Когда языковым моделям стоит упрощать?
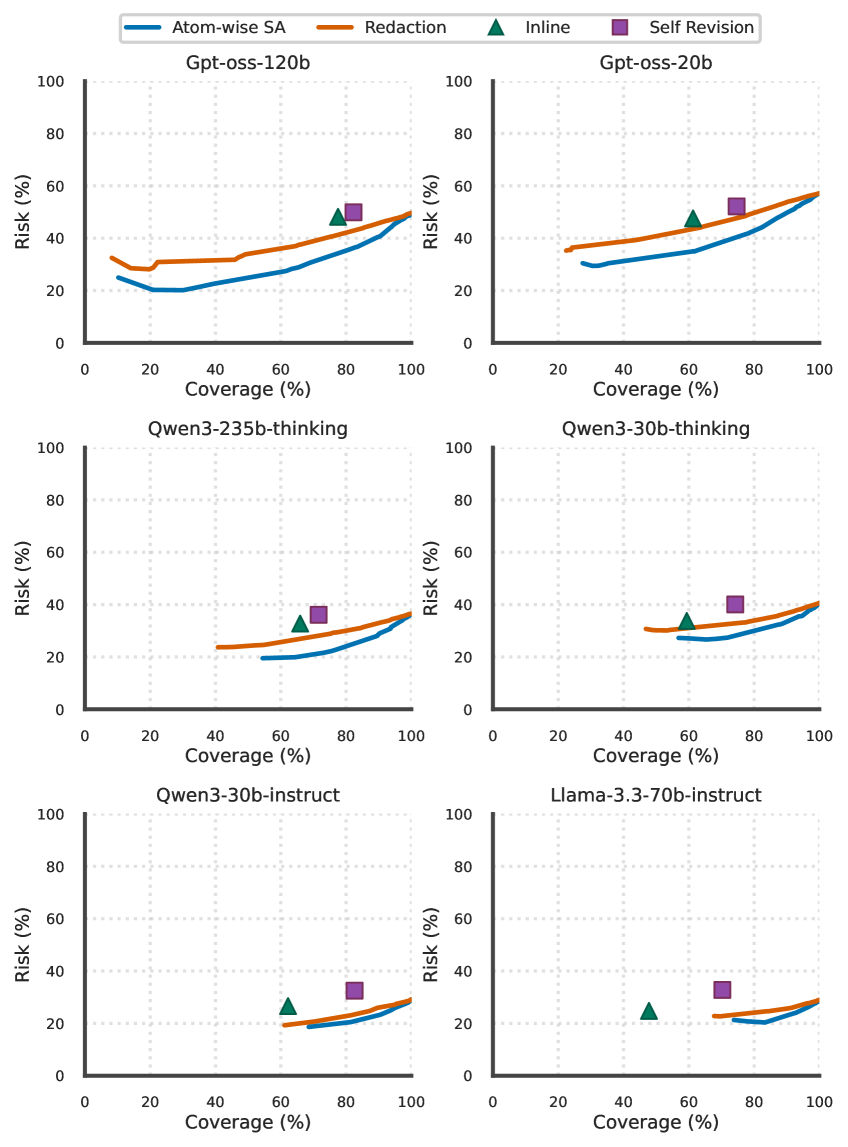
Новый подход позволяет большим языковым моделям повысить надежность длинных текстов, заменяя сомнительные утверждения на более общие, но проверенные.
Новый подход позволяет большим языковым моделям повысить надежность длинных текстов, заменяя сомнительные утверждения на более общие, но проверенные.
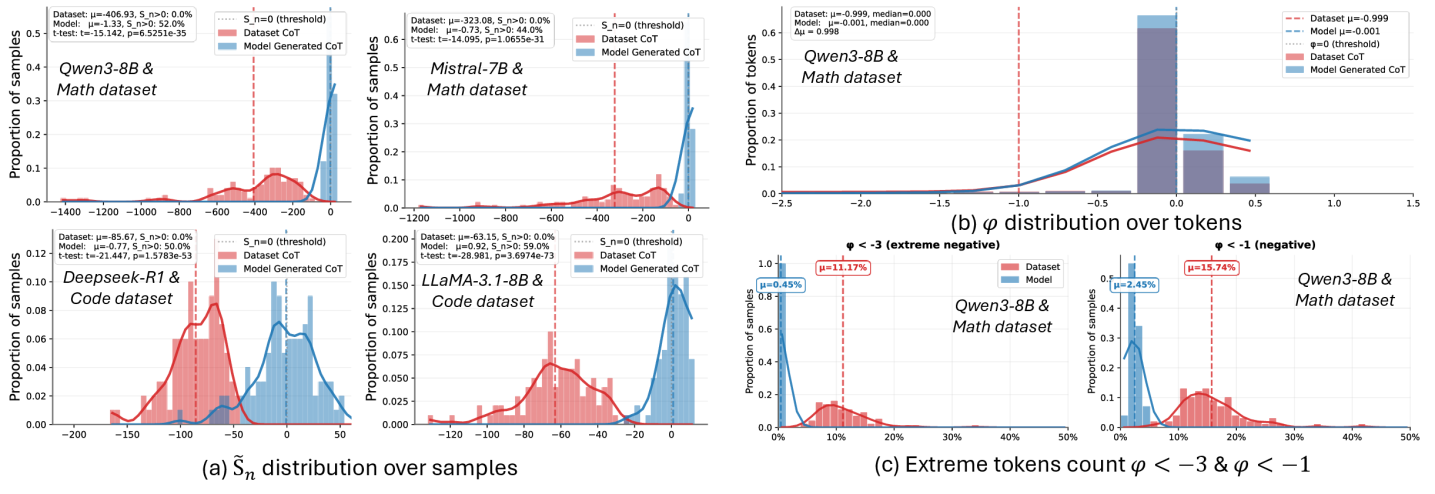
Исследование предлагает теоретическую основу для более эффективной настройки больших языковых моделей, направленную на улучшение обобщающей способности и предотвращение катастрофического забывания.
Новое исследование представляет эффективные алгоритмы для решения задач принятия решений в условиях неопределённости и сложных структур неопределённости.
![Гибридная модель, сочетающая механистический подход и анализ данных, использует двухэтапный процесс обучения: на первом этапе создаются синтетические данные на основе известной механистической модели для обучения энкодера, сопоставляющего траектории состояния и вмешательства с вектором параметров с использованием среднеквадратичной ошибки [latex]MSE[/latex], а на втором этапе, при фиксированном энкодере, обучаются корректирующие сети на исходном наборе данных, оптимизируя [latex]MSE[/latex] между наблюдаемыми и реконструированными сигналами.](https://arxiv.org/html/2602.11350v1/x1.png)
Исследователи предлагают гибридную модель, сочетающую теоретические знания и анализ данных, для более надежной оценки эффектов от различных воздействий на сложные системы.
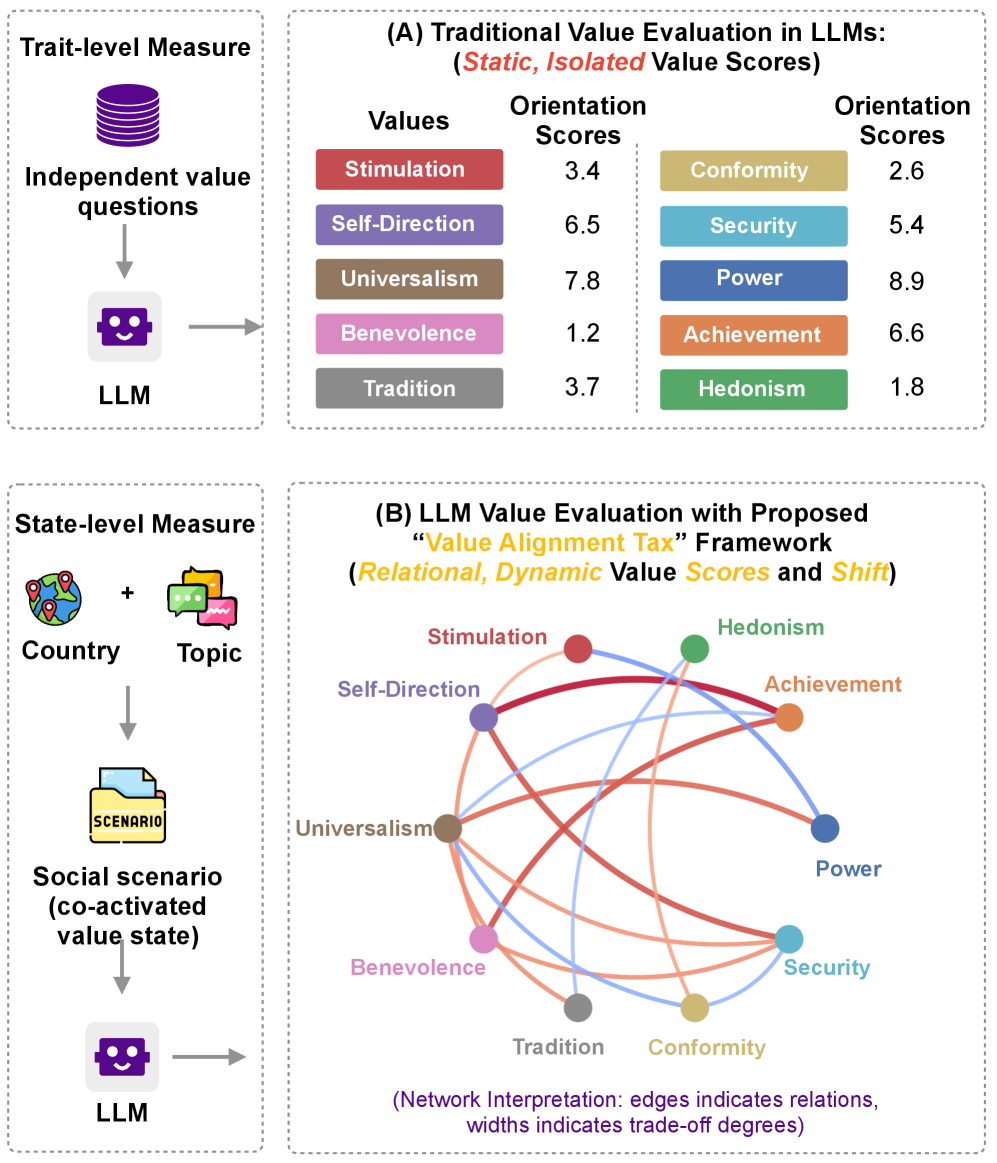
Новое исследование показывает, что попытки направить большие языковые модели в соответствии с человеческими ценностями неизбежно приводят к компромиссам и непредсказуемым последствиям.