Автор: Денис Аветисян
Исследователи предлагают инновационный метод для обработки данных, собранных во времени, который позволяет надежно выявлять важные переменные, даже при наличии выбросов и большого количества параметров.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал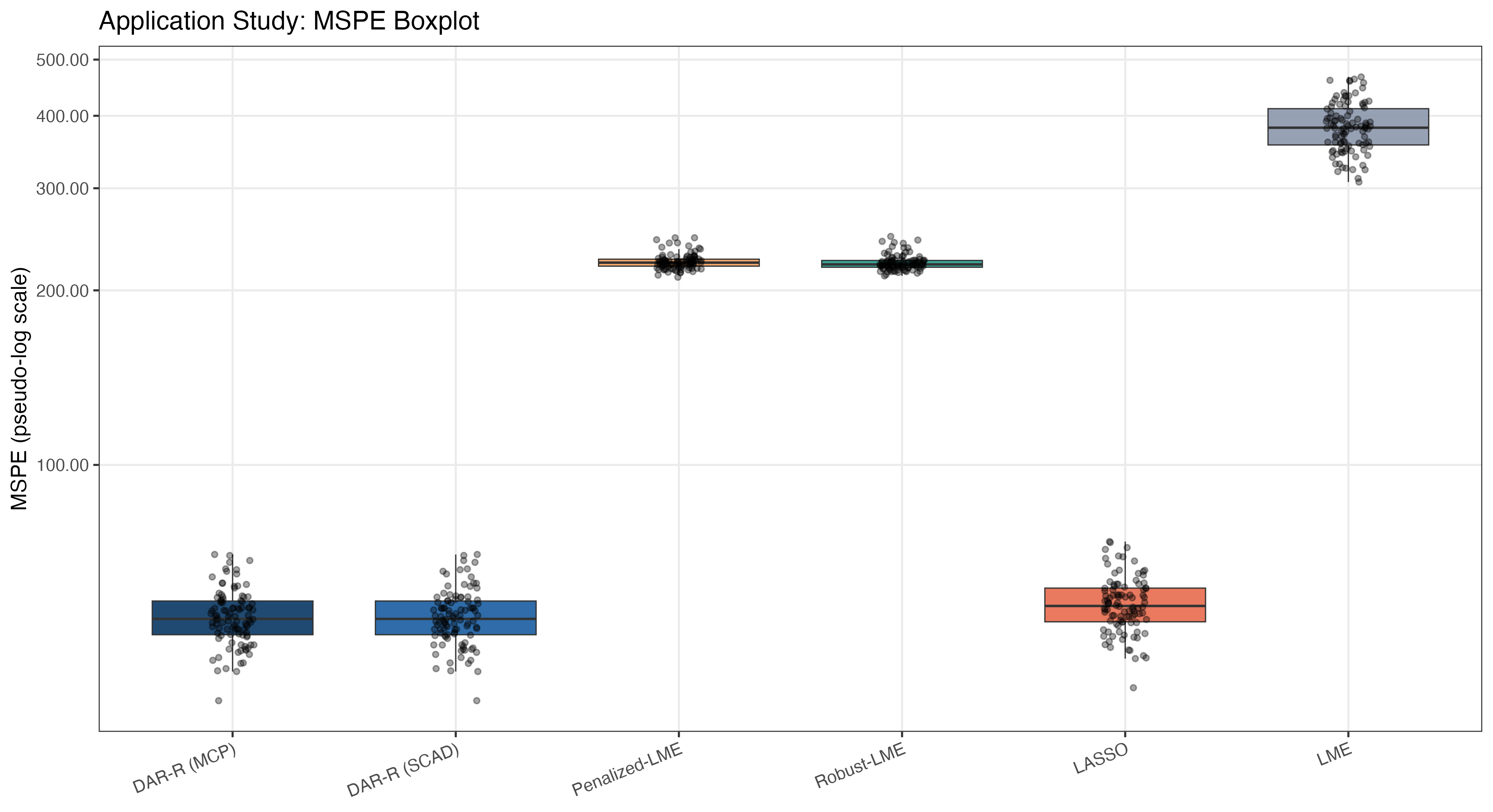
Представлен адаптивный штрафной двухкратно устойчивый регрессионный метод (DAR-R) для анализа продольных данных с высокой размерностью.
Анализ лонгитюдных данных часто осложняется гетерогенностью, разреженностью сигналов и влиянием выбросов, особенно в биомедицинских исследованиях. В работе, озаглавленной ‘Adaptive Penalized Doubly Robust Regression for Longitudinal Data’, предложен новый фреймворк — Doubly Adaptive Robust Regression (DAR-R) — для линейных смешанных моделей, сочетающий в себе устойчивость к выбросам и эффективный отбор переменных. DAR-R использует адаптивные веса наблюдений и folded-concave регуляризацию, что позволяет повысить точность оценки, контроль ложноположительных результатов и стабильность предсказаний. Возможно ли дальнейшее развитие данного подхода для решения задач, связанных с анализом сложных лонгитюдных данных в различных областях науки и практики?
Шёпот Хаоса в Данных: Проблема Загрязнения в Логитюдных Исследованиях
Долгосрочные исследования, имеющие решающее значение для понимания динамики развития заболеваний, часто сталкиваются с проблемой загрязнения данных, вызванным наличием аномальных значений или необычных испытуемых. Эти отклонения могут возникать по различным причинам — от ошибок при сборе информации и неправильной регистрации данных, до индивидуальных особенностей пациентов, не соответствующих общей тенденции. Несмотря на то, что исследователи прилагают усилия для обеспечения точности и надежности данных, полностью исключить подобные «выбросы» практически невозможно. Именно поэтому критически важно разработать и применять методы, способные эффективно выявлять и нейтрализовать влияние загрязненных данных, чтобы обеспечить достоверность результатов и избежать ошибочных выводов о прогрессировании заболевания.
Традиционные линейные смешанные модели (LMM) при анализе лонгитюдных данных, несмотря на свою широкую распространенность, оказываются весьма чувствительными к выбросам и аномальным наблюдениям. Даже единичные субъекты, демонстрирующие нетипичную динамику, способны существенно исказить оценки параметров модели, приводя к смещенным результатам и, как следствие, к ошибочным выводам о развитии изучаемого явления. Это особенно критично в исследованиях, направленных на выявление закономерностей в прогрессировании заболеваний, где даже небольшие погрешности в оценках могут привести к неправильной интерпретации эффективности лечения или выявлению ложных корреляций. Таким образом, учет и смягчение влияния контаминированных данных является необходимой предпосылкой для обеспечения надежности и достоверности лонгитюдного анализа.
Обеспечение достоверности и надежности результатов в продольных исследованиях имеет первостепенное значение, поскольку любые искажения, вызванные загрязненными данными, могут существенно повлиять на выводы о динамике заболеваний и эффективности вмешательств. Неспособность адекватно учитывать влияние выбросов или аномальных субъектов приводит к смещенным оценкам параметров модели и неверной интерпретации наблюдаемых тенденций. В связи с этим, разработка и применение методов, устойчивых к таким искажениям, является критически важной задачей для получения научно обоснованных и клинически значимых результатов, позволяющих принимать взвешенные решения в области здравоохранения и профилактики заболеваний. Игнорирование этой проблемы может привести к ошибочным представлениям о реальной картине заболевания и, как следствие, к неэффективным стратегиям лечения и управления здоровьем.
![Ящики с усами показывают логарифмически преобразованную [latex]log_{10}[/latex] оценку ковариации случайных эффектов.](https://arxiv.org/html/2602.21711v1/x4.png)
Двойная Адаптация: Укрощение Выбросов с Помощью DAR-R
Двойная адаптивная робастная регрессия (DAR-R) представляет собой новое расширение линейных смешанных моделей (LMM), разработанное специально для снижения влияния загрязненных данных. В контексте статистического моделирования, «загрязненные данные» подразумевают наблюдения, содержащие выбросы или ошибки, которые могут существенно исказить оценки параметров модели. DAR-R направлена на повышение устойчивости оценок параметров за счет минимизации воздействия этих аномальных наблюдений на результаты регрессионного анализа, что особенно важно при работе с наборами данных, содержащими потенциальные ошибки измерений или аномальные значения.
Алгоритм DAR-R (Doubly Adaptive Robust Regression) использует итеративный процесс перевзвешивания для снижения влияния выбросов и влиятельных наблюдений. На каждом шаге итерации вычисляются адаптивные веса, основанные на стандартизированных остатках r_i и рычаге ковариат h_i. Стандартизированные остатки показывают величину отклонения наблюдения от предсказанного значения, скорректированного на дисперсию ошибки, а рычаг ковариат указывает на степень влияния конкретного наблюдения на оценку параметров модели. Веса вычисляются таким образом, чтобы наблюдения с большими абсолютными значениями стандартизированных остатков и/или высоким рычагом получали меньшие веса, что эффективно уменьшает их вклад в оценку параметров модели. Этот процесс повторяется до сходимости, обеспечивая более устойчивые и точные оценки в присутствии загрязненных данных.
Алгоритм DAR-R обеспечивает снижение влияния проблемных наблюдений на оценки параметров модели путем итеративной перевзвешивания. В процессе анализа стандартизированные остатки и рычаг ковариат используются для расчета адаптивных весов, которые присваиваются каждому наблюдению. Наблюдения с большими абсолютными значениями стандартизированных остатков или высоким рычагом получают меньшие веса, что снижает их вклад в функцию потерь и, следовательно, в итоговые оценки параметров. Это позволяет получить более устойчивые и точные оценки, особенно в условиях загрязнения данных выбросами или влиятельными наблюдениями. Повторение процесса перевзвешивания до сходимости гарантирует, что влияние проблемных наблюдений будет последовательно уменьшаться, что приводит к более надежным результатам регрессионного анализа.
Разреженность и Отбор Признаков: Скрытая Структура в Данных
Метод DAR-R использует методы штрафных функций с вогнутыми углами (SCAD или MCP) для достижения разреженности модели. Эти методы добавляют штраф к функции потерь, который увеличивается медленнее, чем у L1-регуляризации (LASSO), что позволяет некоторым коэффициентам модели обнуляться, эффективно выполняя отбор признаков. λ — параметр регуляризации, контролирующий степень штрафа и, следовательно, разреженность. В отличие от L1-регуляризации, которая может приводить к выбору только одного признака из группы сильно коррелированных признаков, методы SCAD и MCP обеспечивают более стабильный выбор признаков, позволяя включать несколько коррелированных признаков в модель.
Разреженность, достигаемая в методе DAR-R за счет использования folded-concave регуляризации, обеспечивает автоматический отбор переменных. В процессе обучения модели, переменные с незначительным вкладом в объяснение целевой переменной эффективно исключаются из модели, приводя к упрощению ее структуры. Это достигается путем приведения коэффициентов неважных переменных к нулю или близким к нулю значениям, что позволяет идентифицировать наиболее значимые предикторы и сосредоточиться на них. В результате, упрощенная модель содержит только ключевые факторы, влияющие на результат, что улучшает ее интерпретируемость и снижает риск переобучения.
Уменьшение сложности модели в DAR-R, достигаемое за счет использования разреженных оценок, оказывает положительное влияние как на интерпретируемость, так и на прогностическую способность. Более простая модель, содержащая меньшее количество значимых предикторов, легче анализируется и позволяет более четко определить ключевые факторы, влияющие на целевую переменную. Кроме того, снижение переобучения, характерное для сложных моделей, приводит к улучшению обобщающей способности и, следовательно, к более точным прогнозам на новых, ранее не встречавшихся данных. В результате, DAR-R обеспечивает баланс между точностью предсказаний и понятностью полученной модели.
Подтверждение Эффективности: Анализ Реальных Данных
Для проверки и оценки эффективности разработанной модели DAR-R были использованы два авторитетных лонгитюдных набора данных: Alzheimer’s Disease Neuroimaging Initiative (ADNI) и TADPOLE. ADNI представляет собой масштабное исследование, направленное на изучение болезни Альцгеймера, включающее в себя данные нейровизуализации, биомаркеров и клинических оценок. TADPOLE, в свою очередь, фокусируется на ранней диагностике и отслеживании прогрессирования болезни Альцгеймера с использованием мультимодальных данных. Применение DAR-R к этим наборам данных позволило провести всестороннюю оценку её способности выявлять закономерности в динамике заболевания и прогнозировать индивидуальные траектории развития, что является критически важным для разработки эффективных стратегий лечения и профилактики.
Исследования показали, что разработанный подход DAR-R демонстрирует стабильное превосходство над традиционными линейными смешанными моделями (LMM) в задачах прогнозирования на двух крупных лонгитюдных наборах данных — Alzheimer’s Disease Neuroimaging Initiative (ADNI) и TADPOLE. Полученные результаты свидетельствуют о достижении передовых показателей точности в предсказании развития заболеваний, что подтверждает эффективность DAR-R в анализе динамических данных. Данное превосходство обусловлено способностью алгоритма более эффективно учитывать индивидуальные траектории пациентов и выделять наиболее значимые факторы, влияющие на прогрессирование болезни, обеспечивая более надежные и точные прогнозы по сравнению с существующими методами.
Разработанный фреймворк демонстрирует повышенную надежность в анализе прогрессирования заболеваний благодаря способности точно выделять ключевые факторы, влияющие на течение болезни, и эффективно нивелировать воздействие аномальных значений. В отличие от традиционных методов, основанных на линейных смешанных моделях, данная система обеспечивает более точную оценку активных и неактивных коэффициентов, что позволяет с большей уверенностью определять наиболее значимые предикторы. Это, в свою очередь, ведет к более глубокому пониманию механизмов развития заболевания и повышает точность прогнозирования, предоставляя исследователям и клиницистам более ценные инструменты для диагностики и разработки эффективных стратегий лечения.
Взгляд в Будущее: Теоретические Основы и Перспективы Развития
Исследование демонстрирует, что разработанный метод DAR-R обладает благоприятными теоретическими свойствами, включая состоятельность и эффективность даже при умеренных условиях. Состоятельность означает, что по мере увеличения объема выборки, оценка, полученная с помощью DAR-R, стремится к истинному значению параметра. Эффективность, в свою очередь, указывает на то, что метод достигает минимально возможной дисперсии среди всех состоятельных оценок. Эти свойства гарантируют надежность и точность получаемых результатов, что делает DAR-R перспективным инструментом для анализа данных в различных областях.
Особые свойства разработанного метода оценки, известные как сходимость и эффективность, гарантируют, что по мере увеличения объема выборки оценка будет всё точнее приближаться к истинному значению. Это означает, что с ростом количества данных погрешность оценки закономерно уменьшается, обеспечивая высокую надежность результатов. Кроме того, достигается минимальная дисперсия, что свидетельствует о стабильности оценки и её устойчивости к случайным колебаниям. Таким образом, \lim_{n \to \in fty} \hat{\theta}_n = \theta указывает на асимптотическую несмещенность и точность, что делает данный метод перспективным инструментом для анализа данных.
Разработанный метод DAR-R демонстрирует эффективный контроль над уровнем ложных открытий, что особенно важно при анализе больших объемов данных и выявлении значимых закономерностей. В дальнейших исследованиях планируется расширить возможности DAR-R для работы с более сложными структурами данных, включая нелинейные модели и данные с высокой размерностью. Кроме того, предполагается изучить применимость данного подхода в различных областях, таких как геномика, нейронауки и экономика, где точное определение значимых сигналов имеет решающее значение. Подобное расширение позволит использовать DAR-R в качестве универсального инструмента для статистического анализа и принятия решений в широком спектре научных дисциплин.
Данное исследование, предлагающее новый подход к анализу лонгитюдных данных, напоминает попытку усмирить неуловимый хаос. Авторы предлагают Doubly Adaptive Robust Regression (DAR-R) — инструмент, призванный отсеять выбросы и выделить истинные факторы изменения во времени. Эта работа, по сути, заклинание, направленное на то, чтобы извлечь сигнал из шума. Как метко заметил Томас Гоббс: «Человеческое естество есть, по сути, страх и надежда». В контексте анализа данных, этот страх — боязнь ложных корреляций, а надежда — возможность найти значимые связи, скрытые в потоке информации. DAR-R, подобно хорошо продуманному ритуалу, стремится минимизировать влияние случайных помех, позволяя увидеть закономерности, которые иначе остались бы незамеченными.
Что дальше?
Предложенный подход, этот DAR-R, — лишь очередное заклинание, призванное усмирить хаос продольных данных. И как любое заклинание, оно работает… пока не встретит первую аномалию, первый шепот истинного сигнала, затерянного в море шума. Упор на устойчивость к выбросам — это хорошо, но сама природа выбросов требует осмысления. Не каждый выброс — ошибка измерения, порой это — проявление скрытой закономерности, улыбающейся над наивностью наших моделей.
Будущее этой области — не в совершенствовании штрафных функций или алгоритмов отбора переменных. Будущее — в признании ограниченности любых моделей. Необходимо разрабатывать методы, позволяющие не просто обнаруживать аномалии, но и интерпретировать их, выуживать из них полезную информацию. Следует искать способы объединения DAR-R с моделями, учитывающими нелинейные зависимости и сложные временные структуры. Иначе, мы обречены на вечное дописывание исключений к исключениям.
В конечном счете, задача анализа продольных данных — не построение «идеальной» модели, а умение слушать. Слушать шепот данных, улавливать оттенки случайности, и признавать, что истина часто прячется за пределами наших самых смелых предположений. И да, стоит помнить, что каждая модель — это всего лишь приближение, и чем точнее приближение, тем больше вероятность столкнуться с реальностью, которая его опровергнет.
Оригинал статьи: https://arxiv.org/pdf/2602.21711.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать доллары за рубли сейчас или подождать?
- Будущее биткоина к рублю: прогноз цен на криптовалюту BTC
- Будущее биткоина: прогноз цен на криптовалюту BTC
- Стоит ли покупать фунты за йены сейчас или подождать?
- Пошлины Трампа и падение «ЕвроТранса»: что ждет инвесторов? (21.02.2026 23:32)
- Золото прогноз
- Риски для бизнеса и туристический спрос: что ждет российскую экономику? (22.02.2026 18:32)
- Геопространственные модели для оценки оползневой опасности: новый уровень точности
- Серебро прогноз
- Почему акции Joby взлетают: приобретение Blade
2026-02-26 19:07