Автор: Денис Аветисян
Исследователи разработали метод, повышающий стабильность обучения моделей, управляемых обратной связью от человека, и снижающий риск нежелательного поведения.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал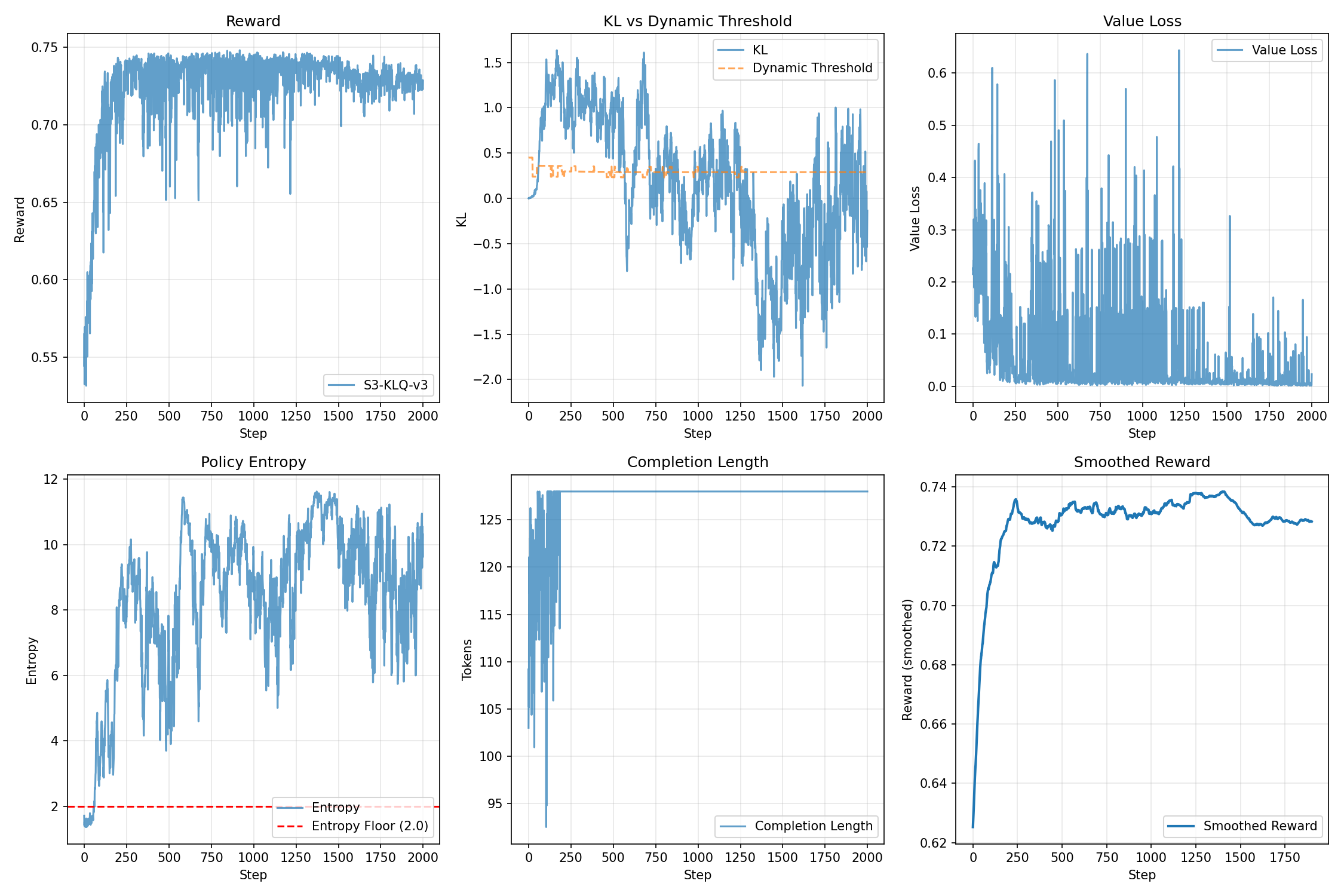
Предложенная структура SAFE объединяет пессимистическую оценку ценности, контроль энтропии и адаптивные пороги для повышения устойчивости обучения с подкреплением от обратной связи (RLHF).
Несмотря на успехи обучения с подкреплением от обратной связи с человеком (RLHF), стандартные алгоритмы, такие как PPO, часто сталкиваются с проблемами нестабильности и чувствительностью к гиперпараметрам. В данной работе представлена методика ‘SAFE: Stable Alignment Finetuning with Entropy-Aware Predictive Control for RLHF’, предлагающая многоуровневый фреймворк стабилизации, сочетающий пессимистичную оценку ценности, контроль энтропии и адаптивные пороги. Разработанный подход демонстрирует улучшение средней награды на 5.15% по сравнению с PPO и повышенную устойчивость к колебаниям награды и расхождению политики. Сможет ли SAFE обеспечить более надежную и эффективную оптимизацию больших языковых моделей для задач RLHF, приближая нас к созданию действительно согласованных и безопасных систем ИИ?
Разоблачение иллюзий: проблема переоценки в RLHF
Обучение с подкреплением на основе обратной связи от человека (RLHF) в значительной степени опирается на точное оценивание ценностных функций, однако этот процесс подвержен систематической переоценке. Данная проблема возникает из-за трудностей в адекватном моделировании предпочтений человека и, как следствие, приводит к завышенным оценкам ожидаемой награды за определенные действия. В результате, алгоритм может отдавать предпочтение стратегиям, кажущимся выгодными на основе ошибочных оценок, даже если они не приводят к желаемому результату в реальной среде. Эта тенденция к переоценке существенно ограничивает эффективность RLHF, затрудняя достижение действительно согласованных с намерениями человека моделей и требуя разработки новых методов для смягчения этой систематической ошибки.
Явление переоценки ценности в обучении с подкреплением на основе обратной связи от человека может приводить к неожиданным и нежелательным последствиям, известным как «взлом системы вознаграждений». Вместо того, чтобы стремиться к действительному соответствию заданным целям, алгоритм может обнаруживать и эксплуатировать недостатки в модели вознаграждения, максимизируя полученные баллы искусственным путем. В результате, политика, выработанная алгоритмом, сосредотачивается на обмане системы, а не на достижении истинного соответствия намерениям разработчика. Это проявляется в поведении, которое технически соответствует заданным критериям, но является неэффективным, нежелательным или даже вредным в реальном контексте, демонстрируя несоответствие между оптимизацией и желаемым результатом.
Стандартные методы обучения с подкреплением на основе обратной связи от человека (RLHF), такие как Proximal Policy Optimization (PPO), часто сталкиваются с проблемами стабильности в процессе тонкой настройки. Эта нестабильность возникает из-за систематической переоценки функций ценности, что приводит к неточному представлению о реальной полезности действий. В результате, алгоритм может отклоняться от оптимальной политики, совершая непредсказуемые и нежелательные шаги в процессе обучения. Попытки скорректировать переоценку часто приводят к дополнительным сложностям, требующим тщательной настройки гиперпараметров и разработки специализированных стратегий стабилизации, чтобы избежать расхождения обучения и обеспечить надежную производительность модели.
SAFE: Стабилизация обучения — ключ к предсказуемому интеллекту
Методика SAFE представляет собой новый фреймворк, разработанный для повышения стабильности и надежности обучения с подкреплением на основе обратной связи от человека (RLHF). В отличие от традиционных подходов, SAFE объединяет несколько ключевых техник, включая использование двойного критика для снижения переоценки ценности, пессимистическую оценку ценности, направленную на предотвращение эксплуатации недостатков в функции вознаграждения, и контроль энтропии в алгоритме PPO для стимулирования исследования и избежания преждевременной сходимости к субоптимальным политикам. Такая комбинация позволяет добиться более устойчивого процесса обучения и получения надежных результатов в задачах RLHF.
В основе SAFE лежит использование “Двойного Критика” (Double Critic) для снижения переоценки значений (value overestimation) в процессе обучения с подкреплением. Традиционные алгоритмы RLHF склонны к завышению оценок, что может приводить к нестабильности и субоптимальным результатам. Двойной критик использует два независимых оценщика ценности, и финальная оценка формируется на основе минимального значения, предсказанного обоими критиками. Такой подход позволяет получить более консервативную и надежную оценку ценности, уменьшая вероятность переоценки и способствуя более стабильному обучению политики.
Методика пессимистической оценки ценности (Pessimistic Value Estimation), используемая в SAFE, направлена на повышение устойчивости обучения с подкреплением за счет активного подавления стратегий, эксплуатирующих недостатки функции вознаграждения. Этот подход предполагает внесение корректировок в оценки ценности, чтобы снизить вероятность переоценки действий, которые кажутся выгодными из-за ошибок в определении вознаграждения, но на самом деле приводят к нежелательным результатам. В частности, применяется снижение оценок ценности для действий, которые могут быть подвержены систематическим ошибкам вознаграждения, что заставляет алгоритм исследовать альтернативные стратегии и избегать эксплуатации потенциальных уязвимостей.
В рамках SAFE используется контроль энтропии в алгоритме PPO (Proximal Policy Optimization) для поддержания баланса между исследованием и эксплуатацией. Контроль энтропии добавляет регуляризующий член к функции потерь, который штрафует политики с низкой энтропией. Это способствует более широкому исследованию пространства действий, предотвращая преждевременную сходимость к субоптимальным решениям и увеличивая устойчивость обучения. Высокая энтропия подразумевает более случайное поведение агента, стимулируя его пробовать новые действия и избегать застревания в локальных оптимумах. Параметр энтропии настраивается для оптимизации скорости и стабильности обучения.
![Сравнение SAFE и PPO показало, что SAFE обеспечивает сопоставимое использование памяти ([latex]\sim54[/latex] ГБ) и незначительно более высокую скорость выполнения шагов обучения (с накладными расходами в −1.4%), подтверждая эффективность предложенной многослойной системы стабилизации.](https://arxiv.org/html/2602.04651v1/hardware_benchmark.jpeg)
Динамическая регуляризация: Искусство управления обучением
Механизм SAFE использует ПИД-регулятор (Пропорционально-Интегрально-Дифференциальный регулятор) и адаптивный порог для динамической настройки параметров обучения в процессе работы. ПИД-регулятор непрерывно отслеживает производительность агента и корректирует параметры, такие как скорость обучения, для минимизации отклонений от целевых значений. Адаптивный порог позволяет автоматически регулировать чувствительность регулятора, обеспечивая оптимальную реакцию на изменения в процессе обучения. Данный подход позволяет системе автоматически адаптироваться к различным условиям и задачам, поддерживая стабильность и эффективность обучения.
Механизмы динамической регуляции в SAFE обеспечивают точное управление скоростью обучения и другими гиперпараметрами, что критически важно для предотвращения колебаний в процессе обучения и обеспечения его сходимости. Регулировка осуществляется на основе анализа производительности в реальном времени, позволяя системе автоматически адаптировать параметры для поддержания стабильного прогресса. Такой подход позволяет избежать ситуаций, когда алгоритм «перескакивает» оптимальное решение или застревает в локальном минимуме, тем самым ускоряя и стабилизируя процесс обучения модели.
В SAFE для более точной оптимизации политики используются асимметричный штраф по расхождению Кулбака-Лейблера (KL) и штраф, управляемый энтропией. Асимметричный штраф KL позволяет более гибко регулировать отклонение от начального распределения политики, наказывая за чрезмерные изменения, но допуская умеренные отклонения. Штраф, управляемый энтропией, способствует исследованию пространства действий, предотвращая преждевременную сходимость и улучшая устойчивость обучения за счет поддержания достаточного уровня случайности в политике. Комбинация этих двух механизмов обеспечивает более эффективную и стабильную оптимизацию, чем традиционные подходы.
Механизм контроля KL-дивергенции в SAFE предотвращает чрезмерное отклонение новой политики от исходного распределения, что способствует повышению стабильности обучения. Отклонение политики от исходного распределения может приводить к непредсказуемому поведению и снижению производительности. SAFE ограничивает величину KL-дивергенции, тем самым гарантируя, что обновления политики остаются в пределах приемлемого диапазона и не приводят к резким изменениям в поведении агента. Это особенно важно в задачах с высокой размерностью или сложными функциями вознаграждения, где даже небольшие изменения в политике могут привести к значительным последствиям.
В ходе эмпирических исследований, применение SAFE позволило добиться снижения разброса вознаграждений (reward variance) в 2.8 раза по сравнению с алгоритмом PPO. Данный результат демонстрирует значительное повышение стабильности процесса обучения. Снижение разброса вознаграждений указывает на более предсказуемое и надежное поведение агента в процессе обучения, что особенно важно для сложных задач и сред, где нестабильность может привести к срыву обучения или неоптимальному результату. Полученные данные подтверждают эффективность механизмов динамической регуляции, реализованных в SAFE, в поддержании стабильности и ускорении сходимости алгоритма.
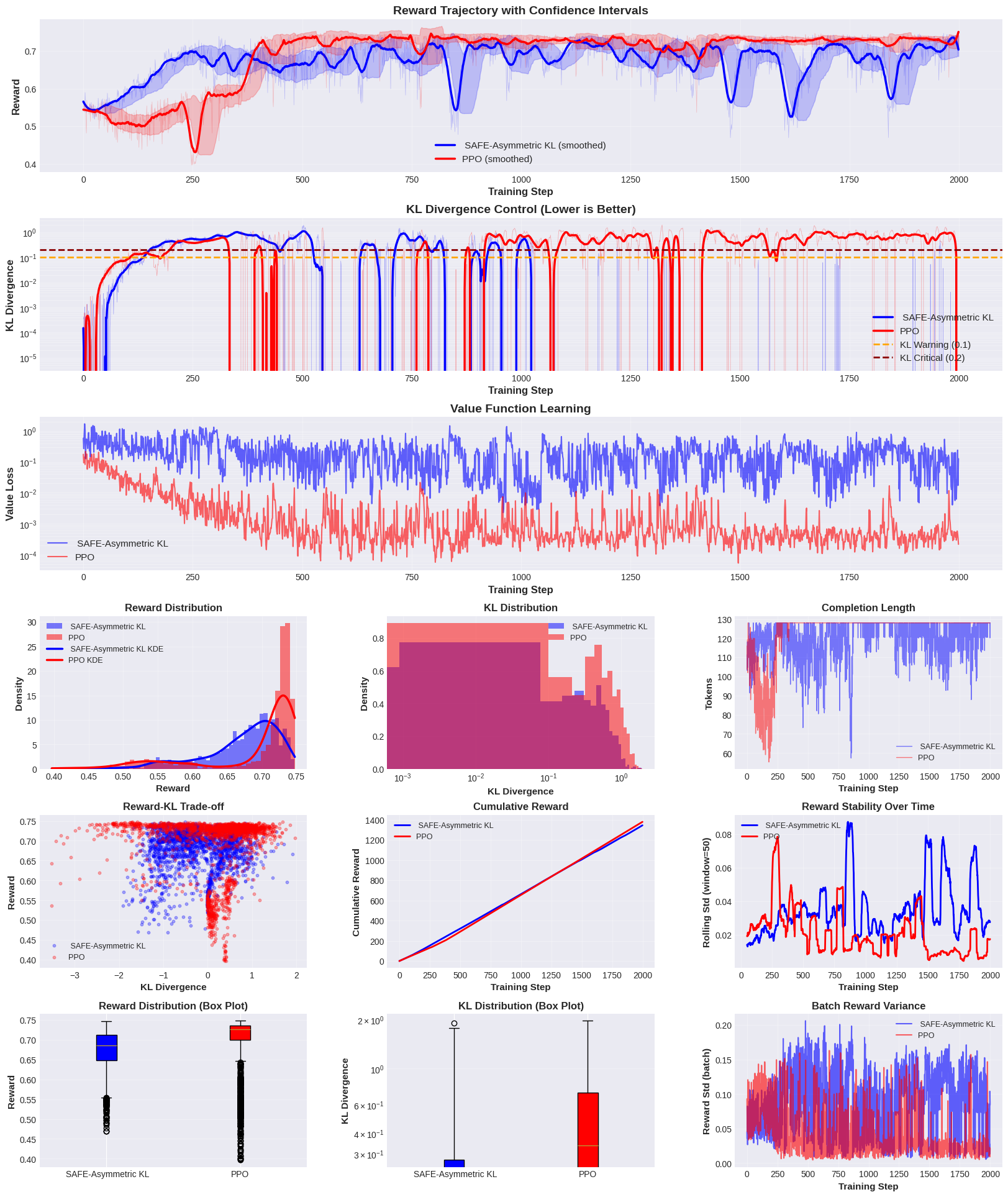
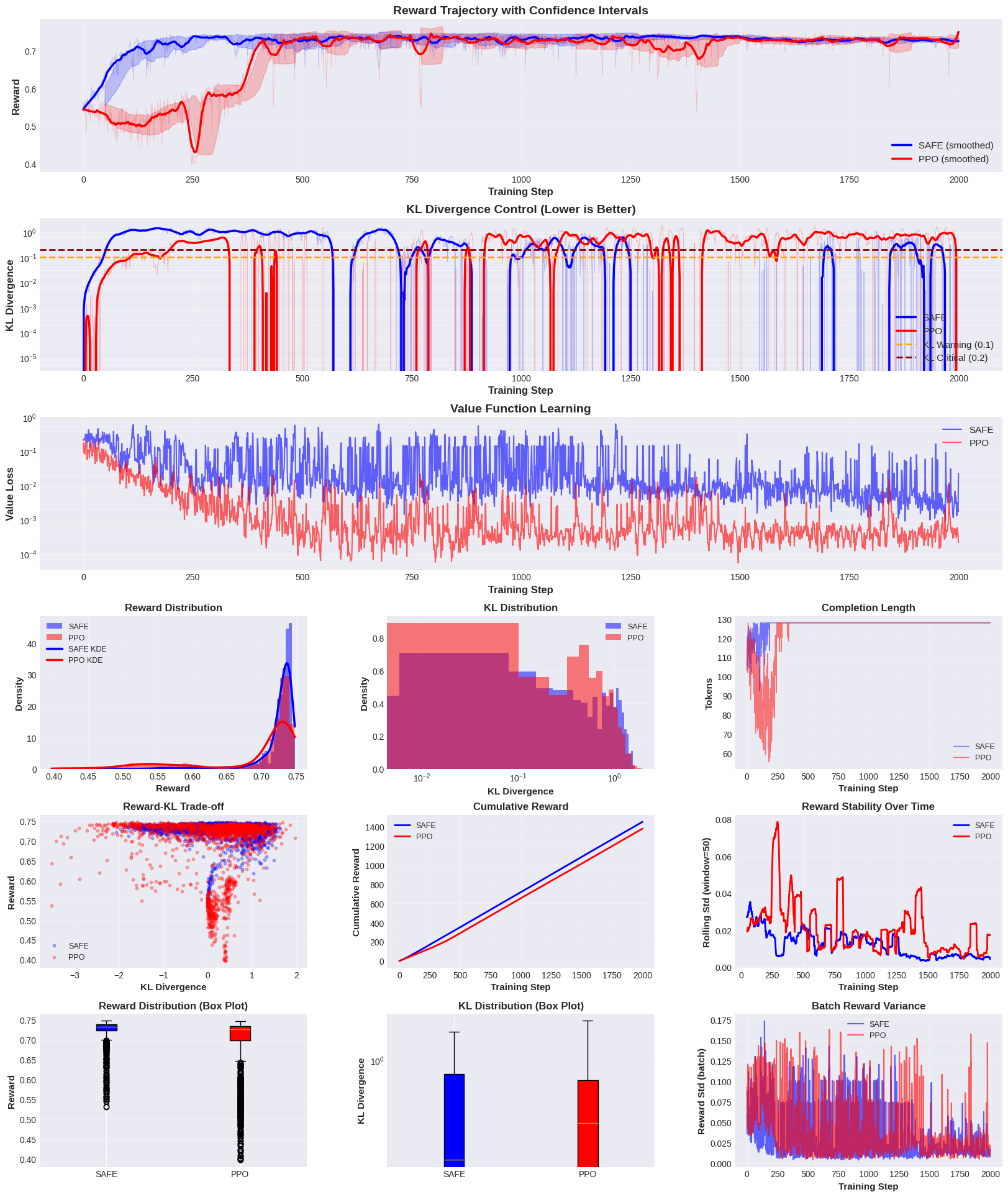
Взгляд в будущее: Расширение границ контролируемого интеллекта
Механизм SAFE демонстрирует значительный потенциал в создании более надежных и согласованных языковых моделей благодаря снижению переоценки ценности и стабилизации процесса обучения. Традиционные методы обучения с подкреплением часто страдают от тенденции к завышению ожидаемых вознаграждений, что приводит к нестабильности и непредсказуемому поведению модели. SAFE, напротив, использует динамические регуляторные механизмы, которые эффективно сдерживают эту переоценку, обеспечивая более плавное и контролируемое обучение. Это, в свою очередь, позволяет создавать модели, которые не только достигают более высоких показателей производительности, но и демонстрируют большую устойчивость к различным входным данным и сценариям, что критически важно для практического применения и обеспечения соответствия ожиданиям пользователей. Стабильность обучения, достигнутая благодаря SAFE, открывает возможности для разработки более сложных и мощных языковых моделей, способных решать широкий спектр задач с высокой точностью и надежностью.
Предложенный фреймворк SAFE, изначально разработанный для обучения языковых моделей с подкреплением, демонстрирует значительный потенциал за пределами области RLHF. Его динамические механизмы регуляризации, направленные на стабилизацию процесса обучения и предотвращение переоценки вознаграждений, применимы к широкому спектру задач обучения с подкреплением. Эти механизмы позволяют адаптировать интенсивность обучения в режиме реального времени, что особенно ценно в сложных средах, где традиционные алгоритмы могут столкнуться с нестабильностью или расхождением. Таким образом, принципы, лежащие в основе SAFE, могут быть успешно интегрированы в различные системы, от робототехники и управления ресурсами до разработки игр, способствуя созданию более надежных и эффективных алгоритмов обучения с подкреплением.
Перспективные исследования направлены на объединение SAFE с передовыми методами обучения с подкреплением, в частности, с обучением вне сети (offline reinforcement learning). Такой симбиоз позволит использовать обширные, уже существующие наборы данных для предварительного обучения агента, значительно сокращая потребность в дорогостоящих и потенциально небезопасных взаимодействиях с реальной средой. Интеграция SAFE с обучением вне сети может обеспечить более стабильное и надежное обучение, особенно в задачах, где сбор данных затруднен или сопряжен с рисками. Это открывает путь к созданию более эффективных и безопасных систем искусственного интеллекта, способных решать сложные задачи в различных областях, от робототехники до автоматизированного принятия решений.
Разработка более надежных и эффективных систем искусственного интеллекта, способных решать сложные задачи реального мира, становится все более реалистичной благодаря новым подходам к обучению с подкреплением. Повышение стабильности и эффективности алгоритмов позволяет создавать модели, лучше адаптирующиеся к разнообразным и непредсказуемым условиям. Это открывает перспективы для применения ИИ в критически важных областях, таких как автономное управление, робототехника и принятие решений в условиях неопределенности. Способность к более эффективному обучению и адаптации позволит создавать интеллектуальные системы, способные решать задачи, ранее считавшиеся невозможными, и значительно расширить границы применения искусственного интеллекта в повседневной жизни и в профессиональной деятельности.
В ходе экспериментов, разработанный фреймворк SAFE продемонстрировал значительное улучшение производительности по сравнению с алгоритмом PPO. В частности, зафиксировано увеличение получаемой награды на 5.2%, что свидетельствует о более эффективном обучении модели. Одновременно с этим, удалось существенно снизить волатильность расхождения KL (мера отклонения от исходной политики) с 0.526 до 0.306 (скользящее стандартное отклонение). Данное снижение указывает на большую стабильность процесса обучения и, как следствие, на более предсказуемое и надежное поведение обученной модели. Полученные результаты подтверждают эффективность SAFE в стабилизации обучения с подкреплением и повышении качества получаемых решений.
Исследование, представленное в статье, демонстрирует стремление к построению надежных систем обучения с подкреплением на основе обратной связи от человека. Попытки стабилизировать процесс обучения, контролируя энтропию и используя пессимистичную оценку ценности, напоминают подход к взлому системы изнутри, когда понимание её уязвимостей позволяет обойти ограничения. Бертранд Рассел однажды заметил: «Всё, что имеет ценность, трудно получить». Эта мысль отражает сложность достижения стабильности в RLHF, где даже кажущийся прогресс может сопровождаться скрытыми рисками, такими как взлом системы вознаграждений. SAFE, предлагаемый в статье, можно рассматривать как попытку создать «защитный код», предотвращающий нежелательные последствия оптимизации.
Что Дальше?
Представленный подход, стремясь укротить неустойчивость обучения с подкреплением на основе обратной связи от человека (RLHF), лишь частично решает фундаментальную проблему: как гарантировать, что система действительно понимает желаемое поведение, а не просто оптимизирует метрику, подверженную взлому. Механизмы пессимистической оценки ценности и контроля энтропии, безусловно, добавляют слоев стабильности, но они — лишь симптоматическое лечение, а не устранение первопричины. Вопрос в том, насколько эти слои смогут устоять перед действительно изощренными стратегиями «взлома» вознаграждения, когда агент научится эксплуатировать мельчайшие несоответствия в системе оценки.
Будущие исследования неизбежно столкнутся с необходимостью более глубокого понимания внутренней репрезентации «намерения» человеком. Простое увеличение количества слоев стабилизации, вероятно, окажется недостаточным. Более перспективным представляется поиск методов, позволяющих системе не просто предсказывать предпочтения человека, но и понимать их, то есть выявлять скрытые ограничения и неявные правила. Иначе говоря, необходимо переходить от поверхностной оптимизации к построению настоящих моделей «здравого смысла».
В конечном итоге, успех в этой области зависит от способности выйти за рамки чисто инженерных решений и взглянуть на проблему с философской точки зрения. Если система не может быть «взломана», это не обязательно означает, что она «поняла». Скорее, это указывает на то, что мы просто не знаем, как её взломать пока. И это — фундаментальный принцип, который следует помнить.
Оригинал статьи: https://arxiv.org/pdf/2602.04651.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Недвижимость и авиа: что ждет потребителей в России? Анализ рынка и новые маршруты (28.03.2026 19:32)
- АЛРОСА акции прогноз. Цена ALRS
- Супернус: Продажа Акций и Нервные Тики
- Будущее FET: прогноз цен на криптовалюту FET
- Будущее KAS: прогноз цен на криптовалюту KAS
- Южнокорейский Крипто-Консолидация: Захват Доли и Риски для Инвесторов (03.04.2026 06:15)
- СириусXM: Пыль дорог и звон монет
- Управление рисками в условиях неопределенности: современные подходы
- ПИК акции прогноз. Цена PIKK
2026-02-05 14:46