Воздушное такси: Оптимизация маршрутов с помощью ИИ

Новая система, основанная на машинном обучении с подкреплением, позволяет значительно сократить время в пути для пассажиров воздушного транспорта, учитывая наземную и воздушную инфраструктуру.
Новая система, основанная на машинном обучении с подкреплением, позволяет значительно сократить время в пути для пассажиров воздушного транспорта, учитывая наземную и воздушную инфраструктуру.
![На основе анализа подвыборки планет, исследование демонстрирует, что оптимизация по различным критериям - размер выборки [latex]\eqref{2}[/latex], разнообразие [latex]\eqref{3}[/latex] и значимость [latex]\eqref{6}[/latex] - приводит к различным вкладам отдельных планет в общий бюджет времени TT или в значение целевой функции, выявляя сложные взаимосвязи между стратегиями отбора и их результатами.](https://arxiv.org/html/2601.21020v1/comparison_greedy_methods.png)
Новое исследование предлагает эффективную стратегию выбора экзопланет для наблюдений миссии Ariel, позволяющую максимизировать научную отдачу.
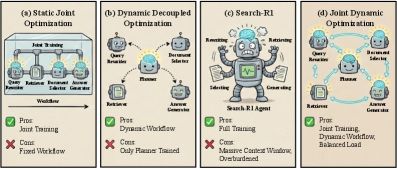
Новая архитектура JADE объединяет стратегическое планирование и оперативное исполнение в системах, основанных на больших языковых моделях, для повышения эффективности и качества поиска информации.
В статье представлена общая теоретическая база для анализа ситуаций, где игроки соревнуются, выбирая вероятностные распределения результатов, что позволяет исследовать широкий спектр экономических взаимодействий.

Новое исследование выявляет структурную причину ‘коллапса режимов’ в обучении с подкреплением и предлагает эффективный метод для восстановления разнообразия стратегий.