Автор: Денис Аветисян
В статье представлена методика YaPO, позволяющая более гибко настраивать большие языковые модели с учетом культурных особенностей и предпочтений пользователей.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал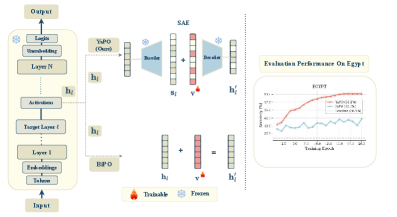
Предложен метод обучения разреженных векторов управления активациями для повышения эффективности доменной адаптации и улучшения культурной согласованности больших языковых моделей.
Несмотря на успехи в управлении большими языковыми моделями (LLM) посредством интервенций в активации, существующие подходы часто сталкиваются с проблемой смешения латентных факторов, ограничивая точность и стабильность в задачах, требующих тонкой настройки, таких как культурная адаптация. В данной работе представлена методика ‘YaPO: Learnable Sparse Activation Steering Vectors for Domain Adaptation’, которая обучает разреженные векторы управления в латентном пространстве разреженного автоэнкодера, обеспечивая более четкое и интерпретируемое представление. Эксперименты демонстрируют, что YaPO превосходит плотные векторы управления по скорости сходимости, производительности и стабильности обучения, а также сохраняет общие знания, не ухудшая результаты на MMLU. Возможно ли, что YaPO станет универсальным рецептом для эффективной и стабильной адаптации LLM к различным доменам и задачам контроля?
Культурные нюансы и вызовы для искусственного интеллекта
Современные модели искусственного интеллекта часто демонстрируют трудности при обработке тонких культурных различий, что проявляется в значительном разрыве между явной и неявной локализацией. Этот феномен, известный как «Разрыв неявной и явной локализации», возникает, когда модели успешно справляются с прямыми указаниями, но терпят неудачу в ситуациях, где понимание требует учета невысказанных культурных норм и контекста. Например, модель может правильно перевести фразу, но не уловить ироничный подтекст, понятный только представителям определенной культуры. Такая неспособность к адаптации к неявным культурным сигналам ограничивает эффективность ИИ в задачах, требующих глубокого понимания человеческого общения и социального взаимодействия, и подчеркивает необходимость разработки методов, способных учитывать и воспроизводить нюансы культурного контекста.
Существующий разрыв в локализации, проявляющийся в неспособности искусственного интеллекта учитывать тонкие культурные различия, обусловлен недостаточной адаптивностью моделей к контексту. Современные алгоритмы, как правило, оперируют явной информацией, упуская из виду невысказанные предположения и общекультурные знания, которые необходимы для правильной интерпретации. Попытки преодолеть эту проблему, ограничивающиеся корректировкой входных и выходных данных, оказываются недостаточно эффективными, поскольку не затрагивают глубинные механизмы рассуждений модели. В результате, даже незначительные культурные нюансы могут приводить к существенным ошибкам в понимании и генерации информации, подчеркивая необходимость разработки принципиально новых подходов к обучению и адаптации искусственного интеллекта.
Для преодоления трудностей, связанных с культурной нюансировкой в искусственном интеллекте, необходимы методы, позволяющие осуществлять детальное управление поведением модели. Простые корректировки входных и выходных данных оказываются недостаточными, поскольку не затрагивают глубинные механизмы рассуждений. Вместо этого, требуется разработка подходов, способных тонко настраивать внутренние параметры модели, учитывая контекст и культурные особенности. Это предполагает, что модель не просто «узнает» факты, а способна адаптировать свою логику и интерпретацию информации, чтобы избежать неверных выводов или оскорбительных интерпретаций, обусловленных культурными различиями. Такой подход требует перехода от поверхностных изменений к глубокой модификации процессов принятия решений внутри искусственного интеллекта.
YaPO: Управление по предпочтениям без эталонных данных
Метод YaPO представляет собой подход к адаптации поведения модели, не требующий использования эталонных данных (reference-free). Он заключается в обучении “Векторов Управления” (Steering Vectors) непосредственно в пространстве активаций нейронной сети. В отличие от методов, требующих сравнения с заранее заданными образцами, YaPO определяет векторы, которые позволяют корректировать выходные данные модели, основываясь на внутренних представлениях, формируемых в процессе обработки информации. Эти векторы оперируют непосредственно в пространстве активаций, что позволяет более точно и эффективно управлять поведением модели без необходимости явного определения желаемых результатов.
Метод YaPO использует данные о предпочтениях — примеры желаемых и нежелаемых ответов модели — для обучения векторов управления. Эти данные позволяют модели адаптировать свое поведение, последовательно уменьшая разрыв между явными и неявными аспектами локализации в задачах культурной адаптации. В ходе обучения, модель сопоставляет желаемые ответы с соответствующими векторами, и наоборот, что позволяет ей генерировать ответы, более соответствующие заданным культурным нормам и ожиданиям. Стабильное улучшение показателей в бенчмарках культурной адаптации подтверждает эффективность подхода, основанного на использовании данных о предпочтениях для обучения векторов управления.
В основе YaPO лежит использование разреженного автокодировщика (Sparse Autoencoder, SAE) для проецирования активаций модели в интерпретируемое латентное пространство. SAE позволяет представить высокоразмерные векторы активаций в виде более компактного и структурированного представления, что облегчает идентификацию и модификацию параметров, влияющих на поведение модели. Проецирование в латентное пространство позволяет добиться более точного управления генерацией ответов, поскольку изменения в этом пространстве оказывают предсказуемое влияние на выходные данные модели, обеспечивая возможность целенаправленной корректировки её поведения.
Использование функции активации ReLU (Rectified Linear Unit) в составе разреженного автоэнкодера (SAE) обеспечивает создание разреженных представлений активаций. Это достигается за счет обнуления отрицательных значений, что приводит к активации лишь небольшого числа нейронов в скрытом слое. Повышенная разреженность способствует более четкой интерпретации латентного пространства, облегчая идентификацию и манипулирование конкретными факторами, влияющими на поведение модели. В результате, процесс управления моделью с помощью векторов управления становится более точным и контролируемым, что позволяет целенаправленно корректировать ответы модели без нежелательных побочных эффектов.
Интерпретируемое управление через разреженные представления
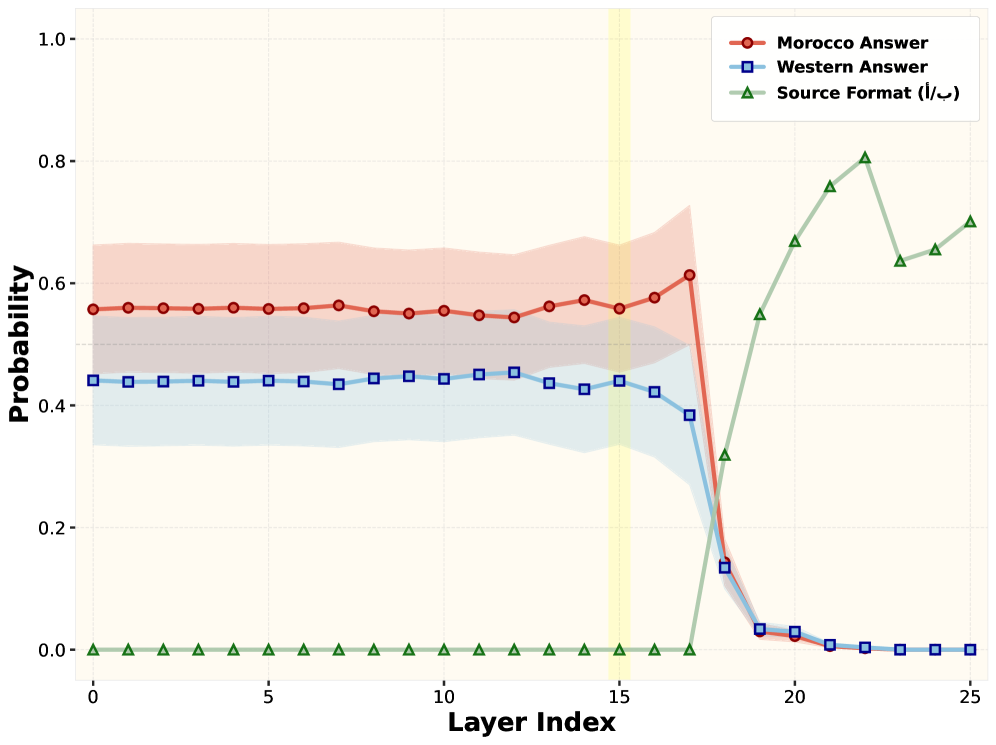
В архитектуре YaPO использование разреженных автоэнкодеров приводит к формированию “моносемантичных признаков”. Это означает, что каждый отдельный признак, полученный в результате работы автоэнкодера, кодирует конкретное и однозначное понятие или смысл. В отличие от плотных представлений, где информация распределена по множеству признаков, моносемантичные признаки обеспечивают более четкую и интерпретируемую связь между признаком и его семантическим значением. Это позволяет более точно определить, какие аспекты входных данных активируют конкретные признаки и, следовательно, как модель формирует свои ответы.
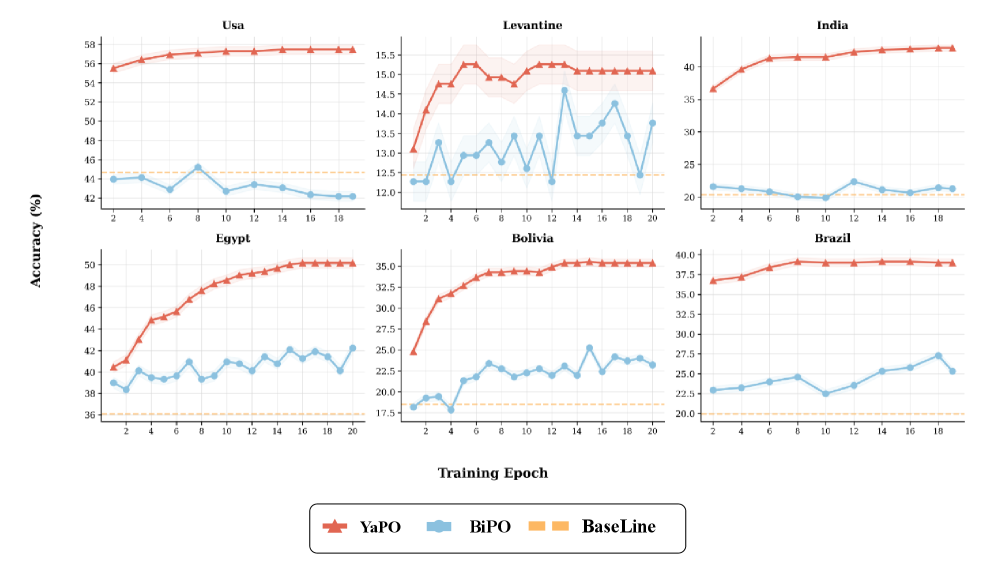
Повышенная интерпретируемость, достигаемая за счет использования разреженных представлений, позволяет детально анализировать процесс адаптации модели к различным запросам. Это, в свою очередь, способствует улучшению «Надежной Культурной Точности» (Robust Cultural Accuracy — RCA) в контексте многоязычных и мультикультурных данных. Анализ активаций отдельных признаков позволяет выявить, какие аспекты представления знаний влияют на конкретные ответы, что критически важно для обеспечения корректного и релевантного поведения модели в различных культурных контекстах и языках. Такой подход позволяет идентифицировать и корректировать потенциальные смещения или предвзятости, обеспечивая более справедливые и адекватные результаты.
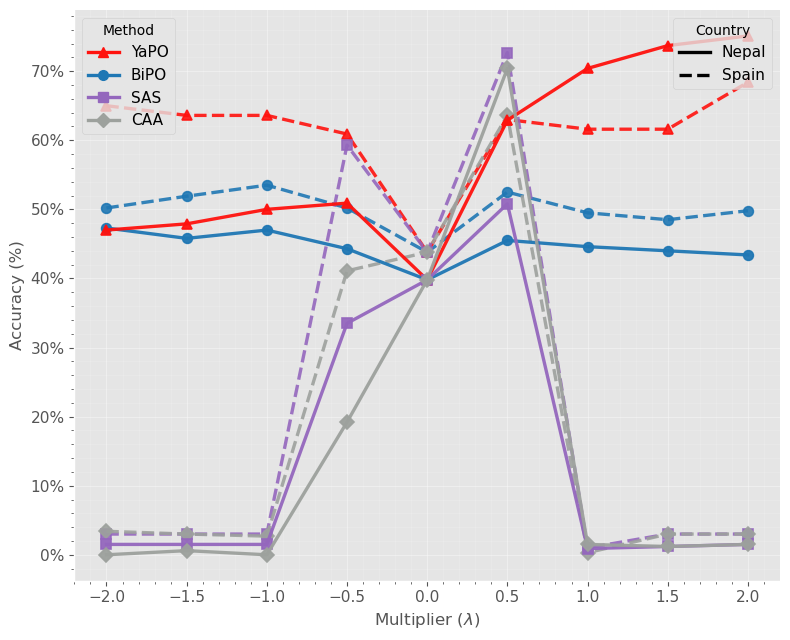
В YaPO, обучение разреженных, оптимизированных на основе предпочтений векторов управления позволяет целенаправленно изменять конкретные аспекты логических рассуждений модели. В отличие от BiPO, использующего плотные векторы, разреженное представление обеспечивает более точное воздействие на отдельные признаки и концепции. Экспериментальные данные демонстрируют, что YaPO достигает сходимости в процессе обучения на порядок быстрее, чем BiPO, что связано с уменьшением размерности пространства поиска и более эффективным градиентным спуском благодаря разреженности векторов управления.
Исследование, представленное в данной работе, акцентирует внимание на важности адаптации больших языковых моделей к культурным особенностям. В этом контексте особенно примечательны слова Тима Бернерса-Ли: «Веб должен быть для всех, и это включает в себя возможность для каждого выражать себя и свои идеи, независимо от языка или культуры». YaPO, предлагая метод обучения разреженных векторов управления для оптимизации предпочтений, стремится к созданию систем, которые не просто функционируют, но и достойно стареют, адаптируясь к меняющимся потребностям пользователей и сохраняя культурную релевантность. Подход, описанный в статье, позволяет рассматривать «технический долг» как своего рода эрозию, требующую постоянного внимания и корректировки для обеспечения долгосрочной устойчивости и гармонии системы во времени.
Куда же дальше?
Представленная работа, демонстрируя возможности управляемого разреженного представления в больших языковых моделях, лишь слегка отодвигает завесу над фундаментальной проблемой: адаптацией к постоянно меняющемуся культурному ландшафту. Оптимизация «предпочтений» — временное решение, ведь предпочтения, как и любые другие системы, подвержены эрозии. Вопрос не в том, чтобы создать модель, идеально отражающую текущий момент, а в том, чтобы обеспечить ей способность к медленному приспособлению, сохраняя при этом внутреннюю устойчивость.
Очевидным направлением для дальнейших исследований представляется изучение не только вектора «управления», но и самой архитектуры разреженности. Каждый уровень абстракции несёт в себе груз прошлого, и попытки «переобучения» лишь усиливают эту инерцию. Потребуется разработка механизмов, позволяющих модели забывать устаревшие паттерны, не теряя при этом общую когнитивную способность. Это задача, требующая не столько вычислительной мощности, сколько глубокого понимания принципов самоорганизации.
И, наконец, необходимо признать, что любая попытка «культурного выравнивания» неизбежно несёт в себе элементы субъективности. Истина не абсолютна, и попытки её навязать машине — это, по сути, воспроизведение тех же самых ошибок, которые человечество совершает на протяжении всей своей истории. Всё стареет — вопрос лишь в том, делает ли это система достойно, сохраняя способность к эволюции, а не к простой адаптации.
Оригинал статьи: https://arxiv.org/pdf/2601.08441.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Нефть, Геополитика и Рубль: Что ждет инвесторов в ближайшую неделю
- HYPE: Почему токен Hyperliquid может взлететь до $150 – анализ доходов, рисков и конкурентов (13.03.2026 21:15)
- Российская экономика: Бюджетное давление, геополитика и новые экспортные возможности (11.03.2026 21:32)
- Газпром акции прогноз. Цена GAZP
- Театр энергетики: акции, которые обещают вечность
- Почему акции ViaSat взлетели в понедельник
- Падение Палантинка: Взгляд трейдера-аристократа
- Почему акции Planet Labs выросли почти на 50% за неделю
- Costco: покупать, продавать или держаться в 2025?
2026-01-20 16:37