Автор: Денис Аветисян
Новое исследование показывает, что анализ текста песен с помощью современных моделей машинного обучения позволяет значительно точнее предсказывать успех музыкальных композиций.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал
Использование векторных представлений текста песен, полученных с помощью больших языковых моделей, в сочетании с многомодальной архитектурой глубокого обучения, повышает точность предсказания популярности музыки.
Несмотря на значительный прогресс в анализе музыкальных данных, роль текстового содержания песен в предсказании их популярности оставалась недостаточно изученной. В статье ‘Lyrics Matter: Exploiting the Power of Learnt Representations for Music Popularity Prediction’ предлагается автоматизированный подход, использующий возможности больших языковых моделей для извлечения многомерных векторных представлений лирики, которые затем интегрируются в мультимодальную архитектуру. Полученные результаты демонстрируют, что учет семантической информации, заключенной в текстах песен, существенно повышает точность прогнозирования популярности треков, превосходя существующие методы на 9% и 20% по метрикам MAE и MSE соответственно. Возможно ли дальнейшее улучшение моделей предсказания популярности музыки за счет более глубокого анализа лирического содержания и комбинации с другими модальностями данных?
За пределами Звука: Вызов Прогнозирования Музыкальной Популярности
Прогнозирование популярности музыкальных композиций представляет собой сложную задачу, традиционно опирающуюся на анализ как аудиохарактеристик, так и метаданных, однако существующие методы зачастую демонстрируют ограниченную точность. Несмотря на использование таких параметров, как темп, тональность и жанр, а также информации об исполнителе и дате выпуска, предсказать, станет ли песня хитом, остается непросто. Это связано с тем, что популярность формируется под влиянием множества субъективных факторов, которые сложно количественно оценить и учесть в алгоритмах. В результате, даже самые передовые модели часто не способны достоверно предсказать успех музыкальной композиции, что подчеркивает необходимость разработки новых, более эффективных подходов к решению этой задачи.
Существующие модели прогнозирования популярности музыки часто испытывают трудности при одновременной обработке аудиохарактеристик и метаданных, что приводит к ограниченной точности предсказаний. Проблема заключается в том, что эти модели, как правило, рассматривают аудио и метаданные как отдельные источники информации, не учитывая их взаимосвязь и, особенно, игнорируя семантическое значение текстов песен. В то время как акустические характеристики описывают звучание, а метаданные — общую информацию о композиции, именно лирическое содержание часто формирует эмоциональную связь со слушателем и влияет на восприятие музыки. Отсутствие интеграции анализа текста в существующие алгоритмы является значительным упущением, поскольку именно слова и повествование могут быть ключевыми факторами, определяющими успех песни у аудитории и ее вирусный потенциал.
Существующий разрыв в точности прогнозирования популярности музыки указывает на необходимость комплексного подхода, использующего семантическую информацию, заключенную в текстах песен. Традиционные модели часто сосредотачиваются на аудиохарактеристиках и метаданных, упуская из виду влияние лирического содержания на восприятие и привлекательность композиции. Исследования показывают, что именно смысловая нагрузка, темы и эмоциональная окраска текста могут существенно влиять на успех песни у слушателей, формируя более глубокую связь и вызывая отклик. Поэтому, для более точного прогнозирования, необходимо учитывать не только то, как звучит музыка, но и то, о чем она поет, интегрируя лингвистический анализ в существующие алгоритмы и модели.
Успешное прогнозирование популярности музыкальных композиций требует понимания вклада текста песни в её привлекательность, что выходит за рамки анализа исключительно акустических характеристик или описательных метаданных. Исследования показывают, что лирическое содержание способно формировать эмоциональную связь со слушателем, влияя на восприятие и запоминаемость композиции. Семантический анализ текстов песен позволяет выявить темы, настроения и повествовательные структуры, резонирующие с аудиторией. В то время как музыкальные характеристики определяют общее звучание, именно лирика часто становится ключевым фактором, определяющим, насколько глубоко песня отзывается в сердцах слушателей и способствует её виральности. Учет лирического аспекта, таким образом, становится необходимым условием для создания более точных и надежных моделей прогнозирования популярности в музыкальной индустрии.
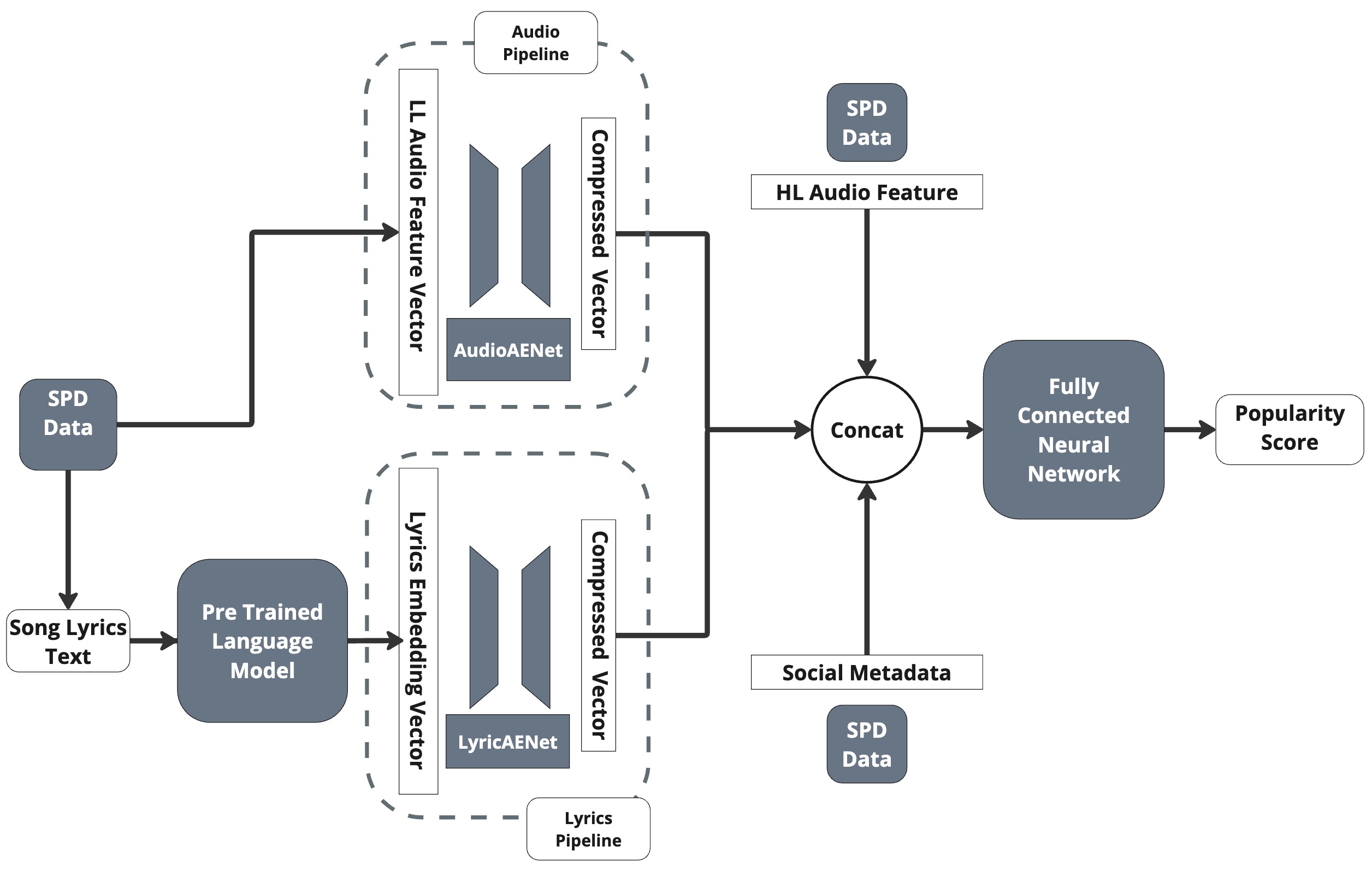
HitMusicLyricNet: Интеграция Текстов в Процесс Прогнозирования
HitMusicLyricNet представляет собой многомодальную архитектуру глубокого обучения, разработанную для интеграции информации из нескольких источников. В отличие от традиционных моделей, ориентированных исключительно на аудиосигналы и метаданные, HitMusicLyricNet явно включает в процесс обучения извлеченные признаки из текстов песен. Это достигается путем обработки лирического содержания и представления его в виде векторных эмбеддингов, которые затем объединяются с аудио- и метаданными для повышения точности предсказаний. Использование текстов песен позволяет модели учитывать семантическое содержание композиции, что может быть полезно для задач, требующих понимания музыкального контекста и предпочтений слушателей.
В архитектуре HitMusicLyricNet для обработки аудио и текста песен используются отдельные автоэнкодеры — AudioAENet и LyricsAENet. AudioAENet предназначен для сжатия и извлечения ключевой информации из аудиосигнала, уменьшая его размерность и сохраняя при этом наиболее значимые характеристики. LyricsAENet выполняет аналогичную функцию для текста песен, преобразуя его в компактное векторное представление. Применение отдельных автоэнкодеров позволяет эффективно обрабатывать данные различных модальностей, уменьшая вычислительную нагрузку и выделяя наиболее релевантные признаки для последующего анализа и прогнозирования.
Для создания насыщенных векторных представлений текстов песен LyricsAENet использует современные языковые модели, такие как BERT, Llama 3 и OpenAI Text Embeddings. Эти модели предварительно обучены на огромных текстовых корпусах, что позволяет им эффективно захватывать семантическое значение и контекст лирического содержания. В процессе работы LyricsAENet преобразует текст песни в векторное представление фиксированной длины, отражающее его смысл и структуру. Использование различных моделей позволяет оценить и выбрать наиболее подходящий метод для конкретной задачи и набора данных, а также повысить общую производительность системы за счет комбинирования сильных сторон каждой модели.
Ключевым компонентом архитектуры является MusicFuseNet, модуль, предназначенный для интеллектуального объединения сжатых представлений, полученных из аудио ($AudioAENet$) и текстовых ($LyricsAENet$) данных. MusicFuseNet обрабатывает выходные векторы обоих автоэнкодеров, применяя взвешенную сумму или более сложные механизмы внимания для создания единого, унифицированного вектора признаков. Этот вектор служит входными данными для последующих слоев предсказания, обеспечивая модели возможность учитывать как аудио-, так и лирическое содержание композиции при решении задач, таких как предсказание популярности или жанра.

Раскрывая Лирические Инсайты: Производительность и Интерпретируемость Модели
Модель HitMusicLyricNet показала улучшенные результаты в предсказании популярности музыкальных композиций по сравнению с базовыми моделями, такими как HitMusicNet. Измерение точности проводилось с использованием средней абсолютной ошибки (MAE), и HitMusicLyricNet достигла снижения этого показателя на 9% по сравнению с базовыми моделями. Это свидетельствует о том, что интеграция лирических данных в процесс предсказания значительно повышает его эффективность и позволяет получать более точные прогнозы относительно потенциальной популярности музыкальных треков.
В ходе экспериментов было установлено, что включение лирической информации в модель предсказания популярности музыки стабильно повышает точность прогнозов. Модель HitMusicLyricNet, использующая как аудиоданные, метаданные, так и текст песен, демонстрирует более низкую среднюю абсолютную ошибку (MAE) по сравнению с моделями, не учитывающими лирику. В частности, удаление лирической составляющей привело к увеличению MAE на 10.4% (до 0.0852), что подтверждает значимость текстового содержания песен для оценки потенциальной популярности музыкальных треков и обосновывает гипотезу о влиянии лирики на восприятие музыки.
Удаление текстовой информации из лирики привело к увеличению средней абсолютной ошибки (MAE) до 0.0852, что на 10.4% превышает показатель полной модели. Данный результат подтверждает значимость использования эмбеддингов лирики для повышения точности предсказания популярности музыкальных треков. Увеличение MAE демонстрирует, что лирика содержит важную информацию, влияющую на восприятие музыки аудиторией, и ее исключение негативно сказывается на способности модели к прогнозированию.
В ходе оценки производительности модели HitMusicLyricNet, средняя абсолютная ошибка (MAE) составила $0.07720$. При использовании только аудио- и метаданных, значение MAE значительно возросло до $0.1196$. Данное сравнение демонстрирует, что объединение различных модальностей данных — лирики, аудио и метаданных — существенно повышает точность прогнозирования популярности музыки, указывая на взаимодополняющий характер этих данных в моделировании музыкальных трендов.
Для анализа механизмов, определяющих прогнозы модели, были применены методы интерпретируемости машинного обучения, такие как SHAP (SHapley Additive exPlanations) и LIME (Local Interpretable Model-agnostic Explanations). SHAP Values позволяют оценить вклад каждой характеристики (в данном случае, признаков, полученных из лирики, аудио и метаданных) в конкретный прогноз, вычисляя ее средний маргинальный вклад в коалицию признаков. LIME, в свою очередь, аппроксимирует поведение сложной модели локально, вокруг конкретной точки данных, создавая интерпретируемую модель (например, линейную регрессию), которая объясняет прогноз для данного примера. Комбинированное использование этих методов позволяет выявить наиболее значимые факторы, влияющие на предсказываемую популярность музыкальных композиций, и понять, как модель интерпретирует данные.
Анализ с использованием методов интерпретируемого машинного обучения, таких как SHAP Values и LIME, позволил выявить конкретные лирические темы и стилистические особенности, оказывающие значительное влияние на прогнозируемую популярность музыкальных композиций. В частности, обнаружено, что частота упоминания определенных концепций, таких как любовь, расставание или вечеринки, коррелирует с предсказываемым успехом. Кроме того, выявлены ключевые стилистические элементы, включая использование определенных метафор, рифмовку и структуру предложений, которые также вносят вклад в оценку популярности. Эти результаты предоставляют ценные сведения о текущих тенденциях в музыкальной индустрии и могут быть использованы для анализа изменений в предпочтениях аудитории.

За Пределами Прогнозирования: Влияние и Перспективы Развития
Успех HitMusicLyricNet демонстрирует значительный потенциал мультимодального обучения в понимании и прогнозировании сложных явлений, выходящих далеко за рамки музыкальной индустрии. Способность модели эффективно объединять и анализировать различные типы данных — текст песен, музыкальные характеристики и другие факторы — указывает на универсальность данного подхода. Подобные системы могут быть адаптированы для анализа тенденций в других областях, таких как финансовые рынки, социальные сети или даже научные исследования, где выявление закономерностей в разнородных данных имеет решающее значение. Перспективы использования мультимодального обучения простираются от повышения точности прогнозирования до раскрытия скрытых взаимосвязей, что делает его ценным инструментом для решения широкого круга задач, требующих комплексного анализа данных.
Использование методов объяснимого искусственного интеллекта (XAI) позволяет глубже понять факторы, определяющие успех музыкального произведения. Анализ, проведенный с помощью этих методов, выявляет не только корреляции между лирикой, музыкальными характеристиками и популярностью, но и причинно-следственные связи. Это открывает возможности для более эффективной разработки стратегий продвижения артистов и музыкальных произведений. Например, выявление ключевых лингвистических паттернов, резонирующих с аудиторией, или определение музыкальных элементов, вызывающих наибольший эмоциональный отклик, может быть использовано для создания более привлекательного контента и оптимизации маркетинговых кампаний. Таким образом, XAI становится мощным инструментом для принятия обоснованных решений в музыкальной индустрии, позволяя не просто предсказывать успех, но и активно влиять на него.
Дальнейшие исследования сосредоточены на применении более сложных языковых моделей, способных улавливать тончайшие нюансы текстов песен и связывать их с музыкальными характеристиками. Особое внимание уделяется интеграции контекстуальной информации, такой как история артиста, эволюция его стиля и жанровая принадлежность. Предполагается, что учет этих факторов позволит создать более точные и персонализированные модели, способные не только предсказывать популярность композиций, но и понимать глубинные причины успеха отдельных исполнителей, а также выявлять закономерности в развитии музыкальных трендов. В перспективе, это может привести к созданию интеллектуальных систем, способных предлагать новые, неожиданные, но при этом соответствующие вкусам слушателя музыкальные открытия.
Данное исследование открывает новые перспективы для создания систем музыкальных рекомендаций и поиска, отличающихся большей точностью и глубиной понимания предпочтений слушателя. Вместо простых алгоритмов, основанных на коллаборативной фильтрации или базовых характеристиках треков, предлагается подход, учитывающий сложные взаимосвязи между текстами песен, музыкальным содержанием и факторами, влияющими на популярность. Это позволяет не просто предлагать похожую музыку, а действительно находить произведения, которые могут заинтересовать конкретного слушателя, основываясь на более полном анализе его вкусов и контекста. В результате, пользователи получают возможность открывать для себя новую музыку, соответствующую их индивидуальным предпочтениям, что значительно улучшает общее впечатление от прослушивания и расширяет музыкальный горизонт.

Исследование демонстрирует, что извлечение значимых признаков из текста песен, посредством больших языковых моделей, существенно повышает точность предсказания популярности музыкальных композиций. Этот подход, основанный на комбинировании различных модальностей данных, подчеркивает важность долгосрочной устойчивости систем представления информации. Как однажды заметил Джон Маккарти: «Всякое вычисление есть попытка отсрочить неизбежное». В контексте данной работы, это означает, что эффективное представление лирического содержания позволяет «отсрочить неизбежное» — неспособность предсказать успех музыкального произведения, обеспечивая более надежную и долговечную модель оценки. Акцент на извлеченных признаках и их устойчивости со временем, резонирует с философией, где системы оцениваются по их способности адаптироваться и сохранять функциональность в изменяющейся среде.
Что дальше?
Каждый коммит — запись в летописи, а каждая версия — глава. Данная работа, демонстрируя эффективность извлечения смысловых векторов из текста песен для предсказания популярности музыки, неизбежно ставит вопрос о границах применимости подобных моделей. Успех здесь, безусловно, обусловлен возможностью захвата культурных и эмоциональных нюансов, заложенных в лирике. Однако, следует признать, что популярность — категория текучая, зависящая от контекста и подверженная влиянию эфемерных трендов. Предсказание, следовательно, обречено на несовершенство, а задержка исправлений — это налог на амбиции.
Очевидным направлением для дальнейших исследований представляется расширение мультимодального подхода. Необходимо учитывать не только текст, но и акустические характеристики композиций, визуальное оформление, а также социальные факторы, определяющие распространение музыки в цифровой среде. Игнорирование этих аспектов — это всё равно что пытаться понять симфонию, слушая лишь партию скрипки.
В конечном итоге, задача не в том, чтобы создать идеальный предсказатель популярности, а в том, чтобы глубже понять механизмы, определяющие восприятие музыки. Все системы стареют — вопрос лишь в том, делают ли они это достойно. Время — не метрика, а среда, в которой существуют системы, и каждое новое поколение музыкантов, как и алгоритмов, вносит свои коррективы в эту сложную и увлекательную эволюцию.
Оригинал статьи: https://arxiv.org/pdf/2512.05508.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Серебро прогноз
- Ethereum: Новый ATH активности сети – сигнал к покупке? Анализ рынка и перспективные стратегии (10.04.2026 18:15)
- РУСАЛ акции прогноз. Цена RUAL
- Российский рынок: Нефть, дивиденды и геополитика. Что ждет инвесторов? (23.03.2026 18:32)
- Прогноз нефти
- Мечел акции прогноз. Цена MTLR
- Будущее лайткоина: прогноз цен на криптовалюту LTC
- АЛРОСА акции прогноз. Цена ALRS
- Газпром акции прогноз. Цена GAZP
2025-12-09 06:14