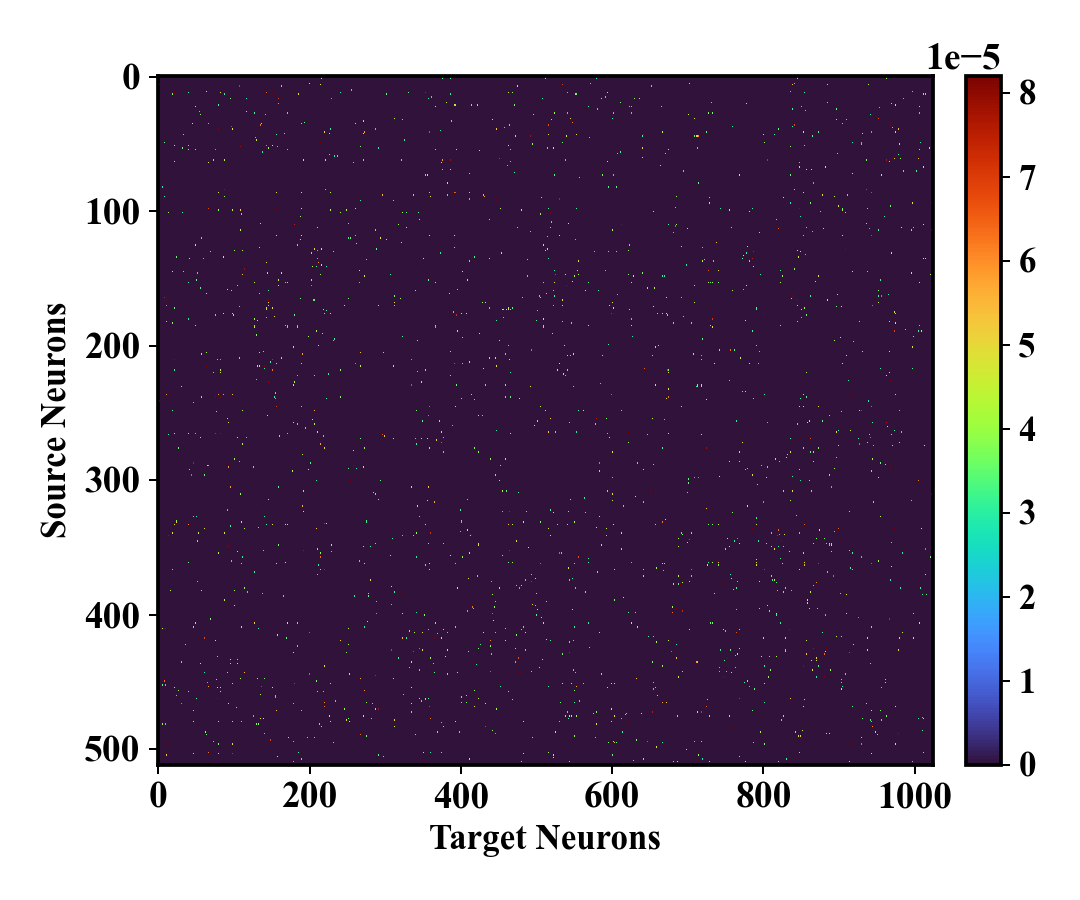
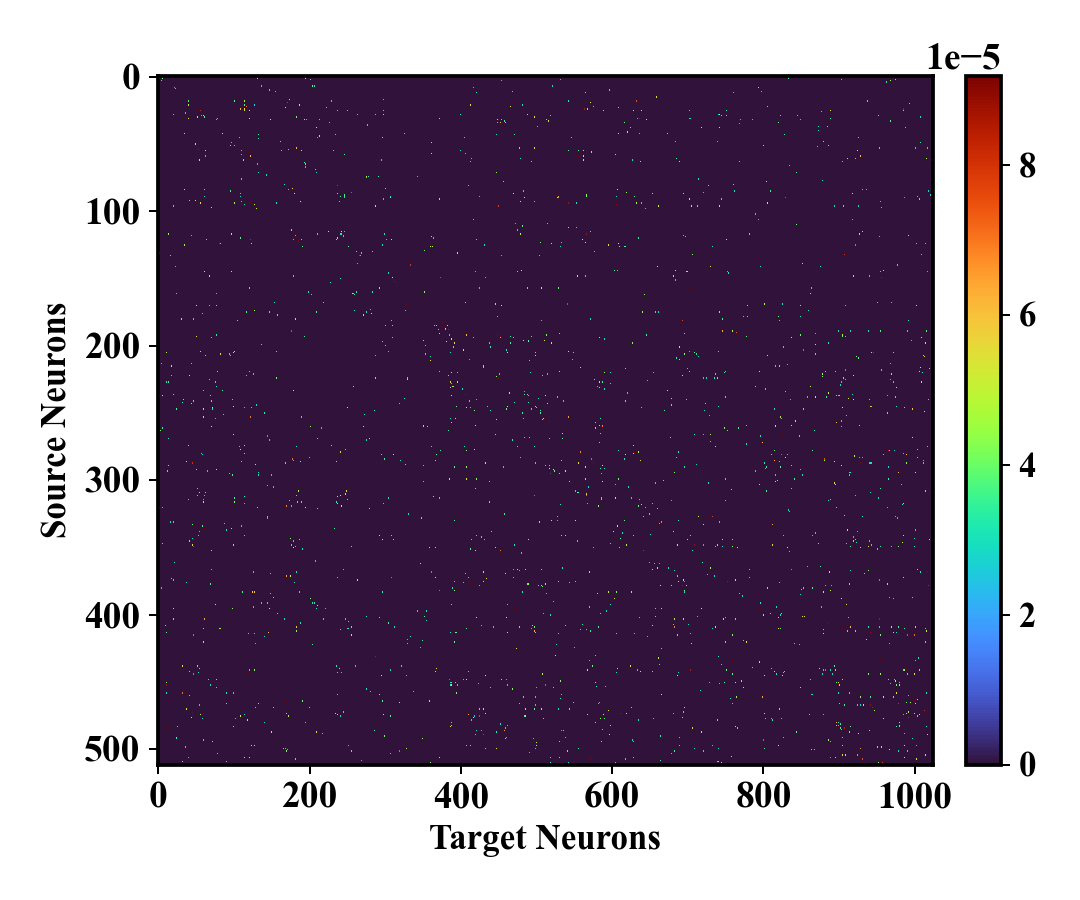
Анализ карт транспортных преобразований показывает, что выравнивание признаков между исходной и целевой моделями концентрируется на небольшом подмножестве пар нейронов. Это свидетельствует об эффективном механизме переноса знаний, поскольку не все нейроны участвуют в процессе выравнивания. Наблюдаемая разреженность карт позволяет предположить, что только наиболее релевантные связи между нейронами переносятся, что снижает вычислительную сложность и потенциально улучшает обобщающую способность целевой модели. По сути, этот подход идентифицирует и использует лишь критически важные соответствия между признаками, игнорируя менее значимые.
Для минимизации влияния на целевую модель при переносе знаний применяется метод Top-k Neuron Replacement, заключающийся в селективной замене нейронов. В рамках данного подхода, идентифицируются k наиболее значимых нейронов в исходной модели, которые затем используются для замены соответствующих нейронов в целевой модели. Выбор нейронов основывается на метриках их важности, например, на величине весов или вкладе в функцию потерь. Данный метод позволяет избежать нежелательных помех и сохранить стабильность работы целевой модели, концентрируясь на наиболее эффективных компонентах исходной модели.
Трансграничная Валидация и Прирост Производительности
Экспериментальные исследования показали заметное повышение производительности в задачах обработки естественного языка для малоресурсных языков, включая кантонский, тайский и малайский. Наблюдаемые улучшения свидетельствуют о значительном прогрессе в адаптации существующих моделей к языкам, для которых имеется ограниченное количество обучающих данных. Это особенно важно для расширения доступа к технологиям обработки языка для более широкого круга пользователей и обеспечения более справедливого и инклюзивного подхода к разработке искусственного интеллекта. Полученные результаты открывают новые возможности для создания более эффективных и точных систем обработки естественного языка, способных понимать и генерировать текст на различных языках, даже при ограниченных ресурсах.
В ходе экспериментов зафиксировано существенное повышение производительности при решении задач на малайском языке, согласно бенчмарку MalayMMLU. В частности, наблюдается прирост в 6.51% для заданий по гуманитарным наукам, 3.31% — по лингвистике, 4.19% — по прочим дисциплинам, 3.97% — в области STEM (наука, технология, инженерия и математика), и наиболее заметный рост — 5.99% — по задачам в сфере социальных наук. Полученные результаты демонстрируют способность модели эффективно адаптироваться к языкам с ограниченными ресурсами и показывать улучшенные показатели в различных областях знаний.
Для повышения эффективности переноса знаний на языки с ограниченными ресурсами была применена методика Residual-Frozen Adaptation. Данный подход позволяет сохранить ценные знания, накопленные в моделях, обученных на языках с большим объемом данных, одновременно адаптируя их к особенностям целевого языка. Результаты показали значительное улучшение точности в задачах, связанных с тайским языком (MGSM Accuracy) и кантонским диалектом (Yue-MMLU Accuracy), что демонстрирует потенциал данной техники для улучшения производительности моделей в условиях ограниченности ресурсов. Применение Residual-Frozen Adaptation позволяет избежать «катастрофического забывания» и эффективно использовать существующие знания для решения новых задач.
Исследование демонстрирует, что попытки объединить различные модели, несмотря на кажущуюся логичность, часто приводят к непредсказуемым результатам. Авторы предлагают подход, основанный на выравнивании внутренних представлений моделей с использованием оптимального транспорта, что позволяет эффективно переносить знания. Этот метод напоминает о словах Блеза Паскаля: «Все великие дела требуют времени». Ведь и здесь, для достижения гармоничного слияния моделей, требуется тонкая настройка и выравнивание, подобно долгому и кропотливому процессу выращивания сложной экосистемы. Особое внимание к выравниванию представлений — ключевой аспект, позволяющий избежать хаоса и непредсказуемости при объединении моделей с различной архитектурой, как и в любой сложной системе.
Что Дальше?
Предложенный подход к слиянию моделей, основанный на оптимальном транспорте, лишь аккуратно касается поверхности неизбежной сложности. Системы машинного обучения — это не инструменты для решения задач, а растущие экосистемы, и каждая архитектурная деталь — это пророчество о будущей точке отказа. Согласование представлений между моделями различных архитектур — это, конечно, шаг вперед, но истинная устойчивость начинается там, где кончается уверенность в полноте этого согласования. Представляется, что ключевым направлением исследований станет не столько поиск идеального соответствия, сколько разработка механизмов для элегантной деградации в условиях неполного или искаженного переноса знаний.
Неизбежно возникает вопрос о масштабируемости. Оптимальный транспорт — вычислительно затрадный процесс. Будущие работы должны сосредоточиться на разработке приближенных методов, позволяющих сохранять эффективность при работе с моделями, исчисляемыми миллиардами параметров. Более того, следует признать, что «низкоресурсные» языки — это не просто вопрос нехватки данных. Это вопрос разнообразия лингвистических структур, которые могут потребовать принципиально иных методов представления знаний. Мониторинг — это не обнаружение проблем, а способ бояться осознанно. Необходимо разработать инструменты для непрерывного отслеживания и адаптации моделей к меняющимся условиям и новым данным.
В конечном счете, истинный прогресс будет достигнут не за счет создания все более сложных алгоритмов, а за счет переосмысления самой парадигмы разработки систем. Необходимо признать, что архитектура — это не чертеж, а живой организм, который постоянно эволюционирует. Истинная устойчивость — это не способность избежать ошибок, а способность извлечь из них уроки. Каждый инцидент — это не ошибка, а момент истины.
Оригинал статьи: https://arxiv.org/pdf/2602.05495.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Недвижимость и авиа: что ждет потребителей в России? Анализ рынка и новые маршруты (28.03.2026 19:32)
- Будущее FET: прогноз цен на криптовалюту FET
- АЛРОСА акции прогноз. Цена ALRS
- Российский рынок: Снижение производства, стабильный банковский сектор и ускорение инфляции (26.03.2026 01:32)
- Будущее SKY: прогноз цен на криптовалюту SKY
- Супернус: Продажа Акций и Нервные Тики
- Будущее KAS: прогноз цен на криптовалюту KAS
- Инвестиционный обзор и ключевые инвестиционные идеи воскресенье, 22 марта 2026 9:26
- СириусXM: Пыль дорог и звон монет
2026-02-08 16:52