Автор: Денис Аветисян
Новое исследование выявляет ключевые принципы, определяющие эффективность дообучения больших языковых моделей для решения задач в различных научных областях.
"Покупай на слухах, продавай на новостях". А потом сиди с акциями никому не известной биотех-компании. Здесь мы про скучный, но рабочий фундаментал.
Бесплатный Телеграм канал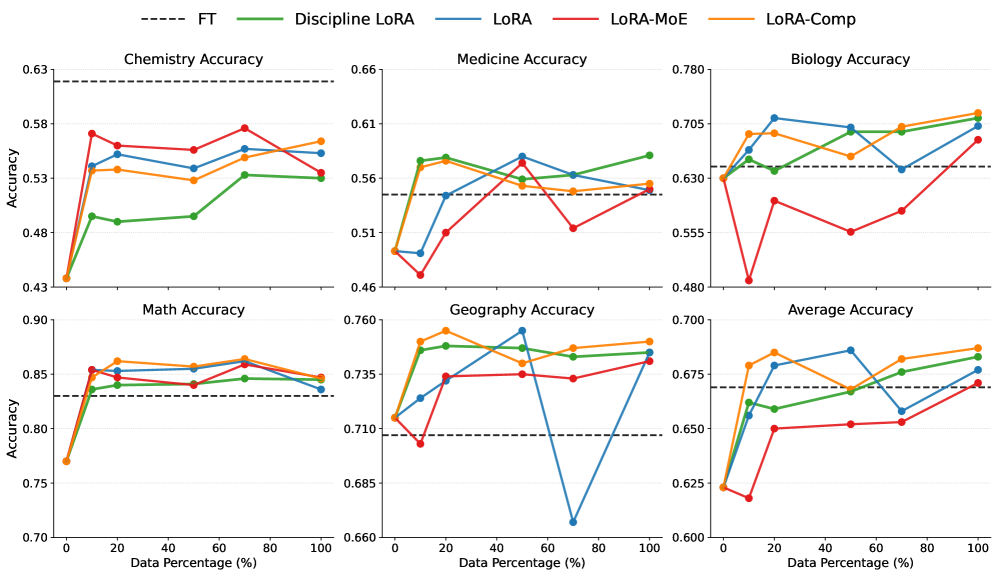
Систематическое изучение дообучения больших языковых моделей позволило сформулировать четыре эмпирических закона, обеспечивающих создание надежных и обобщающих научных ИИ.
Несмотря на значительные успехи больших языковых моделей (LLM) в отдельных научных областях, закономерности их обучения в мультидисциплинарных контекстах остаются малоизученными. В работе ‘Charting Empirical Laws for LLM Fine-Tuning in Scientific Multi-Discipline Learning’ представлено первое систематическое исследование мультидисциплинарной тонкой настройки LLM, в ходе которого выявлены четыре эмпирических закона, определяющих эффективное обучение. Эти законы — «Сбалансируй-и-Разнообразь», «Объединяй-и-Согласовывай», «Оптимизируй-и-Масштабируй», и «Разделяй-и-Специализируй» — формируют практические рекомендации для разработки обобщенных научных LLM. Смогут ли эти законы стать основой для создания принципиально новых, более адаптивных и эффективных моделей искусственного интеллекта в науке?
Вызов междисциплинарного понимания: Ограничения традиционных больших языковых моделей
Несмотря на впечатляющие успехи в решении разнообразных задач, большие языковые модели часто демонстрируют ограниченные возможности в области истинного междисциплинарного понимания и рассуждений. Они способны эффективно оперировать знаниями, полученными из одного конкретного домена, но испытывают трудности при интеграции и применении этих знаний в контексте других, существенно отличающихся областей науки. Например, модель, обученная на корпусе химических текстов, может испытывать сложности при анализе географических данных или биологических процессов, даже если задача требует лишь базового применения общих принципов. Это связано с тем, что традиционные модели, как правило, овладевают поверхностными закономерностями в данных, а не глубоким пониманием лежащих в их основе принципов и взаимосвязей, что препятствует эффективному переносу знаний между различными дисциплинами.
Традиционная полная донастройка больших языковых моделей (LLM) представляет собой значительную вычислительную проблему, особенно при работе с разнородными научными областями. Процесс требует огромных ресурсов для обновления всех параметров модели при адаптации к новым данным, что становится непрактичным при масштабировании на множество дисциплин. Более того, такая донастройка часто приводит к “катастрофическому забыванию” — потере ранее усвоенных знаний при обучении на новых задачах. Модель, успешно решавшая задачи из области химии, может существенно ухудшить свои результаты в биологии после донастройки на биологических данных, демонстрируя неспособность к эффективному переносу знаний и обобщению информации из различных научных сфер. Это ограничивает потенциал LLM в решении комплексных, междисциплинарных задач, требующих интеграции знаний из разных областей науки.
Для достижения надежной производительности в решении сложных научных задач, языковые модели должны обладать способностью интегрировать знания из различных, порой не связанных между собой, областей науки. Например, понимание химических процессов может быть критически важным для интерпретации биологических данных, а географические факторы — для моделирования распространения заболеваний. Современные исследования показывают, что модели, способные связывать информацию из химии, биологии, географии и других дисциплин, демонстрируют значительно более высокую точность и надежность в решении мультидисциплинарных задач, чем модели, обученные на узкоспециализированных данных. Такой подход позволяет не просто анализировать отдельные факты, но и выявлять сложные взаимосвязи и закономерности, что является ключевым для прогресса в науке и технологиях.
Современный подход к обучению больших языковых моделей сталкивается с необходимостью перехода к более эффективным и адаптируемым методологиям. Традиционные способы, такие как полная перенастройка, требуют значительных вычислительных ресурсов и часто приводят к “катастрофическому забыванию” ранее усвоенных знаний при изучении новых областей. Учитывая растущую потребность в моделях, способных интегрировать информацию из различных научных дисциплин — от химии и биологии до географии и астрономии — становится очевидной необходимость в алгоритмах, позволяющих моделям быстро адаптироваться к новым задачам и эффективно использовать накопленные знания. Разработка таких методологий позволит не только снизить вычислительные затраты, но и создать более устойчивые и универсальные системы, способные решать широкий спектр научных задач.
Параметрически-эффективное обучение: Путь к мультидисциплинарной экспертизе
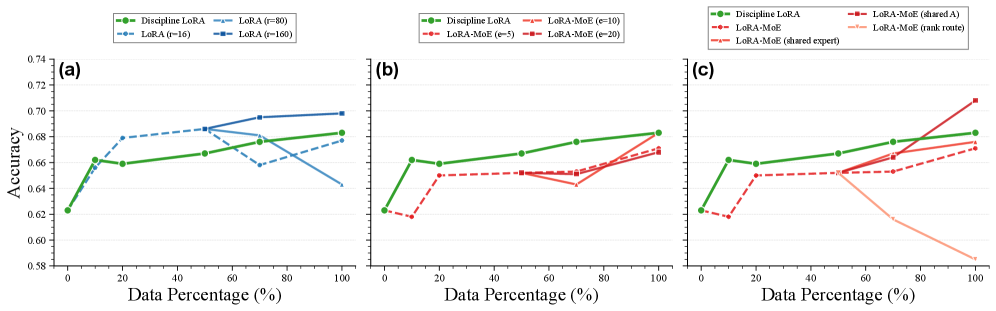
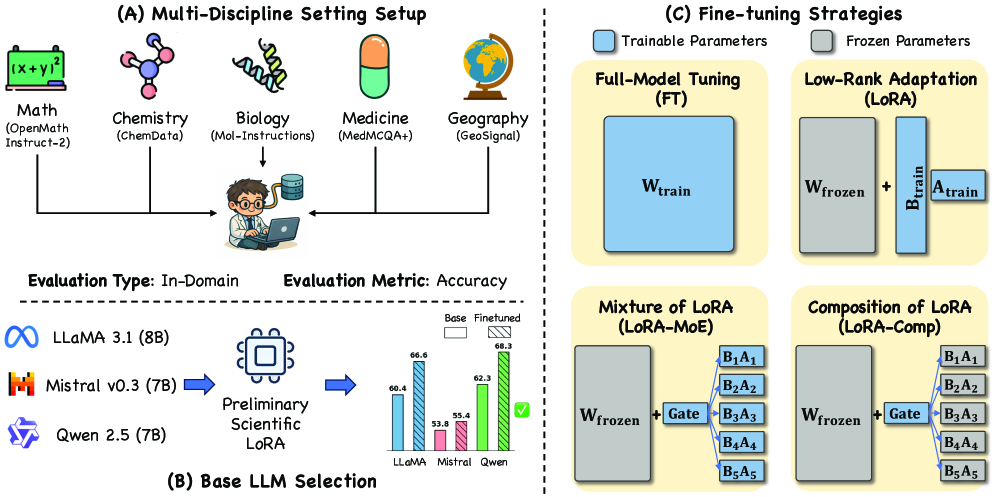
Адаптация низкого ранга (LoRA) представляет собой эффективный метод обучения, направленный на снижение вычислительных затрат и предотвращение катастрофического забывания. Вместо обновления всех параметров предобученной модели, LoRA вводит небольшое количество обучаемых параметров — низкоранговые матрицы — которые добавляются к существующим весам. Этот подход значительно уменьшает количество обновляемых параметров, обычно на порядки, что снижает потребность в памяти и вычислительных ресурсах. В процессе обучения фиксированные веса предобученной модели остаются неизменными, а оптимизируются только параметры низкоранговых матриц. Это позволяет модели адаптироваться к новым задачам, сохраняя при этом знания, полученные в процессе предварительного обучения, и снижая риск переобучения.
Комбинирование LoRA (Low-Rank Adaptation) с архитектурой Mixture-of-Experts (MoE) позволяет достичь специализации внутри каждой экспертной сети. В данной конфигурации, LoRA применяется для адаптации весов отдельных экспертов MoE, что позволяет им эффективно усваивать и обрабатывать знания из различных научных дисциплин. Каждый эксперт специализируется на определенной области знаний, а механизм маршрутизации MoE направляет входные данные к наиболее подходящему эксперту для обработки. Такой подход позволяет модели эффективно масштабировать свои знания и поддерживать высокую производительность при работе с разнообразными и сложными научными задачами, избегая необходимости полного переобучения всей модели при добавлении новых знаний.
Композиция LoRA (LoRA Composition) представляет собой метод повышения эффективности адаптации моделей путем маршрутизации информации через предварительно обученные LoRA-модули. Вместо обучения новых параметров с нуля, этот подход использует существующие LoRA-модули, специализирующиеся на конкретных задачах или областях знаний. Входящие данные направляются через эти модули, позволяя модели эффективно использовать накопленные знания и быстро адаптироваться к новым задачам без значительных вычислительных затрат. Такая архитектура способствует обмену знаниями между различными модулями и обеспечивает более эффективную передачу информации, что особенно важно при работе с разнородными научными дисциплинами.
Использование методов параметрически-эффективного обучения, таких как LoRA и LoRA-MoE, предоставляет масштабируемый и действенный подход к созданию моделей, способных к рассуждениям в различных научных дисциплинах. Экспериментальные данные демонстрируют, что модели, обученные с применением этих техник, достигают производительности, сопоставимой с производительностью моделей, прошедших полную перенастройку, при этом количество обновляемых параметров значительно сокращается — в некоторых случаях на порядки. Это снижение вычислительных затрат и требований к памяти позволяет эффективно обучать и развертывать модели, способные интегрировать и применять знания из различных областей науки, обеспечивая при этом сопоставимую точность и обобщающую способность.
Эмпирические закономерности мультидисциплинарного обучения
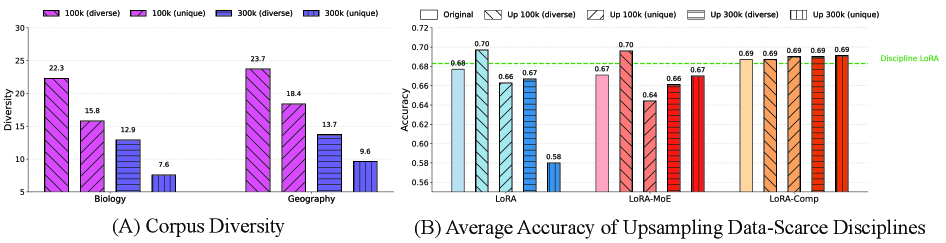
Наше исследование выявило несколько эмпирических законов, определяющих успешное мультидисциплинарное обучение, первым из которых является принцип “Сбалансированность, а затем Разнообразие”. Данный принцип подчеркивает необходимость решения проблемы дисбаланса данных между дисциплинами на начальном этапе обучения, прежде чем переходить к увеличению разнообразия данных. Недостаточное представление отдельных дисциплин в обучающей выборке может привести к предвзятости модели и снижению ее производительности. Устранение дисбаланса, посредством методов, таких как взвешивание классов или генерация синтетических данных, позволяет обеспечить адекватное представление каждой дисциплины и повысить общую эффективность обучения модели в мультидисциплинарной среде.
Принцип «Баланс, а затем Разнообразие» подчеркивает критическую важность устранения дисбаланса данных между дисциплинами на начальном этапе обучения. Недостаточное представление определенных областей знаний в обучающем наборе может привести к предвзятости модели и снижению ее эффективности в этих областях. Прежде чем стремиться к увеличению разнообразия данных, необходимо обеспечить адекватное количество примеров для каждой дисциплины, чтобы модель могла эффективно изучать и обобщать информацию из всех представленных областей. Игнорирование дисбаланса данных на ранних стадиях может существенно ограничить потенциал многодисциплинарного обучения, даже при наличии большого объема разнообразных данных.
Принцип “Объединение-затем-Выравнивание” (Merge-then-Align) показывает, что предварительное объединение данных из различных дисциплин перед обучением модели следовать инструкциям приводит к более высоким результатам. Исследования демонстрируют, что объединение данных на этапе препроцессинга позволяет модели лучше обобщать знания между областями. В отличие от подходов, где выравнивание происходит сразу после получения данных из каждой дисциплины, предварительное объединение обеспечивает более целостное представление информации и, как следствие, улучшает способность модели к решению задач, требующих междисциплинарного подхода. Этот метод позволяет достичь превосходных результатов по сравнению с последовательным обучением на отдельных наборах данных.
Принцип “Оптимизация-перед-масштабированием” подчеркивает, что перед увеличением количества параметров модели необходимо провести оптимизацию существующих параметров. Это позволяет добиться повышения эффективности обучения и предотвратить переобучение. Увеличение числа параметров без предварительной оптимизации может привести к избыточной сложности модели и снижению обобщающей способности, особенно при ограниченном объеме данных. Оптимизация включает в себя настройку гиперпараметров, регуляризацию и другие методы, направленные на улучшение производительности модели при заданном количестве параметров, после чего можно рассмотреть увеличение масштаба модели для дальнейшего повышения точности и производительности.
В ходе исследований было установлено, что соблюдение сформулированных эмпирических законов позволяет достичь производительности, сопоставимой с полной тонкой настройкой (full fine-tuning) модели, при этом используя значительно меньшее количество параметров. Экспериментальные данные демонстрируют, что предложенный подход не только обеспечивает сравнимую точность, но и существенно превосходит базовые методы обучения, что подтверждается количественными метриками, полученными в ходе тестирования на различных датасетах. Сокращение количества используемых параметров ведет к снижению вычислительных затрат и ускорению процесса обучения, делая данный подход более эффективным и масштабируемым.
Интеграция научных знаний: Широкий спектр приложений
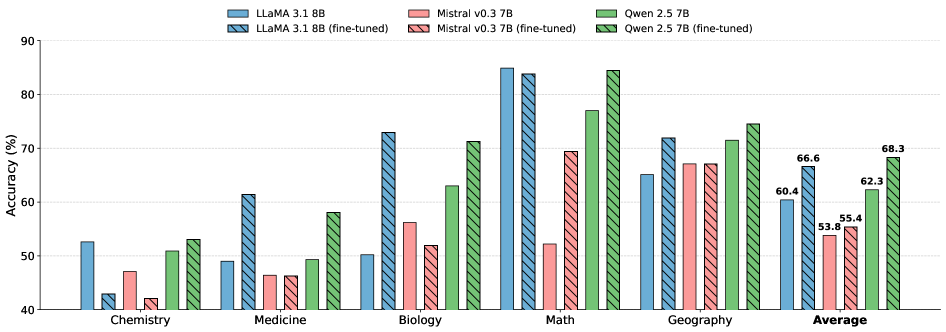
Исследования демонстрируют, что применение разработанных принципов к различным научным областям — от химии и биологии до медицины и географии — подтверждает универсальность предложенного подхода. Интеграция знаний из этих разнородных дисциплин позволяет создавать модели, способные эффективно решать задачи, требующие междисциплинарного мышления. Например, предложенные методы успешно применяются для прогнозирования химических реакций, анализа биологических процессов, постановки медицинских диагнозов и моделирования географических явлений. Это свидетельствует о том, что разработанная система не ограничена конкретной областью знаний, а способна адаптироваться и эффективно функционировать в различных научных контекстах, открывая новые возможности для решения сложных задач.
Разработанные модели демонстрируют значительное улучшение в решении задач, требующих комплексного, междисциплинарного подхода. В частности, наблюдается повышение точности в предсказании химических реакций, где необходимо учитывать не только свойства веществ, но и принципы термодинамики и кинетики. Аналогично, в области диагностики заболеваний модели способны интегрировать данные из различных источников — от симптомов и лабораторных анализов до генетической информации и медицинской истории пациента — для постановки более точного диагноза. Этот прогресс обусловлен способностью моделей не просто обрабатывать данные, но и устанавливать связи между различными областями знаний, что позволяет им делать обоснованные выводы и предсказывать результаты с большей уверенностью.
Математическое мышление является основополагающим элементом во всех научных дисциплинах, будь то химия, биология или география. Данная работа демонстрирует успешную интеграцию математических принципов со специализированными знаниями в каждой из этих областей. Разработанная система способна эффективно применять математические модели для анализа и решения задач, требующих глубокого понимания конкретной научной области. Например, при прогнозировании химических реакций или диагностике заболеваний, система использует математические инструменты для обработки и интерпретации сложных данных, значительно повышая точность и надежность результатов. E=mc^2 — этот известный пример демонстрирует фундаментальную роль математики в понимании природных явлений, и аналогичный подход реализован в предложенной архитектуре, обеспечивая мощный инструмент для научных исследований и открытий.
Разработанный интегрированный подход открывает возможности для создания искусственного интеллекта, способного решать сложные научные задачи, требующие целостного понимания предметной области. Достигнуты значительные улучшения в обобщающей способности моделей, продемонстрированные на тесте MMLU, при этом вычислительные затраты снижены до 15% от ресурсов, необходимых для полной перенастройки. Это позволяет создавать эффективные и экономичные системы, способные к адаптации и решению задач за пределами изначально заданного набора данных, что существенно расширяет потенциал применения искусственного интеллекта в научных исследованиях и прогнозировании.
Исследование закономерностей в тонкой настройке больших языковых моделей для научных дисциплин неизбежно сталкивается с вопросом о времени и эволюции системы. Как отмечает Роберт Тарьян: «Хороший алгоритм — это не тот, который работает быстро, а тот, который остается понятным и модифицируемым со временем». Представленные в работе четыре эмпирических закона — Баланс-тогда-Разнообразие, Слияние-тогда-Выравнивание, Оптимизация-тогда-Масштабирование, и Обмен-тогда-Специализация — описывают не просто шаги к улучшению производительности, но и путь системы к устойчивости и адаптивности. Подобно тому, как система со временем становится более зрелой через инциденты и исправления, так и эти принципы направляют развитие научных LLM к более надежным и обобщенным решениям. Успех в данной области зависит не только от скорости, но и от способности модели к долгосрочной эволюции.
Куда Ведет Путь?
Представленная работа, выявляя эмпирические закономерности тонкой настройки больших языковых моделей в мультидисциплинарной научной среде, лишь констатирует неизбежное — любое улучшение стареет быстрее, чем ожидалось. Законы “Баланс, а затем Разнообразие”, “Слияние, а затем Выравнивание”, “Оптимизация, а затем Масштабирование” и “Совместное Использование, а затем Специализация” — это не столько предписания, сколько описание траектории деградации, которая рано или поздно постигнет любую, даже самую совершенную, систему. Вопрос не в том, чтобы избежать этой деградации, а в том, чтобы достойно её пережить.
Очевидным ограничением является статичность самой концепции “закона”. Научные дисциплины, как и время, текучи и изменчивы. То, что работает сегодня, может оказаться неэффективным завтра. Отсюда вытекает необходимость в динамических, самоадаптирующихся алгоритмах, способных отслеживать и компенсировать неизбежные отклонения от установленных закономерностей. Откат — это не ошибка, а естественное путешествие назад по стрелке времени, и умение извлекать уроки из прошлого — вот что действительно важно.
В конечном итоге, истинным вызовом является не создание все более мощных моделей, а разработка систем, способных к долгосрочному обучению и адаптации, систем, которые не просто решают задачи, но и учатся на своих ошибках, сохраняя при этом способность к инновациям. Иначе, все усилия по улучшению искусственного интеллекта превратятся в погоню за ускользающей тенью прогресса.
Оригинал статьи: https://arxiv.org/pdf/2602.11215.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Стоит ли покупать фунты за йены сейчас или подождать?
- Серебро прогноз
- Мечел акции прогноз. Цена MTLR
- АЛРОСА акции прогноз. Цена ALRS
- Геополитика, Швейцарский Цифровой Франк и Инсайдерская Торговля: Обзор Ключевых Событий Недели (08.04.2026 13:45)
- Российский рынок: между нефтью, рублем и геополитикой: обзор ключевых трендов и перспектив (04.04.2026 01:32)
- XLP против VDC: Более низкие комиссии или более широкое покрытие?
- ЭсЭфАй акции прогноз. Цена SFIN
- Группа Аренадата акции прогноз. Цена DATA
- Стоит ли покупать доллары за новозеландские доллары сейчас или подождать?
2026-02-16 05:00