Автор: Денис Аветисян
Новое исследование показывает, что хотя предварительно обученные табличные модели демонстрируют впечатляющие результаты сразу после установки, тонкая настройка может принести ощутимую пользу в зависимости от архитектуры и данных.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал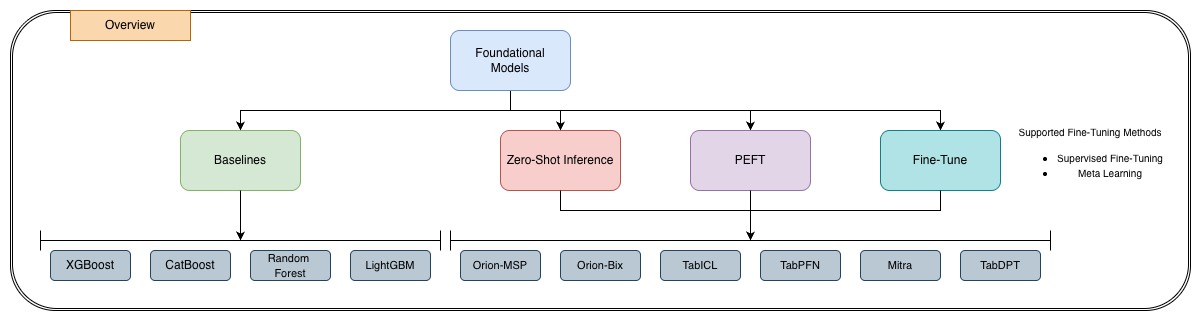
Оценка преимуществ тонкой настройки, калибровки и обеспечения справедливости при использовании табличных фундаментальных моделей.
Несмотря на впечатляющие возможности обучения в условиях малого количества данных, демонстрируемые табличными фундаментальными моделями, вопрос об эффективности их тонкой настройки остается открытым. В работе ‘Exploring Fine-Tuning for Tabular Foundation Models’ представлено первое всестороннее исследование тонкой настройки этих моделей на таких бенчмарках, как TALENT, OpenML-CC18 и TabZilla. Полученные результаты показывают, что выигрыш от тонкой настройки сильно зависит от архитектуры модели и характеристик данных, при этом важно учитывать калибровку и справедливость. Какие стратегии тонкой настройки позволят максимально раскрыть потенциал табличных фундаментальных моделей и обеспечить надежные результаты в реальных приложениях?
Разоблачая ограничения: Новый взгляд на табличные данные
Традиционные методы машинного обучения часто демонстрируют ограниченную способность к обобщению при работе с новыми, ранее не встречавшимися табличными данными. Это связано с тем, что модели, обученные на конкретном наборе данных, испытывают трудности при адаптации к изменениям в структуре или распределении признаков. В результате, для каждого нового набора данных требуется трудоемкая и затратная переподготовка модели, что существенно ограничивает их применимость в реальных условиях, где данные постоянно меняются и эволюционируют. Неспособность к эффективному обобщению приводит к снижению точности и надежности прогнозов, особенно в задачах, требующих адаптации к разнообразным и динамичным табличным данным, что создает значительные препятствия для широкого внедрения машинного обучения в различные сферы применения.
Табулярные фундаментальные модели (TФM) представляют собой принципиально новый подход к работе с табличными данными, отказываясь от традиционных методов машинного обучения, требующих адаптации под каждую конкретную задачу. Вместо этого, TФM предварительно обучаются на огромных объемах разнообразных табличных данных, что позволяет им приобретать общие знания и навыки, применимые к широкому спектру задач. Этот процесс, известный как предварительное обучение, позволяет моделям демонстрировать возможности обучения в контексте и нулевого обучения — то есть, решать новые задачи, используя лишь несколько примеров или вообще без них. Благодаря этому, TФM способны быстро адаптироваться к новым, ранее невиданным наборам данных, значительно превосходя традиционные методы в задачах обобщения и обеспечивая повышенную гибкость и эффективность анализа табличной информации.
Табулярные фундаментальные модели (TFM) открывают новые горизонты в анализе данных, демонстрируя значительное повышение производительности и адаптивности к разнообразным типам табличных данных. Недавние исследования показывают, что эти модели способны к выполнению задач без дополнительной настройки — в режиме «нулевого обучения» — и зачастую достигают сопоставимой, а порой и превосходящей точности по сравнению с традиционными моделями, требующими длительной и ресурсоемкой тонкой настройки под конкретный набор данных. Такая способность к обобщению позволяет применять TFM в широком спектре областей — от финансового прогнозирования и медицинского анализа до логистики и маркетинга — значительно упрощая процесс внедрения и снижая затраты на адаптацию к новым задачам и данным.
Калибровка предсказаний: Точность как основа доверия
Хорошо откалиброванная модель выдает вероятности, точно отражающие реальную частоту наступления событий, что критически важно для принятия обоснованных решений. Это означает, что если модель предсказывает вероятность 70% для определенного исхода, то этот исход должен действительно происходить примерно в 70% случаев в долгосрочной перспективе. Отсутствие калибровки приводит к неверной оценке рисков и неоптимальным стратегиям, поскольку предсказанные вероятности не соответствуют фактическим наблюдениям. В контексте машинного обучения, калибровка особенно важна для систем, где решения принимаются на основе вероятностных прогнозов, например, в медицинских диагностических системах или финансовых моделях.
Для количественной оценки калибровки моделей используются различные метрики, позволяющие определить, насколько точно предсказанные вероятности соответствуют фактической частоте наступления событий. Ошибка ожидаемой калибровки (Expected Calibration Error, ECE) вычисляет среднюю разницу между предсказанной уверенностью и фактической точностью для различных интервалов уверенности. Максимальная ошибка калибровки (Maximum Calibration Error, MCE) определяет максимальную расходимость между предсказанной и фактической вероятностью в любом интервале. Brier Score представляет собой среднюю квадратичную ошибку между предсказанными вероятностями и фактическими исходами (0 или 1), предоставляя единую меру точности вероятностных прогнозов. Низкие значения этих метрик указывают на хорошую калибровку модели.
Недавний анализ показывает, что модели-трансформеры, работающие в режиме zero-shot, а именно OrionMSP и TabPFN, демонстрируют наименьшие значения метрики Expected Calibration Error (ECE). При этом, процедура Supervised Fine-Tuning (SFT), направленная на улучшение производительности, зачастую приводит к существенному ухудшению калибровки для большинства трансформеров. Это указывает на то, что SFT может приводить к переоценке или недооценке вероятностей, что снижает надежность предсказаний модели, несмотря на повышение ее общей точности. ECE = \frac{1}{N} \sum_{i=1}^{N} |p_i - a_i|, где p_i — предсказанная вероятность, а a_i — фактическая частота события.
Справедливость в данных: Преодоление предвзятости
Систематические отклонения в прогнозах моделей машинного обучения могут приводить к увековечиванию и усилению существующих социальных неравенств. Это обусловлено тем, что модели, обученные на данных, отражающих исторические предубеждения и дискриминацию, склонны воспроизводить эти паттерны в своих предсказаниях. В результате, определенные группы населения могут систематически подвергаться неблагоприятному обращению в таких областях, как кредитование, найм, правосудие и доступ к социальным услугам. В связи с этим, необходима проактивная оценка справедливости моделей на предмет выявления и смягчения подобных предвзятостей, что является критически важным для обеспечения равных возможностей и предотвращения дискриминации.
Для количественной оценки дисбаланса в предсказаниях различных групп используются метрики, такие как разность статистического паритета (Statistical Parity Difference), разность равных возможностей (Equal Opportunity Difference) и разность уравненных шансов (Equalized Odds Difference). Разность статистического паритета измеряет разницу в доле положительных предсказаний между защищенной и незащищенной группами. Разность равных возможностей фокусируется на разнице в частоте истинно положительных результатов, а разность уравненных шансов учитывает как истинно положительные, так и ложно положительные результаты, обеспечивая более полное сравнение предсказаний между группами. Все три метрики позволяют численно определить степень предвзятости модели и оценить необходимость применения методов смягчения.
Анализ показал, что модель Mitra демонстрирует наименьшую разницу в статистическом паритете (SPD), однако достижение этой справедливости сопровождается существенным снижением общей предсказательной способности. Это указывает на компромисс между обеспечением равных результатов для разных групп и поддержанием высокой точности модели. В частности, оптимизация для минимизации SPD привела к заметному ухудшению других метрик производительности, подтверждая, что снижение дисбаланса в предсказаниях может потребовать жертв в плане общей эффективности модели.
Архитектурные инновации и стратегии тонкой настройки
Модели TabPFN, TabICL, OrionMSP, TabDPT и Mitra представляют собой инновационные архитектуры для табличных моделей машинного обучения (TFM). Эти модели отличаются от традиционных подходов, предлагая улучшенные методы представления данных и обобщения. TabPFN использует перцептрон с многослойной структурой для эффективной обработки широких наборов признаков. TabICL применяет идеи обучения с контрастом для повышения качества представлений. OrionMSP и TabDPT используют различные стратегии для улучшения устойчивости и обобщающей способности моделей. Mitra объединяет несколько методов для создания комплексной и эффективной архитектуры TFM. Все эти модели направлены на улучшение способности модели извлекать значимые признаки из табличных данных и успешно применять их к новым, ранее не встречавшимся данным.
Эффективные стратегии тонкой настройки, включающие Parameter Efficient Fine-Tuning, Low-Rank Adaptation, Supervised Fine-Tuning и Meta-Learning, позволяют оптимизировать производительность моделей на последующих задачах. Наблюдается, что наибольший эффект от применения этих стратегий достигается на среднеразмерных наборах данных, содержащих от 1000 до 10000 примеров. Применение данных методов позволяет добиться значительного улучшения метрик качества по сравнению с использованием моделей “из коробки” и, в некоторых случаях, превосходит результаты, полученные при использовании более ресурсоемких методов полной перенастройки параметров.
Модель TabPFN демонстрирует повышенную эффективность при работе с наборами данных, содержащими большое количество признаков (более 100). В то время как при обработке небольших наборов данных (менее 1000 образцов) подходы, основанные на обучении без учителя (zero-shot learning), зачастую превосходят методы, требующие тонкой настройки (fine-tuning). Это связано со способностью TabPFN эффективно обрабатывать высокоразмерные пространства признаков, в то время как тонкая настройка требует достаточного количества данных для избежания переобучения при небольшом размере выборки.
Валидация и перспективы развития
Для обеспечения объективной оценки производительности трансформаторных моделей (TFMs) применяются специализированные эталонные наборы данных, такие как TALENT, OpenML-CC18 и TabZilla. Эти наборы данных представляют собой тщательно отобранные и размеченные коллекции табличных данных, предназначенные для тестирования моделей в различных сценариях и выявления их сильных и слабых сторон. Использование стандартизированных бенчмарков позволяет исследователям сравнивать различные архитектуры TFMs и алгоритмы обучения, обеспечивая прозрачность и воспроизводимость результатов. Строгая оценка на этих наборах данных не только демонстрирует текущий уровень развития технологии, но и служит отправной точкой для дальнейших улучшений и разработки более эффективных и надежных моделей машинного обучения.
Современные исследования в области трансформеров машинного обучения (TFMs) активно направлены на преодоление ограничений, связанных с масштабируемостью и вычислительными затратами. Ученые стремятся разработать более эффективные алгоритмы и архитектуры, позволяющие обучать и применять модели на больших объемах данных без чрезмерного потребления ресурсов. Параллельно ведется работа над повышением устойчивости этих моделей к намеренным искажениям данных — так называемым «атакам противника», которые могут привести к ошибочным прогнозам. Успешное решение этих задач позволит значительно расширить область применения TFMs, сделав их доступными для более широкого круга пользователей и задач, включая ресурсоограниченные устройства и критически важные системы.
Недавние исследования показывают, что эффективность дообучения трансферных моделей (TFMs) существенно варьируется в зависимости от конкретной архитектуры модели и характеристик используемого набора данных. В ряде случаев, модели, применяемые “из коробки” — без дополнительной адаптации к целевой задаче — демонстрируют сопоставимую или даже превосходящую производительность по сравнению с дообученными аналогами. Это указывает на то, что универсальный подход к адаптации трансферных моделей может быть неоптимальным, и для достижения наилучших результатов требуется тщательный подбор стратегии адаптации, учитывающий специфику как модели, так и данных.
Исследование демонстрирует, что хотя табличные фундаментальные модели и показывают достойные результаты в условиях zero-shot инференса, тонкая настройка открывает возможности для селективного улучшения производительности, зависящего от архитектуры модели и характеристик набора данных. Этот процесс напоминает попытку взломать систему, чтобы понять её внутреннюю логику. Как однажды заметил Эдсгер Дейкстра: «Программирование — это не столько о создании программ, сколько о решении проблем». В данном контексте, тонкая настройка — это и есть метод решения проблемы адаптации фундаментальной модели к конкретным условиям, а калибровка и обеспечение справедливости — проверка надёжности и безопасности полученного решения, подтверждающие, что система действительно работает, а не просто имитирует активность.
Что дальше?
Очевидно, что тонкая настройка табличных фундаментальных моделей — это не панацея, а скорее признание их изначальной неидеальности. Улучшение показателей в условиях zero-shot обучения впечатляет, однако избирательность преимуществ от тонкой настройки указывает на необходимость более глубокого понимания архитектурных особенностей и специфики данных. Каждый «патч» — это философское признание того, что универсального решения не существует, а оптимизация под конкретную задачу — неизбежная реальность.
Попытки калибровки и обеспечения справедливости, безусловно, важны, но они лишь констатируют, что «умные» модели могут унаследовать и усилить предвзятости, заложенные в данных. Вопрос не в том, чтобы «исправить» модель, а в том, чтобы осознать её ограничения и понимать, какие искажения она может создавать. Мета-обучение, возможно, откроет путь к более адаптивным моделям, но и оно не избавит от необходимости критически оценивать результаты.
В конечном счете, лучший «хак» — это осознание того, как всё работает. Изучение табличных фундаментальных моделей — это реверс-инжиниринг реальности, и каждый новый слой понимания открывает новые возможности — и новые проблемы. В этом бесконечном цикле и заключается истинная ценность исследования.
Оригинал статьи: https://arxiv.org/pdf/2601.09654.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Капитал Б&Т и его душа в AESI
- Почему акции Pool Corp могут стать привлекательным выбором этим летом
- Квантовые Химеры: Три Способа Не Потерять Рубль
- Стоит ли покупать фунты за йены сейчас или подождать?
- Два актива, которые взорвут финансовый Лас-Вегас к 2026
- МКБ акции прогноз. Цена CBOM
- Один потрясающий рост акций, упавший на 75%, чтобы купить во время падения в июле
- Будущее ONDO: прогноз цен на криптовалюту ONDO
- Делимобиль акции прогноз. Цена DELI
- Российский рынок: Рост на фоне Ближнего Востока и сырьевая уверенность на 100 лет (28.02.2026 10:32)
2026-01-15 18:49