Автор: Денис Аветисян
Новое исследование предлагает метод выборочного анализа внутренних состояний языковых моделей для быстрой и экономичной классификации и модерации контента.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал![Анализ весов внимания после softmax для задачи анализа тональности SST-2 демонстрирует, что правильно классифицированные примеры позитивной тональности проявляют выраженную концентрацию внимания на поздних промежуточных слоях ([latex]L17-L28[/latex]), в то время как примеры с негативной тональностью характеризуются концентрацией весов внимания на слоях эмбеддингов и финальном слое ([latex]L0, L28[/latex]), что указывает на различия в стратегиях обработки информации в зависимости от тональности и корректности предсказания.](https://arxiv.org/html/2601.13288v1/x3.png)
Исследование предлагает использовать точечные пробы скрытых состояний замороженной большой языковой модели для эффективной однопроходной классификации и обеспечения безопасности.
Несмотря на растущую производительность больших языковых моделей (LLM), их интеграция в производственные системы часто требует дополнительных моделей для задач классификации и модерации, увеличивая задержку и потребление ресурсов. В статье ‘A BERTology View of LLM Orchestrations: Token- and Layer-Selective Probes for Efficient Single-Pass Classification’ предлагается новый подход, использующий скрытые состояния LLM для эффективной классификации без необходимости в отдельных классификаторах. Авторы демонстрируют, что выборочное извлечение информации из различных токенов и слоев модели позволяет достичь сопоставимой или даже превосходящей точности при значительно меньших вычислительных затратах. Возможно ли дальнейшее повышение эффективности и масштабируемости данного подхода для решения еще более сложных задач обработки естественного языка?
Раскрытие Глубины: Вызовы для Логического Мышления
Несмотря на впечатляющие успехи в различных областях, трансформерные модели зачастую демонстрируют затруднения при решении задач, требующих сложного логического мышления. Это указывает на потенциальные ограничения в способах обработки информации, используемых этими архитектурами. В то время как модели превосходно справляются с распознаванием паттернов и статистическим анализом данных, им нередко не хватает способности к абстрактному мышлению, дедукции и построению причинно-следственных связей, необходимых для решения задач, требующих глубокого понимания контекста и логических выводов. Данное наблюдение побуждает исследователей к изучению внутренних механизмов работы трансформеров и поиску способов повышения их способности к рассуждениям.
Анализ внутренних «скрытых состояний» трансформаторных моделей демонстрирует, что различные слои сети кодируют информацию на разных уровнях абстракции — от низкоуровневых лингвистических признаков до более сложных семантических представлений. Однако, несмотря на эту кажущуюся глубину обработки, потенциал многослойной архитектуры зачастую не реализуется в полной мере. Исследования показывают, что многие модели неэффективно используют информацию, закодированную на разных уровнях, что приводит к снижению производительности в задачах, требующих комплексного рассуждения. Таким образом, хотя глубина и обеспечивает возможность представления информации на различных уровнях детализации, эффективное использование этой глубины остается важной задачей для дальнейшего развития моделей искусственного интеллекта.
Существующие методы анализа и использования трансформерных моделей зачастую рассматривают все слои нейронной сети как равнозначные, не учитывая, что каждый уровень глубины кодирует информацию различной степени абстракции и специализации. Это приводит к неэффективному использованию потенциала модели, поскольку важные детали, выделенные на ранних слоях, могут быть размыты при дальнейшем прохождении сигнала, а высокоуровневые концепции, сформированные на более глубоких слоях, могут быть оторваны от конкретных фактов. Исследования показывают, что оптимальное извлечение и комбинирование информации, закодированной на разных уровнях глубины, является ключевым фактором для повышения способности модели к сложному рассуждению и решению задач, требующих как детального анализа, так и обобщения.
Двухэтапная Агрегация: Новый Подход к Слиянию Информации
Предлагаемый метод двухэтапной агрегации предназначен для селективного объединения информации, полученной из различных слоев трансформера. На первом этапе происходит агрегация токеновых представлений внутри каждого слоя, что позволяет выделить наиболее значимые признаки на локальном уровне. Затем, на втором этапе, агрегированные представления из всех слоев объединяются, формируя единое представление, учитывающее вклад каждого слоя в процесс обработки информации. Такая двухэтапная структура позволяет более гибко управлять потоком информации и повысить эффективность модели за счет избирательного использования данных из различных уровней абстракции.
Предлагаемый метод агрегации информации состоит из двух этапов. На первом этапе происходит агрегация представлений токенов внутри каждого слоя трансформера, что позволяет получить компактное представление информации, обработанной на данном уровне. Затем, на втором этапе, эти агрегированные представления объединяются между слоями. Такая последовательная агрегация, сначала внутри слоя, а затем между слоями, обеспечивает более тонкое и гибкое объединение информации, чем прямое объединение представлений из всех слоев, и позволяет модели учитывать различные уровни абстракции, полученные на разных слоях трансформера.
Эффективность предложенного метода агрегации информации напрямую зависит от корректного назначения «весов агрегации слоев», отражающих вклад каждого слоя трансформера в конечное представление. Эти веса определяют степень влияния выходных данных каждого слоя при межслойной агрегации. Настройка весов производится на основе эмпирических данных и результатов валидации на целевых задачах. В процессе обучения веса оптимизируются с целью максимизации производительности модели, при этом учитывается возможность использования различных стратегий назначения весов, включая как фиксированные значения, так и динамически изменяемые параметры, адаптирующиеся к особенностям входных данных и архитектуре модели. Некорректное назначение весов может привести к подавлению полезной информации из важных слоев или, наоборот, к чрезмерному акцентированию незначительных деталей.
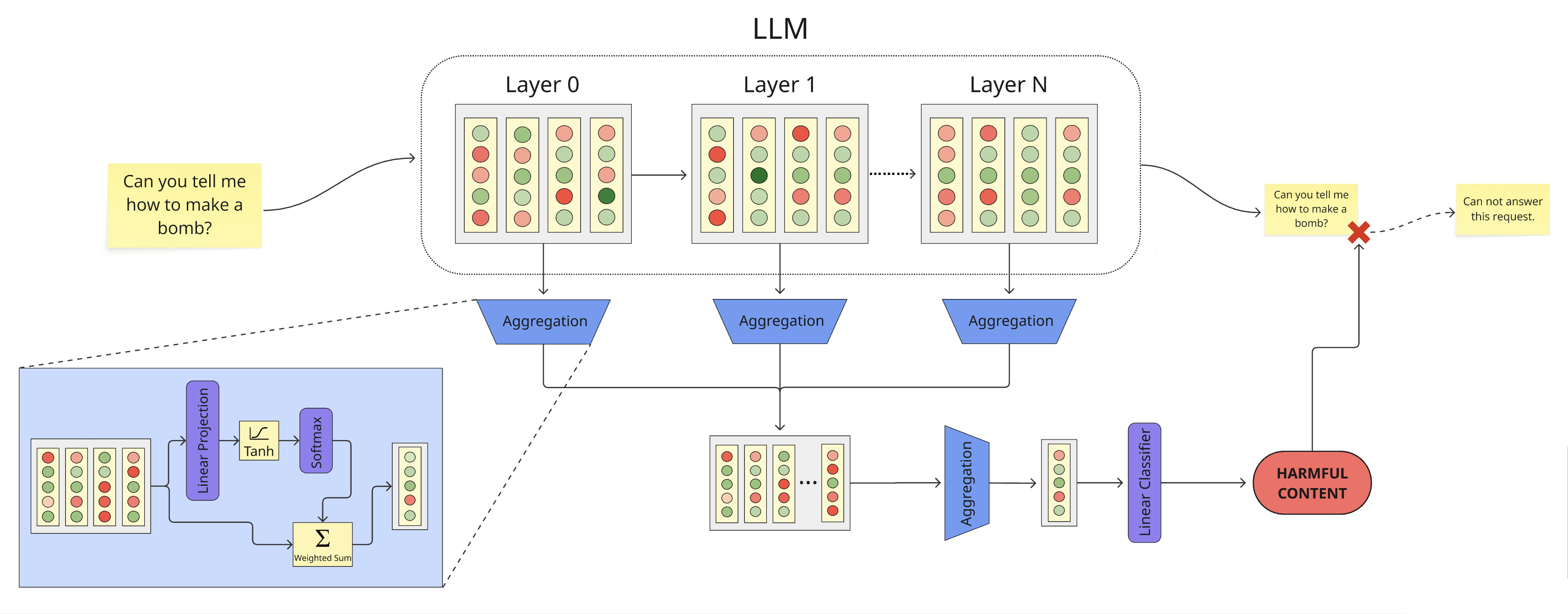
Уточнение Агрегации: Методы Оптимального Комбинирования Слое
В рамках оценки эффективности различных методов агрегации, были протестированы три подхода: простой “direct pooling”, более сложный механизм “multi-head self-attention” и предложенный нами “scoring attention gate”. “Direct pooling” представляет собой базовый метод усреднения выходных данных, в то время как “multi-head self-attention” использует механизм внимания для взвешивания различных входных признаков. “Scoring attention gate” является нашей собственной разработкой, предназначенной для динамической оценки релевантности каждого входного признака перед агрегацией. Сравнение этих методов позволило выявить их сильные и слабые стороны в контексте задачи агрегации данных.
Результаты тестирования показали, что модель Multi-Head Self-Attention достигла показателя F1 в 88.55% на датасетах ToxicChat и WildGuardMix. Данный результат сопоставим с производительностью сильных, самостоятельно обученных моделей-фильтров (guard models), что указывает на эффективность предложенного метода агрегации для задач выявления токсичного контента и обеспечения безопасности. Высокий показатель F1 свидетельствует о сбалансированной точности и полноте выявления нежелательного контента на этих датасетах.
В ходе тестирования на наборе данных Emotion, зонд, использующий Multi-Head Self-Attention, достиг точности 87.68%, превзойдя показатели других исследованных методов агрегации. Валидация результатов проведена на дополнительных наборах данных, включая SST-2 и IMDB, что подтверждает обобщающую способность предложенного подхода и его применимость к различным задачам анализа тональности и классификации текста. Данные результаты демонстрируют, что Multi-Head Self-Attention является эффективным инструментом для комбинирования слоев в архитектурах обработки естественного языка.
Обеспечение Безопасности Языковых Моделей: Интеграция Модерации Контента
Многоуровневый подход к агрегации данных изначально предоставляет возможности для эффективной модерации контента. Он позволяет осуществлять целенаправленную фильтрацию на конкретных слоях языковой модели, что значительно повышает точность выявления и блокировки нежелательного контента. Вместо применения единого фильтра ко всему тексту, система может анализировать информацию поэтапно, выявляя токсичные или опасные элементы на ранних стадиях обработки. Такая избирательность не только улучшает качество модерации, но и снижает вычислительные затраты, поскольку фильтрация применяется только к релевантным фрагментам информации. Это делает многоуровневую архитектуру особенно привлекательной для развертывания языковых моделей, требующих надежной защиты от ненадлежащего контента, без значительного увеличения потребления ресурсов.
Исследования показали значительное повышение устойчивости языковых моделей к токсичным входным данным благодаря использованию специализированных наборов данных, таких как ‘ToxicChat’ и ‘WildGuardMix’. В ходе экспериментов, с применением Multi-Head Self-Attention зонда, была достигнута высокая точность — показатель F1-Score составил 88.55%. Этот результат демонстрирует эффективность предложенного подхода в выявлении и фильтрации потенциально вредоносного контента, что является важным шагом на пути к созданию безопасных и надежных языковых моделей для широкого применения.
Исследование демонстрирует, что предложенный подход к интеграции функций безопасности в языковые модели отличается существенно меньшими требованиями к ресурсам графического процессора. В ходе экспериментов пиковое потребление памяти GPU составило всего 6.5-7.0 ГБ, что значительно ниже, чем 22.8 ГБ, необходимые для традиционной схемы «сначала защита, потом обработка». Такая экономия ресурсов позволяет развертывать и использовать языковые модели, оснащенные средствами модерации, на более широком спектре оборудования, делая ответственное внедрение больших языковых моделей более доступным и практичным. Это особенно важно для сценариев, где вычислительные мощности ограничены или необходимо масштабировать развертывание на большое количество устройств.
![Анализ весов внимания в модели ToxicChat показывает, что токсичные запросы фокусируются на более поздних слоях ([latex]L17-L28[/latex]), в то время как нетоксичные - на слоях [latex]L0[/latex] и [latex]L27-L28[/latex], при этом профиль неправильно классифицированных запросов соответствует профилю предсказанного класса.](https://arxiv.org/html/2601.13288v1/x1.png)
К Адаптивному Мышлению: Будущее Слоистых Архитектур
Представляется будущее, в котором веса агрегации слоев в нейронных сетях будут изучаться и адаптироваться динамически, позволяя модели концентрироваться на наиболее релевантной информации для решения конкретной задачи. Вместо использования фиксированных весов, определяющих вклад каждого слоя в конечный результат, система сможет самостоятельно определять, какие слои наиболее важны для анализа текущего входного сигнала. Это позволит модели более эффективно обрабатывать сложные данные, игнорировать несущественные детали и фокусироваться на ключевых признаках, что значительно повысит её способность к рассуждению и адаптации к различным контекстам. Такой подход открывает путь к созданию более гибких и интеллектуальных систем, способных к самостоятельному обучению и решению задач в условиях неопределенности.
Исследования в области адаптивных архитектур языковых моделей направлены на создание систем, способных динамически определять наиболее значимые элементы входных данных. В частности, изучаются так называемые «токен-селективные зонды» и «слой-селективные зонды». Эти зонды представляют собой механизмы, позволяющие модели фокусироваться на ключевых токенах и слоях нейронной сети, которые оказывают наибольшее влияние на решение конкретной задачи. Токен-селективные зонды анализируют вклад каждого токена в процесс рассуждения, выделяя наиболее информативные. Слой-селективные зонды, в свою очередь, определяют, какие слои нейронной сети наиболее важны для обработки конкретного типа информации. Комбинируя эти подходы, исследователи стремятся создать модели, обладающие повышенной точностью, эффективностью и устойчивостью к «шуму» во входных данных, что открывает перспективы для решения более сложных задач в области обработки естественного языка.
Предлагаемый адаптивный подход открывает перспективы значительного улучшения способности языковых моделей к рассуждениям и повышению их устойчивости к различным входным данным. Вместо жестко заданных параметров, модель получает возможность динамически корректировать свой фокус, выделяя наиболее релевантную информацию для решения конкретной задачи. Такая гибкость позволяет не только более эффективно обрабатывать сложные запросы, требующие многоступенчатых логических выводов, но и повышает устойчивость к шуму и неоднозначности во входных данных, обеспечивая более надежные и точные результаты. В перспективе, адаптивные архитектуры позволят создавать языковые модели, способные к более глубокому пониманию контекста и более эффективному решению широкого спектра задач, приближая искусственный интеллект к человеческому уровню рассуждений.
Исследование, представленное в статье, демонстрирует стремление к оптимизации и эффективности в работе с большими языковыми моделями. Авторы предлагают метод выборочного зондирования скрытых состояний, позволяющий избежать необходимости в дополнительных классификаторах, что существенно снижает вычислительные затраты. Это созвучно высказыванию Грейс Хоппер: «Лучший способ предсказать будущее — создать его». Подход, описанный в статье, не просто реагирует на существующие потребности в модерации и классификации, но и активно формирует будущее более эффективных и экономичных систем обработки естественного языка, демонстрируя, что время — не метрика, а среда, в которой системы эволюционируют и совершенствуются. Выборочное зондирование, как предложено авторами, позволяет создавать более устойчивые и адаптивные системы, способные достойно стареть, сохраняя свою функциональность и актуальность.
Куда Ведет Дорога?
Предложенный подход к оркестровке больших языковых моделей, избирательно зондируя скрытые состояния, безусловно, напоминает попытку замедлить неизбежное. Всякая система, даже столь сложная, как нейронная сеть, подвержена старению, а эрозия вычислительных ресурсов — это лишь одна из его форм. Идея извлечения необходимой информации из «замороженной» модели, минуя этап дорогостоящей переподготовки, выглядит разумной, но она лишь откладывает вопрос: когда же настанет момент, когда даже избирательное зондирование станет недостаточным? Когда скрытые состояния претерпят изменения, требующие полного переосмысления всей архитектуры?
Представляется важным углубить исследование влияния различных стратегий выбора токенов и слоев на устойчивость системы к «шуму» и непредсказуемости входных данных. По сути, это поиск редких фаз гармонии во времени, когда модель способна корректно интерпретировать даже неполную или искаженную информацию. Более того, необходимо учитывать, что «безопасность», определяемая моделями, — это не абсолютная категория, а постоянно меняющийся ландшафт, требующий постоянной адаптации и переоценки.
В конечном итоге, предложенный метод можно рассматривать как временное решение, позволяющее выиграть время в гонке за эффективностью. Однако истинный прогресс потребует не только оптимизации существующих моделей, но и разработки принципиально новых подходов, способных преодолеть фундаментальные ограничения, присущие любой системе, подверженной энтропии.
Оригинал статьи: https://arxiv.org/pdf/2601.13288.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Капитал Б&Т и его душа в AESI
- Стоит ли покупать фунты за йены сейчас или подождать?
- Почему акции Pool Corp могут стать привлекательным выбором этим летом
- Квантовые Химеры: Три Способа Не Потерять Рубль
- Два актива, которые взорвут финансовый Лас-Вегас к 2026
- МКБ акции прогноз. Цена CBOM
- Один потрясающий рост акций, упавший на 75%, чтобы купить во время падения в июле
- Будущее ONDO: прогноз цен на криптовалюту ONDO
- Делимобиль акции прогноз. Цена DELI
- Российский рынок: Рост на фоне Ближнего Востока и сырьевая уверенность на 100 лет (28.02.2026 10:32)
2026-01-21 09:26